When it comes to word vector models, many people’s first reaction is word2vec. In fact, the family of word vectors has many interesting members that differ in style from word2vec.
At the same time, there are many improvements on top of word2vec. Here, I will briefly take you through these interesting word vector models in a short time.

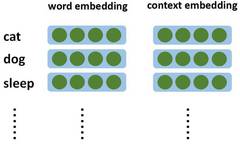
Figure 1, Parameters in word2vec and GloVe
First, let’s briefly talk about word2vec. The parameters of word2vec include word embedding and context embedding (see Figure 1).
Each word in the dictionary corresponds to a word vector and a context vector.
These vectors are initially randomly initialized. The training process of word2vec scans the corpus, making the word embedding of a word closer to the context embeddings of words in its local context. The local context generally refers to a few words on either side of the center word (see Figure 2).
This article will use “The [cat] plays ……” as an example, where “plays” is in the local context of “cat.” When the word2vec model processes the word “cat,” it finds that “plays” is a word in the local context of “cat,” and then adjusts the word embedding of “cat” and the context embedding of “plays” to make their distance closer.
Additionally, word2vec performs negative sampling.
Specifically, it randomly selects words from the dictionary. For example, if it selects “train,” it will make the word embedding of “cat” and the context embedding of “train” further apart.
We continuously select word pairs to bring them closer or further apart, ultimately obtaining high-quality word vectors.
Since “dog” and “cat” have similar contexts in the corpus, their word embeddings will be close to similar context embeddings, making the word vectors of “dog” and “cat” very close.
For unrelated words, they hardly appear in each other’s local context in the corpus; they will only be selected for negative sampling, so their word vectors will be far apart.
The source code for word2vec can be found athttps://code.google.com/archive/p/word2vec/ and there is also a cloned version on GitHub at https://github.com/svn2github/word2vec.
It is implemented in C, and I strongly recommend reading it carefully.

Figure 2, When we limit the window to 2, “Potter,” “is,” “by,” and “J.K.” are in the local context of “written.”
GloVe is another star in the word vector family. Its parameters are identical to word2vec, with each word having a word embedding and a context embedding.
GloVe first needs to establish a co-occurrence matrix for the words (see Figure 3), which counts how many times each word pair <a,b> co-occurs in each other’s local context throughout the corpus.
The goal of GloVe is to reconstruct this co-occurrence matrix using word vectors.
For example, if “plays” and “cat” co-occur 1000 times, we hope that the inner product of the word embedding of “cat” and the context embedding of “plays” is close to log(1000). Log(1000) is quite large, and the training result will make the word/context embeddings of “cat” and “plays” relatively close (roughly, a larger inner product means a smaller distance). Conversely, if “cat” and “train” co-occur 5 times, then the inner product of their word/context embeddings will be smaller (about equal to log(5)).
If their inner product exceeds this number, GloVe will make the word/context embeddings of “cat” and “train” further apart. Overall, GloVe and word2vec share a similar fundamental principle. GloVe continuously adjusts distances based on the final goal (i.e., the co-occurrence matrix), bringing them closer or further apart. The end result is that contextually similar words will have similar word vectors.
The source code for GloVe can be found at https://github.com/stanfordnlp/GloVe. This code is also in C, and compared to word2vec, it adds a step to establish the co-occurrence matrix. The rest of the code is very similar to word2vec, so if you understand the code of word2vec, GloVe’s code will be easy to grasp.

Figure 3, Illustration of the co-occurrence matrix. “cat” and “plays” co-occur 1000 times, while “cat” and “train” co-occur 5 times.
Finally, let’s discuss two particularly traditional methods. These methods predate word2vec by a long time. The first method is called PPMI. In fact, this word representation method is the most basic and classic bag-of-words representation. Since it uses words from the local context to obtain word representations, it is also called bag-of-contexts. Here, the dimensionality of the word vectors (representations) equals the number of words in the dictionary. Each word corresponds to a dimension. For example, to obtain the word vector for “cat,” we count how many times “cat” co-occurs with all other words in the local context. Suppose “cat” co-occurs with “plays” 1000 times, and “plays” corresponds to dimension 55, then the 55th dimension of the word vector for “cat” is 1000. In fact, the aforementioned bag-of-contexts is the co-occurrence matrix used by GloVe. PPMI (positive pointwise mutual information) is a weighting mechanism. The co-occurrence of “cat” and “plays” provides valuable information, while the co-occurrence information of “cat” and “the” is not valuable since “the” co-occurs with all words in large quantities. Based on this consideration, we can use PPMI to adjust the weights of some dimensions. It may be hard to believe, but such a simple and basic word representation can outperform neural network word vector models like word2vec and GloVe in certain scenarios. For example, the property like China – Beijing = Japan – Tokyo can be better captured by PPMI than by word2vec and GloVe.
With such a sparse representation like PPMI, a natural idea is to reduce its dimensionality to obtain a low-dimensional representation. SVD can be considered to decompose PPMI to obtain low-dimensional word vectors.
After introducing four word vector models, let’s discuss improvements to word vectors, especially those on word2vec. One mainstream direction of improvement is to incorporate richer contextual information. For instance, by adding dependency tree information, we can understand the relationship between context words and the center word, theoretically helping us obtain better word vectors. Additionally, by considering not only local context information but also co-occurrence information between words and documents, we can enhance the quality of word vectors or obtain different types of word vectors.
The source codes for word2vec and GloVe do not support the introduction of arbitrary forms of context very well. If you want to experiment with different contexts, you can try hyperwords (https://bitbucket.org/omerlevy/hyperwords) and ngram2vec (https://github.com/zhezhaoa/ngram2vec).
These tools support easy extensions of various contextual information, such as adding dependency tree information, document information, positional information, and more. Hyperwords includes word2vec, PPMI, and SVD. Ngram2vec builds on hyperwords and also adds GloVe.
The first toolkit is called hyperwords because it finds that hyperparameters have a significant impact on word vectors, even more than the choice of different models.
The second toolkit is called ngram2vec. Since word vector models are closely related to language models, and n-grams are one of the most important features of language models, this toolkit treats n-grams as the default feature.
Figure 4 shows the flowchart of ngram2vec (the flowchart of hyperwords is similar), illustrating the process from corpus to pairs (<cat, plays>) to center words, context dictionary, co-occurrence matrix (<<cat, plays>, 1000>), and finally to various word vectors.
Since hyperwords and ngram2vec decouple each processing step, if we want to introduce different contextual information, we only need to modify the process from corpus to pairs, and the code for the subsequent processes does not need to be changed at all.

Figure 4, Simple flowchart of ngram2vec (hyperwords), where the f after word2vec and GloVe indicates support for arbitrary contexts.
In summary, this article briefly describes four word vector models: word2vec, GloVe, PPMI, and SVD.
If you feel that the properties of existing word vectors still differ from your needs, consider introducing different information into the context to see if you can obtain satisfactory word vectors.
Author: Zhao Zhe, PhD, Renmin University of China
References
Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems. 2013: 3111-3119.
Pennington J, Socher R, Manning C. Glove: Global vectors for word representation[C]//Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014: 1532-1543.
Levy O, Goldberg Y, Dagan I. Improving distributional similarity with lessons learned from word embeddings[J]. Transactions of the Association for Computational Linguistics, 2015, 3: 211-225.
Zhao Z, Liu T, Li S, et al. Ngram2vec: Learning Improved Word Representations from Ngram Co-occurrence Statistics[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017: 244-253.
Recommended Reading:
Selected Highlights | Summary of Highlights from the Past Six Months
Highlights | Machine Learning from Scratch? Don’t Worry, Week 3 of Andrew Ng’s Course Notes! Logistic Regression and Regularization
Highlights | Machine Learning from Scratch? Don’t Worry, Week 2 of Andrew Ng’s Machine Learning Course Notes – Multiple Linear Regression
Welcome to follow our public account for learning and communication~

Welcome to join the discussion group for learning and exchange
