In this article, we will explore how to build a powerful document summarization system using LangChain and LangGraph. This system can handle long texts by chunking, parallel processing, and recursively merging to finally generate a coherent summary.
0. Short Text Summarization
When the tokens are sufficient to accommodate the document, no document segmentation is necessary, and the summary can be generated directly.
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains.combine_documents import create_stuff_documents_chain
# Load the document
loader = WebBaseLoader("https://github.com/jobbole/awesome-python-cn/blob/master/README.md")
docs = loader.load()
# Large model
llm = ChatOpenAI(model="gpt-4o-mini")
# Define prompt
prompt = ChatPromptTemplate.from_messages(
[("system", "Write a concise summary of the following:\n\n{context}")]
)
# Create chain
chain = create_stuff_documents_chain(llm, prompt)
# Generate summary directly for docs
result = chain.invoke({"context": docs})
print(result)
# Stream output
# for token in chain.stream({"context": docs}):
# print(token, end="|")
# The README.md file for the "awesome-python-cn" repository, maintained by the "开源前哨" and "Python开发者" WeChat public account teams, provides a comprehensive list of Python resources in Chinese. It includes various tools and libraries categorized under themes such as environment management, package management, web frameworks, data visualization, machine learning, and more. Each category lists specific libraries and tools along with brief descriptions, covering a wide range of functionalities from handling HTTP requests to performing scientific calculations and creating graphical user interfaces. The project aims to facilitate the development of Python applications by providing access to valuable resources and community contributions.1. Environment Preparation and Dependency Import
When the tokens are insufficient to accommodate the document, we need to segment the document and merge the summaries. First, let’s import the required libraries and components:
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import ChatOpenAI
from langchain.chains.llm import LLMChain
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_text_splitters import CharacterTextSplitter
import asyncio
import operator
from typing import Annotated, List, Literal, TypedDict
from langchain.chains.combine_documents.reduce import (
acollapse_docs,
split_list_of_docs,
)
from langchain_core.documents import Document
from langgraph.constants import Send
from langgraph.graph import END, START, StateGraph2. Document Loading and Preprocessing
Next, we implement the loading and initial processing of the document:
# Load the document
loader = WebBaseLoader("https://github.com/jobbole/awesome-python-cn/blob/master/README.md")
docs = loader.load()
# Use tiktoken encoder for document segmentation
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
split_docs = text_splitter.split_documents(docs)
# Initialize large language model
llm = ChatOpenAI(model="gpt-4o-mini")This code implements the document loading and preprocessing process. The setting chunk_overlap=0 means there is no overlap between our text chunks. This choice is made to improve processing efficiency and avoid duplicate processing of the same content. In some special scenarios, if it is necessary to maintain the continuity of context, we can set an appropriate overlap value.
3. Building the Summary Chain
Now, let’s build the processing chain for generating summaries:
# Single document summary chain
map_prompt = ChatPromptTemplate.from_messages(
[("system", "Write a concise summary of the following:\n\n{context}")]
)
map_chain = map_prompt | llm | StrOutputParser()
# Summary merging chain
reduce_template = """
The following is a set of summaries:
{docs}
Take these and distill it into a final, consolidated summary
of the main themes.
"""
reduce_prompt = ChatPromptTemplate([("human", reduce_template)])
reduce_chain = reduce_prompt | llm | StrOutputParser()In this code, we have built two key processing chains: map_chain and reduce_chain. This design adopts the Map-Reduce pattern, which is a powerful distributed processing paradigm, especially suitable for handling large-scale data.
-
• map_chain is responsible for generating summaries for individual document chunks. -
• reduce_chain is responsible for merging multiple summaries into a coherent whole.
4. State Management and Utility Functions
Next, we define the state management and auxiliary functions for the system:
# Set maximum token limit
token_max = 1000
def length_function(documents: List[Document]) -> int:
"""Calculate the total number of tokens for the input document list"""
return sum(llm.get_num_tokens(doc.page_content) for doc in documents)
# Define state types
class OverallState(TypedDict):
contents: List[str]
summaries: Annotated[list, operator.add]
collapsed_summaries: List[Document]
final_summary: str
class SummaryState(TypedDict):
content: strThe OverallState class defines the overall state of the system, containing four key fields:
-
• contents: stores the original document content -
• summaries: stores the generated summaries, using the operator.add annotation to support summary merging operations -
• collapsed_summaries: stores the merged summary documents -
• final_summary: stores the final generated summary
5. Core Processing Functions
Each processing function has its specific responsibilities and optimization strategies:
async def generate_summary(state: SummaryState):
"""Generate summary for a single document chunk"""
response = await map_chain.ainvoke(state["content"])
return {"summaries": [response]}
def map_summaries(state: OverallState):
"""Map document contents to summary generation nodes"""
return [
Send("generate_summary", {"content": content})
for content in state["contents"]
]
def collect_summaries(state: OverallState):
"""Collect generated summaries"""
return {
"collapsed_summaries": [Document(summary) for summary in state["summaries"]]
}
async def collapse_summaries(state: OverallState):
"""Merge summaries"""
doc_lists = split_list_of_docs(
state["collapsed_summaries"], length_function, token_max
)
results = []
for doc_list in doc_lists:
results.append(await acollapse_docs(doc_list, reduce_chain.ainvoke))
return {"collapsed_summaries": results}
def should_collapse(state: OverallState) -> Literal["collapse_summaries", "generate_final_summary"]:
"""Determine whether to continue merging summaries"""
num_tokens = length_function(state["collapsed_summaries"])
return "collapse_summaries" if num_tokens > token_max else "generate_final_summary"
async def generate_final_summary(state: OverallState):
"""Generate the final summary"""
response = await reduce_chain.ainvoke(state["collapsed_summaries"])
return {"final_summary": response}This code defines the core processing functions of the system, each with its specific responsibilities and optimization strategies. generate_summary is responsible for generating the summary of a single document chunk, map_summaries maps document contents to summary generation nodes, collect_summaries collects generated summaries, collapse_summaries merges summaries, should_collapse determines whether to continue merging summaries, and generate_final_summary generates the final summary.
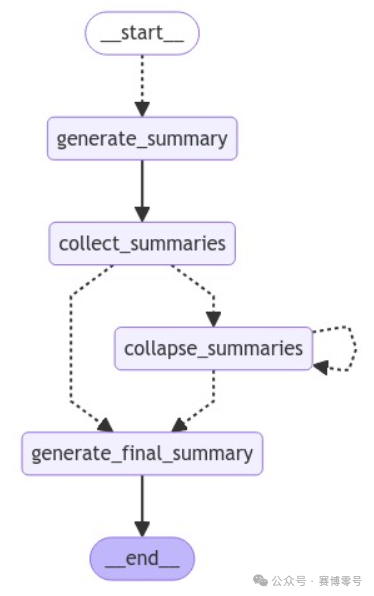
6. Building the Processing Graph
# Create state graph
graph = StateGraph(OverallState)
# Add nodes
graph.add_node("generate_summary", generate_summary)
graph.add_node("collect_summaries", collect_summaries)
graph.add_node("collapse_summaries", collapse_summaries)
graph.add_node("generate_final_summary", generate_final_summary)
# Add edges and conditions
graph.add_conditional_edges(START, map_summaries, ["generate_summary"])
graph.add_edge("generate_summary", "collect_summaries")
graph.add_conditional_edges("collect_summaries", should_collapse)
graph.add_conditional_edges("collapse_summaries", should_collapse)
graph.add_edge("generate_final_summary", END)
# Compile graph
app = graph.compile()In this code, we use LangGraph to build a state graph based on OverallState to manage the entire summarization process.
During the node addition phase, we define four key nodes:
-
1. The generate_summary node receives document content as input and outputs the corresponding summary. -
2. The collect_summaries node integrates multiple concurrently generated summaries. -
3. The collapse_summaries node implements the logic for merging summaries. When the total length of the summaries exceeds the threshold, this node merges multiple summaries. -
4. The generate_final_summary node consolidates all processed summaries into a coherent final summary.
The configuration of edges is the most complex part of the graph structure. We use two types of edges:
-
• Normal edges (add_edge): used to represent a deterministic processing flow, such as the transition from generate_summary to collect_summaries. -
• Conditional edges (add_conditional_edges): used to implement dynamic processing flows. There are two key conditional edges in the system:
-
1. The transition from collect_summaries to subsequent nodes: This conditional edge is based on the judgment result of the should_collapse function to decide the next operation. If the total number of tokens of the currently collected summaries exceeds token_max (1000), the system will choose the collapse_summaries path for merging processing; otherwise, it will choose the generate_final_summary path to directly generate the final summary. -
2. The transition from collapse_summaries to subsequent nodes: This conditional edge also uses the should_collapse function for judgment. After merging, the system will check the number of tokens again to determine whether to continue merging or generate the final summary. This loop check ensures that the final summary always remains within a manageable size range.
It is particularly noteworthy how the starting point (START) and endpoint (END) are handled:
-
• The START node connects to the generate_summary node through the map_summaries function, implementing the mapping from the initial document content to the summarization task. -
• The END node marks the completion of the processing flow, and it can only be reached from the generate_final_summary node, ensuring the integrity of the processing flow.
7. Running the System
Key features of the system during operation:
async def main():
async for step in app.astream(
{"contents": [doc.page_content for doc in split_docs]},
{"recursion_limit": 10},
):
print(list(step.keys()))
print(step)
asyncio.run(main())This code runs the system, showcasing its key features. The system employs asynchronous stream processing, supporting real-time state monitoring and recursive control. The performance optimizations of the system consider parallel processing strategies, memory management optimizations, and state tracking mechanisms.
8. Output
Created a chunk of size 1254, which is longer than the specified 1000
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['generate_summary']
['collect_summaries']
['collapse_summaries']
['collapse_summaries']
['collapse_summaries']
['collapse_summaries']
['collapse_summaries']
['collapse_summaries']
['generate_final_summary']
{'generate_final_summary': {'final_summary': '### Consolidated Summary of Python Resources and Libraries\n\nThe Python ecosystem offers a diverse range of resources, libraries, and frameworks that cater to various programming needs, highlighting its versatility and extensive functionality:\n\n1. **Web Development**: Frameworks like Django and Flask, along with libraries such as BeautifulSoup, support web applications and web scraping.\n\n2. **Data Handling and Processing**: Libraries like pandas, NumPy, and Dask facilitate efficient data manipulation and processing, while tools like PySpark and Ray enhance data analysis capabilities. \n\n3. **Scientific Computing and Machine Learning**: Essential libraries for data analysis include SciPy and visualization tools such as matplotlib and Plotly, complemented by machine learning frameworks like TensorFlow and PyTorch.\n\n4. **Asynchronous Programming and Task Automation**: Libraries such as asyncio, Celery, and APScheduler improve application responsiveness and workflow management.\n\n5. **Development Tools and Quality Assurance**: Tools like Jupyter Notebook, Flake8, and pytest focus on improving code quality, testing, and maintenance.\n\n6. **Environment and Package Management**: Tools like pip and conda streamline the management of packages and development environments.\n\n7. **Security and Data Integrity**: Libraries like cryptography ensure secure data handling and management.\n\n8. **Cloud Integration and DevOps**: Tools such as boto3 and Ansible facilitate integration with cloud services and infrastructure management.\n\n9. **Gaming and GUI Development**: Frameworks like Pygame and libraries like Tkinter offer options for game and graphical user interface development.\n\n10. **Networking, API Development, and Specialized Applications**: Libraries like Mininet and scapy support networking tasks, while tools like Graphene assist with API development, catering to specialized areas such as robotics and finance.\n\n11. **Documentation and Community Engagement**: Tools like Sphinx and curated tutorials foster community contributions and project documentation.\n\nThis summary underscores the comprehensive and open-source nature of the Python toolkit, emphasizing its broad applicability across various domains and industries.'}}9. Conclusion
This document summarization system demonstrates how to combine modern AI technology with excellent software engineering practices. Through a reasonable architectural design, the system achieves efficient parallel processing, intelligent resource allocation, and reliable error handling. The system not only addresses the specific needs of long document summarization but also provides a practical reference example for building similar AI processing systems.
10. Complete Code
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import ChatOpenAI
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.llm import LLMChain
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_text_splitters import CharacterTextSplitter
import asyncio
import operator
from typing import Annotated, List, Literal, TypedDict
from langchain.chains.combine_documents.reduce import (
acollapse_docs,
split_list_of_docs,
)
from langchain_core.documents import Document
from langgraph.constants import Send
from langgraph.graph import END, START, StateGraph
# Load the document
loader = WebBaseLoader("https://github.com/jobbole/awesome-python-cn/blob/master/README.md")
docs = loader.load()
# Segment the document
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=0
)
split_docs = text_splitter.split_documents(docs)
# Large model
llm = ChatOpenAI(model="gpt-4o-mini")
# 2 Long Text Summary
# Generate a summary chain
map_prompt = ChatPromptTemplate.from_messages(
[("system", "Write a concise summary of the following:\n\n{context}")]
)
map_chain = map_prompt | llm | StrOutputParser()
# Chain for merging multiple summaries
reduce_template = """
The following is a set of summaries:
{docs}
Take these and distill it into a final, consolidated summary
of the main themes.
"""
reduce_prompt = ChatPromptTemplate([("human", reduce_template)])
reduce_chain = reduce_prompt | llm | StrOutputParser()
# Set maximum tokens
token_max = 1000
# Calculate the total number of tokens for the input document list
def length_function(documents: List[Document]) -> int:
"""Get number of tokens for input contents."""
return sum(llm.get_num_tokens(doc.page_content) for doc in documents)
# Overall state of the graph: contains input document contents, corresponding summaries, merged summaries, and final summary.
class OverallState(TypedDict):
# Using operator.add to merge all generated summaries from various nodes back into a list
contents: List[str]
summaries: Annotated[list, operator.add]
collapsed_summaries: List[Document]
final_summary: str
# State of the nodes: state for generating summaries
class SummaryState(TypedDict):
content: str
# Generate summaries
async def generate_summary(state: SummaryState):
response = await map_chain.ainvoke(state["content"])
return {"summaries": [response]}
# Map the contents of the input documents to summary generation nodes
def map_summaries(state: OverallState):
# Each Send object consists of the name of the node in the graph and the state to be sent to that node
return [
Send("generate_summary", {"content": content}) for content in state["contents"]
]
# Collect summaries
def collect_summaries(state: OverallState):
return {
"collapsed_summaries": [Document(summary) for summary in state["summaries"]]
}
# Merge summaries
async def collapse_summaries(state: OverallState):
doc_lists = split_list_of_docs(
state["collapsed_summaries"], length_function, token_max
)
results = []
for doc_list in doc_lists:
results.append(await acollapse_docs(doc_list, reduce_chain.ainvoke))
return {"collapsed_summaries": results}
# Determine whether to merge summaries
def should_collapse(
state: OverallState,
) -> Literal["collapse_summaries", "generate_final_summary"]:
num_tokens = length_function(state["collapsed_summaries"])
if num_tokens > token_max:
return "collapse_summaries"
else:
return "generate_final_summary"
# Generate final summary
async def generate_final_summary(state: OverallState):
response = await reduce_chain.ainvoke(state["collapsed_summaries"])
return {"final_summary": response}
# Build the graph
# Nodes:
graph = StateGraph(OverallState)
graph.add_node("generate_summary", generate_summary)
graph.add_node("collect_summaries", collect_summaries)
graph.add_node("collapse_summaries", collapse_summaries)
graph.add_node("generate_final_summary", generate_final_summary)
# Edges:
# When the state graph starts from the START node, it calls the map_summaries function.
# If map_summaries returns a valid Send object, the state graph continues to transition to the generate_summary node,
# executing the summary generation operation.
graph.add_conditional_edges(START, map_summaries, ["generate_summary"])
graph.add_edge("generate_summary", "collect_summaries")
graph.add_conditional_edges("collect_summaries", should_collapse)
graph.add_conditional_edges("collapse_summaries", should_collapse)
graph.add_edge("generate_final_summary", END)
app = graph.compile()
# from IPython.display import Image
# Image(app.get_graph().draw_mermaid_png())
async def main():
async for step in app.astream(
{"contents": [doc.page_content for doc in split_docs]},
{"recursion_limit": 10},
):
print(list(step.keys()))
print(step)
asyncio.run(main())
Recommended Reading
-
FastAPI Introduction Series Collection
-
Django Introduction Series Collection
-
Flask Tutorial Series Collection
-
tkinter Tutorial Series Collection
-
Flet Tutorial Series Collection
Please open in WeChat client