
Tong Ling from A Fei Temple Quantum Bit Production | WeChat Official Account QbitAI
PhD student Nathan Hubens from Télécom SudParis encountered some difficulties while training a CNN.
During experiments using the VGG16 model trained on the CIFAR10 dataset, he performed 50 iterations and found that the model did not learn anything.
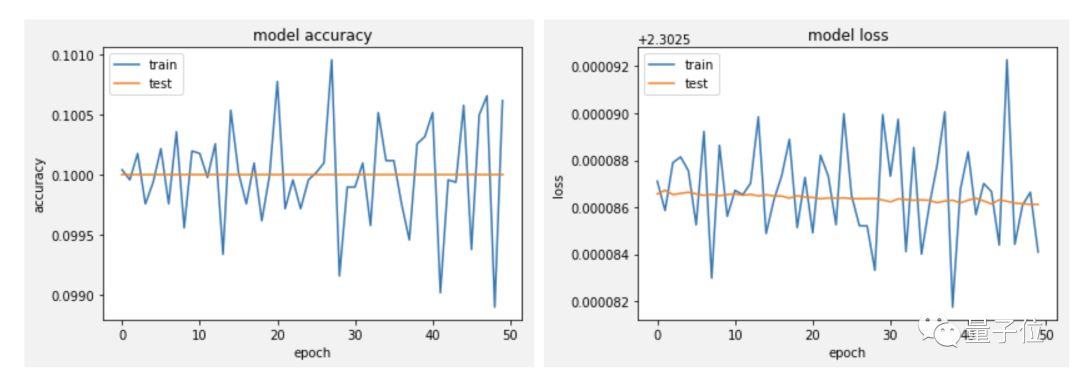
It can be seen that the model’s convergence speed is extremely slow, oscillating, and overfitting. Why is this happening?
Do you have similar doubts?
This article by the author has received thanks from netizens and inspired many researchers. Quantum Bit has summarized the key points as follows:
Experiment Itself
First, let’s look at the model creation process:
def ConvBlock(n_conv, n_out, shape, x, is_last=False):
for i in range(n_conv):
x = Conv2D(n_out, shape, padding='same', activation='relu')(x)
if is_last: out = layers.GlobalAveragePooling2D()(x)
else: out = MaxPooling2D()(x)
return out
input = Input(shape=(32, 32, 3))
x = ConvBlock(2, 64, (3,3), input)
x = ConvBlock(2, 128, (3,3), x)
x = ConvBlock(3, 256, (3,3), x)
x = ConvBlock(3, 512, (3,3), x)
x = ConvBlock(3, 512, (3,3), x, is_last=True)
x = layers.Dense(num_classes, activation='softmax')(x)This model follows the original VGG 16 architecture, but most fully connected layers have been removed, leaving almost only convolutional layers.
The initial “accident scene” may be affected by several operational steps.
When the model’s learning phase encounters problems, researchers usually check the gradient performance to obtain the mean and standard deviation of each layer in the network:
def get_weight_grad(model, data, labels):
means = []
stds = []
grads = model.optimizer.get_gradients(model.total_loss, model.trainable_weights)
symb_inputs = (model._feed_inputs + model._feed_targets + model._feed_sample_weights)
f = K.function(symb_inputs, grads)
x, y, sample_weight = model._standardize_user_data(data, labels)
output_grad = f(x + y + sample_weight)
for layer in range(len(model.layers)):
if model.layers[layer].__class__.__name__ == 'Conv2D':
means.append(output_grad[layer].mean())
stds.append(output_grad[layer].std())
return means, stdsLet’s take a look at the final statistics:
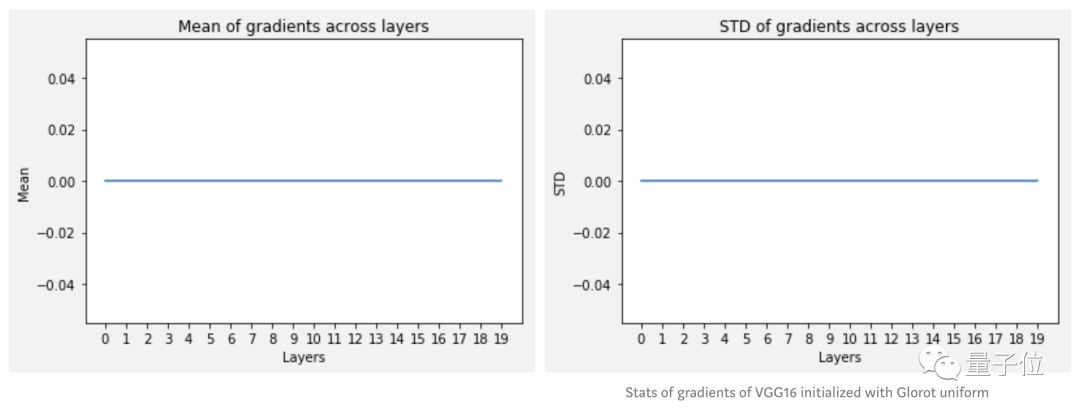
The results are somewhat unexpected, indicating that there is almost no gradient in this model. The author suggests that the activation operations along each layer should be checked.
Using the code below to obtain their mean and standard deviation again:
def get_stats(model, data):
means = []
stds = []
for layer in range(len(model.layers)):
if model.layers[layer].__class__.__name__ == 'Conv2D':
m = Model(model.input, model.layers[layer].output)
pred = m.predict(data)
means.append(pred.mean())
stds.append(pred.std())
return means, stdsThe results are different from before:
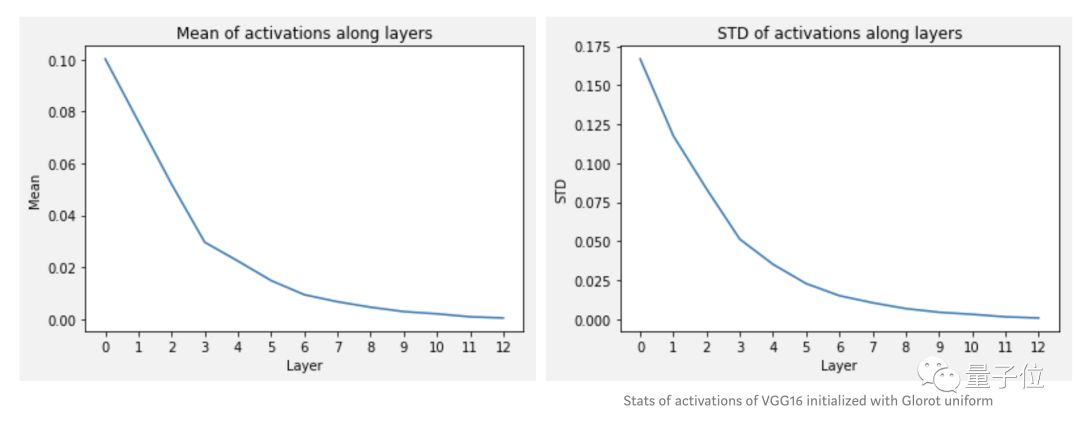
This is a step in the right direction.
In this step, the gradient calculation for each convolutional layer is as follows:
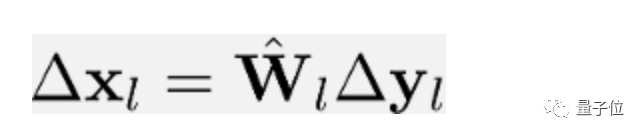
Where Δx and Δy represent ∂L/∂x and ∂L/∂y respectively. Here, the gradient is calculated using the backpropagation algorithm and the chain rule, meaning it needs to be propagated backward from the last layer to the previous layers.
If the value of the last layer’s activation function is close to 0, the gradient approaches 0 everywhere, making it impossible to backpropagate, and the network cannot learn anything.
The author believes that because his network lacks batch normalization, dropout, and data augmentation, the problem mainly lies in the initialization step.
He read He Kaiming’s previous paper Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification to see if he could resolve his doubts.

Paper link:https://arxiv.org/pdf/1502.01852.pdf
Initialization Method
Initialization has always been an important area of research in deep learning, especially with the continuous advancement of architectures and nonlinearities. A good initialization method may determine the final quality of the network.
He Kaiming’s paper shows the conditions that initialization should meet, specifically how to correctly initialize convolutional networks using the ReLU activation function. This requires a bit of mathematical background but is not difficult.
First, consider the output method of the convolutional layer l:
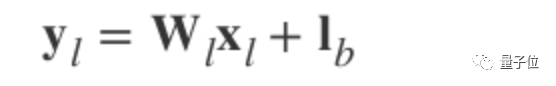
How to initialize the bias to 0, assuming that the weights w and elements x are independent and share the same distribution:
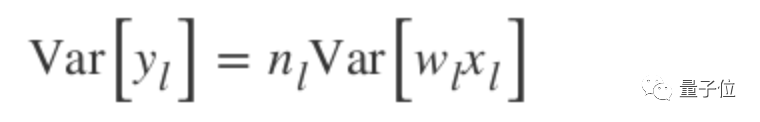
Where n is k squared multiplied by c, according to the formula for the product variance of independent variables:
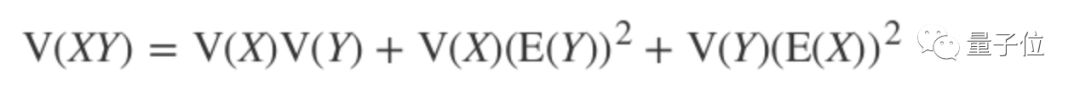
Transforming the above formula gives:
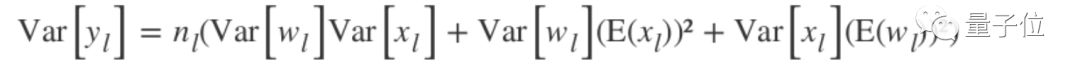
If the weights w are adjusted to make their mean 0, then the output is:
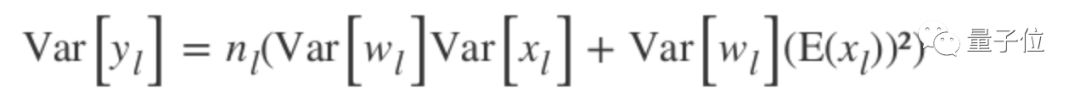
Using the König-Huygens property:
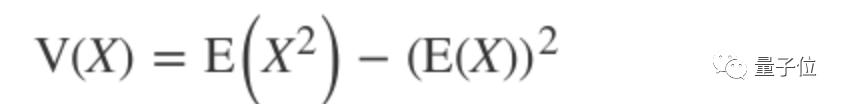
The final output is:
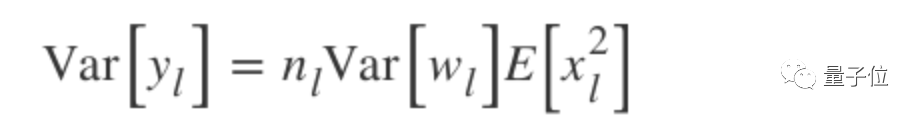
Since the ReLU activation function is used:
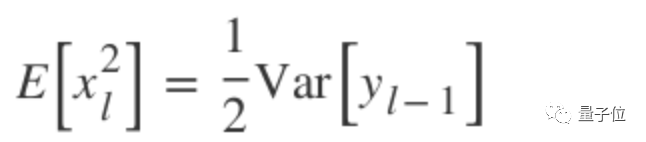
The result is:
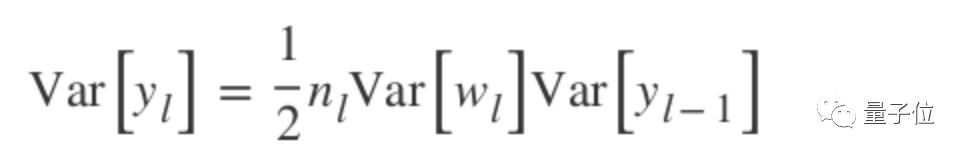
The above formula is the variance of the output of a single convolutional layer. If considering all layers in the network, the product of their variances needs to be obtained:
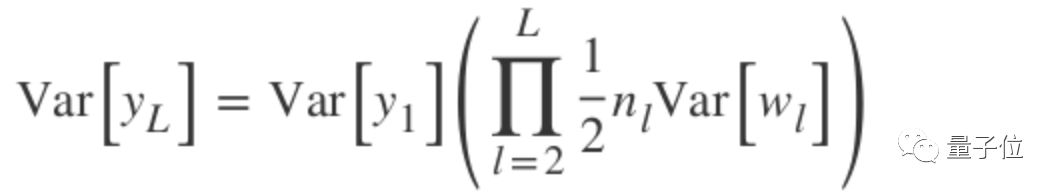
With the product, it can be seen that if the variance of each layer is not close to 1, the network will quickly decay. If less than 1, it will dissipate to 0; if greater than 1, the activation values will grow infinitely.
To have a good ReLU convolutional network, the following conditions need to be followed:
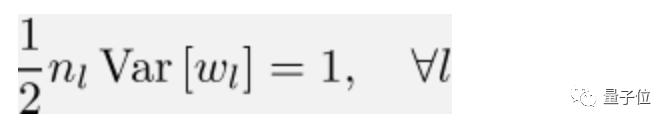
The author compared the standard initialization with his own initialization method:
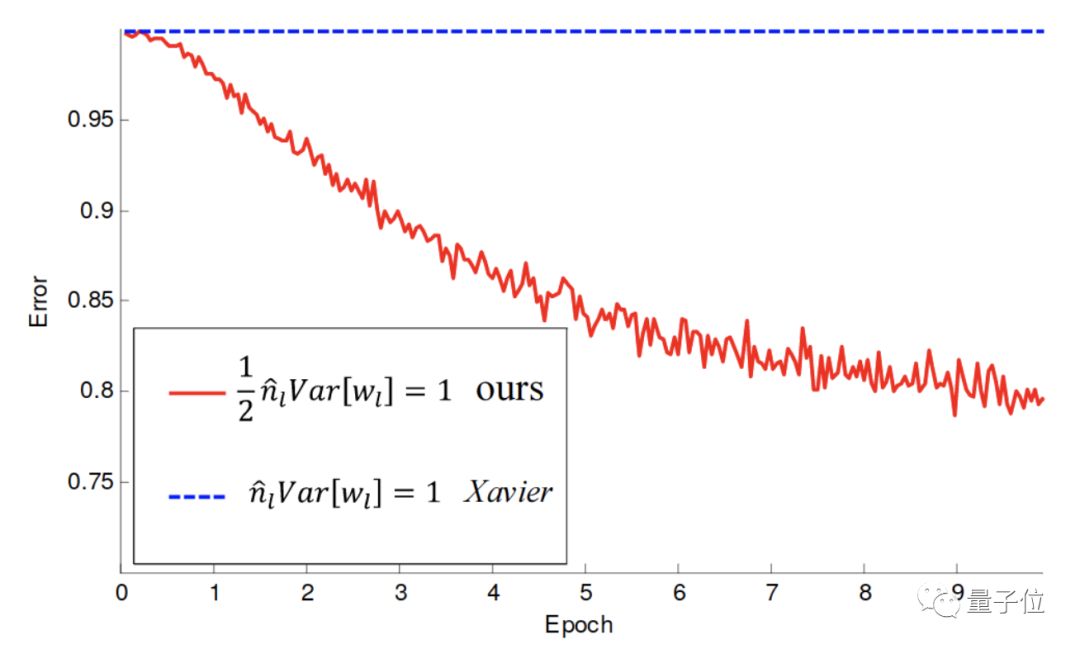
It was found that the network trained with Xavier/Glorot initialization did not learn anything.
By default, in Keras, convolutional layers are initialized using the Glorot normal distribution:
keras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid',
data_format=None, dilation_rate=(1, 1), activation=None,
use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros',
kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None,
bias_constraint=None)What will happen if this initialization method is replaced with He Kaiming’s method?
He Kaiming’s Initialization Method
First, rebuild the VGG 16 model, changing the initialization to he_uniform, and check the activations and gradients before training the model.
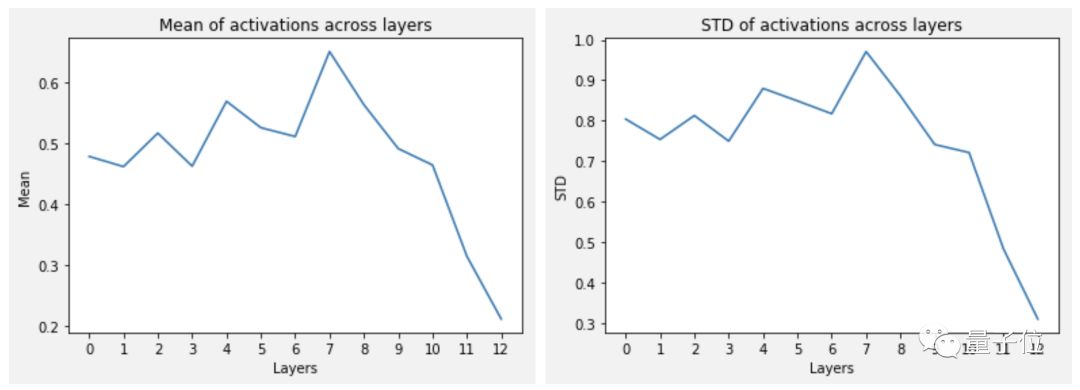
With this initialization method, the average activation is 0.5 and the standard deviation is 0.8.
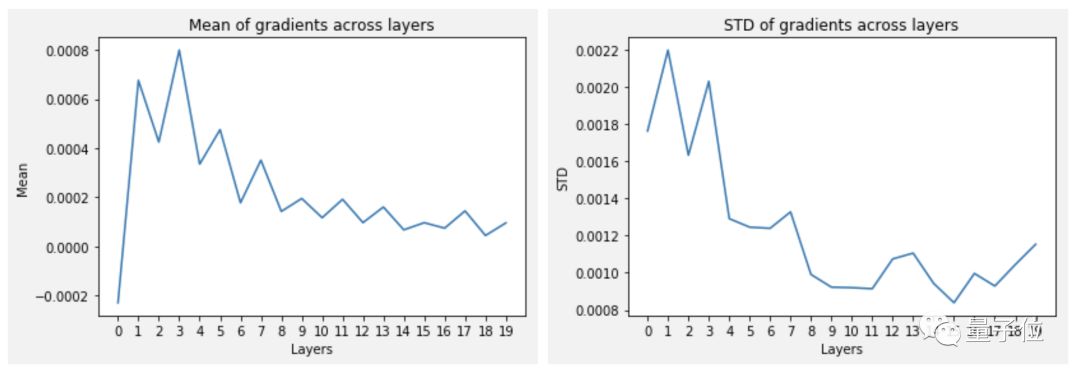
Some gradients have emerged, indicating that the network has started to work. Training a new model with this method resulted in the following curve:
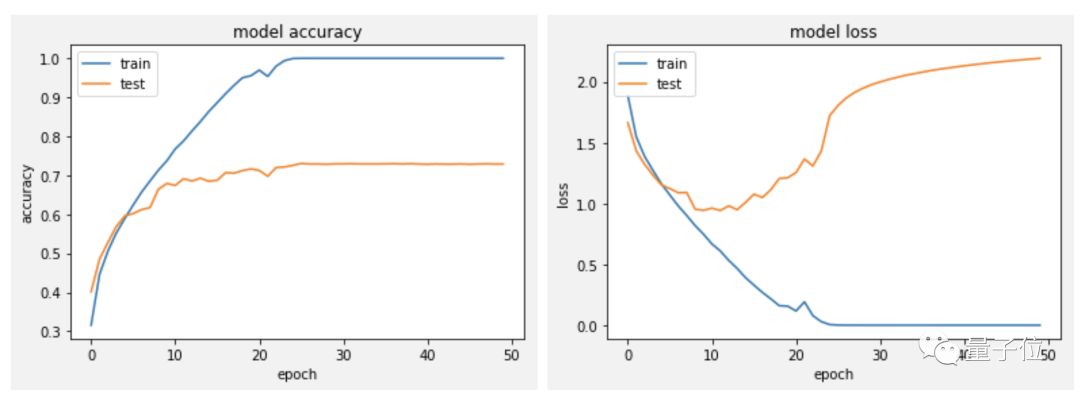
Now, the regularization issue still needs to be considered, but overall, the results are much better than before.
Conclusion
In this article, the author proves that initialization is an important part of model construction, but it is often habitually overlooked during training.
It should also be noted that even in popular and reputable machine learning libraries like Keras, the default settings cannot be used without adjustments.
Portal
Finally, here is the link to the original article:
https://towardsdatascience.com/why-default-cnn-are-broken-in-keras-and-how-to-fix-them-ce295e5e5f2
— The End —
AI Community | Communicate with Outstanding People

Mini Program | All Categories AI Learning Tutorials


Quantum Bit QbitAI · Signed Author on Toutiao
v’ᴗ’ i Follow the latest developments in AI technology and products
If you like it, click “Looking”!