
The early development of CNNs drew a lot of inspiration from the brain’s neural networks, and now some ideas and methods in related research are helping neuroscience, such as DeepMind’s recent work using AI to explore brain navigation and dopamine functions. Recently, Grace Lindsay, a PhD in Neurobiology and Behavior from Columbia University, published a blog post discussing the differences and connections between CNNs and biological visual systems in a Q&A format.
Like most of my recent blog posts, the motivation for writing this article came from a recent Twitter discussion, specifically about how to relate the components of deep convolutional neural networks (CNNs) to the brain. However, most of the thoughts here are ones I have considered and discussed before. When someone uses CNNs as a model for the visual system, I usually (in research discussions and other conversations) have to encourage and support that choice. Part of the reason is that they are relatively new methods in the field of neuroscience, and part is due to skepticism about them. Computational models generally develop slowly in neuroscience, largely (but not entirely) from those who do not use or build computational models; they are often described as impractical or useless. In the atmosphere of general disdain for tech enthusiasts and the excessive hype surrounding deep learning/AI (how much is it worth?), no matter what model you get, some people will hate it.
So here I hope to use a simple (but lengthy) Q&A format to reasonably and accurately explain the use of CNNs to model biological visual systems. This subfield is largely still in development, so there won’t be too many indisputable facts in the text, but I will quote as much as possible. Additionally, these are obviously my personal answers to these questions (and the questions I posed), so please trust what is trustworthy among them.
I focus on CNNs as models of visual systems—not broader questions like “Can deep learning help us understand the brain?”—because I believe this area is relatively the most reasonable, informative, and productive (and it is also my area of research). However, this general process (specifying an architecture based on biological information and then training it on relevant data) can also be used to help understand and replicate other brain regions and functions. Of course, some have done this; see: https://www.frontiersin.org/articles/10.3389/fncom.2016.00094/full
(I hope that readers from the machine learning and data science fields can understand this article, but there are indeed some neuroscience terms that are not defined.)
1. What is CNN?
A convolutional neural network (CNN) is a type of artificial neural network. Thus, they are composed of units called “neurons,” which output an activity level based on the weighted sum of the inputs. This activity level is usually a nonlinear function of the inputs, often just a rectified linear unit (ReLU), where the activity equals the input when all inputs are positive and equals 0 when all inputs are non-positive.
The uniqueness of CNNs lies in the construction of connections between neurons. In a feedforward neural network, units are organized in layers, with units in a given layer only receiving input from the layer below (i.e., there are typically no inputs from other units in the same layer or subsequent layers, and most of the time no inputs from more than one layer back). CNNs are feedforward networks. However, unlike standard simple feedforward networks, the units in CNNs have a spatial arrangement. In each layer, units are organized into a 2D grid, known as a feature map. Each feature map is the result of applying a convolution over the layer below it (hence the name CNN). This means that the same convolution filter (set of weights) is applied at each position in the layer below. Thus, a unit at a specific position in the 2D grid can only receive input from units at similar positions in the layer below. Additionally, the weights attached to the inputs are the same for each unit in a feature map (though different feature maps have different weights).
After convolution (and nonlinearity), some other calculations are usually performed. One possible calculation is cross-feature normalization (though this method is no longer popular in modern high-performance CNNs). Here, the activity of a unit at a specific spatial location in a feature map is divided by the activity of units at the same location in other feature maps. A more common operation is pooling, where the maximum activity from a small spatial region in each 2D feature map is used to represent that region. This reduces the size of the feature maps. This set of operations (convolution + nonlinearity → normalization → pooling) is collectively referred to as a layer. A network architecture is defined by the number of layers and the selection of various related parameters (such as the size of the convolution filters).
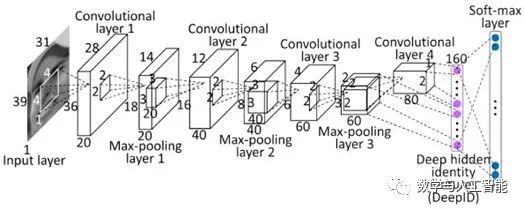
Most modern CNNs have multiple (at least 5) such layers, with the last layer feeding data into a fully connected layer. A fully connected layer is like a standard feedforward network, with no spatial layout or restricted connections. Typically, there are 2-3 fully connected layers used in succession, and the final layer of the network performs classification. For example, if the network is performing 10-class object classification, the last layer will have 10 units, with a softmax operation applied to their activity levels to obtain the probabilities associated with each class.
These networks are primarily trained through supervised learning and backpropagation. At this point, the inputs provided to the network are pairs consisting of images and their associated class labels. The pixel values of the images enter the first layer of the network, and then the last layer of the network produces a predicted class. If the predicted label is inconsistent with the provided label, then a gradient is computed to determine how to modify the weights (i.e., the values in the convolution filters) to make the classification correct. This process is repeated many times (many networks are trained on the ImageNet database, which contains over 1 million images across 1000 object categories), resulting in models that achieve high accuracy on held-out test images. Some variants of CNN models now achieve error rates as low as 4.94%, outperforming human levels. To achieve good performance, many training “tricks” are often required, such as intelligent learning rate selection and weight regularization (mainly through dropout, which randomly shuts off half of the weights at each training stage).
Historically, unsupervised pre-training was used to initialize weights, followed by supervised learning for improvement. However, this no longer seems necessary for superior performance.
For an introduction to deep CNNs that neuroscientists can understand, see “Deep Neural Networks: A New Framework for Modeling Biological Vision and Brain Information Processing”: https://www.annualreviews.org/doi/10.1146/annurev-vision-082114-035447
2. Have CNNs Ever Been Inspired by the Visual System?
Yes. Firstly, the name itself indicates that artificial neural networks are inspired by neurobiology, which began developing in the mid-20th century. Artificial neurons were designed to simulate the basic properties of how neurons receive and transform information.
Secondly, the main functions and computations performed by convolutional networks are inspired by early discoveries about the visual system. In 1962, Hubel and Wiesel discovered that neurons in the primary visual cortex respond to specific simple features in the visual environment (especially oriented edges). They also noted two different types of cells: simple cells (which respond most strongly at very specific spatial locations to their preferred direction) and complex cells (which have greater spatial invariance in their responses). They concluded that complex cells achieve this invariance by pooling inputs from multiple simple cells (each with a different preferred position). These two features (selectivity for specific features and increased spatial invariance through feedforward connections) form the basis for artificial visual systems like CNNs.
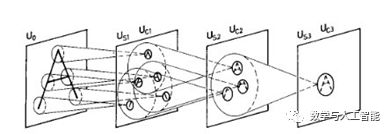
Neocognitron
The development of CNNs can be directly traced back to a model called the neocognitron. The neocognitron was developed by Kunihiko Fukushima in 1980, integrating knowledge about biological vision at the time to build a functioning artificial vision system. The neocognitron consists of “S cells” and “C cells” and can learn to recognize simple images through unsupervised learning. Yann LeCun, the AI researcher who first developed CNNs, explicitly stated that their development was based on the neocognitron; see: https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf
3. When Did CNNs Start to Become Popular?
Throughout the history of computer vision, much research has focused on artificially designing features to be detected in images, based on people’s views of the most informative parts of the images. After filtering through these manually designed features, learning would only occur in the final stages to map the features to target categories. CNNs, trained end-to-end through supervised learning, provide an automatic way to generate these features, which is the most suitable method for this task.
The earliest major example in this regard appeared in 1989, when LeCun et al. trained a small CNN using backpropagation to recognize handwritten digits. With the introduction of the MNIST dataset in 1999, the capabilities of CNNs were further developed and validated. Despite this success, the approach fell out of favor as the research community believed that such training was difficult, leading to a surge in non-neural network methods (such as support vector machines).
The next major event did not occur until 2012, when a deep CNN trained entirely through supervised methods won that year’s ImageNet competition. At that time, the excellent error rate for 1000-class object classification was about 25%, but AlexNet achieved a 16% error rate, representing a significant advancement. The winning methods prior to this challenge relied on older techniques such as shallow networks and SVMs. The advances in CNNs were due to the use of some entirely new techniques, such as ReLU (instead of sigmoid or hyperbolic tangent nonlinearities), distributing the network across 2 GPUs, and dropout regularization. However, this was not a sudden emergence; the revival of neural networks began as early as 2006. However, most of these networks used unsupervised pre-training. The advancements in 2012 undoubtedly mark a pivotal moment in the explosion of modern deep learning.
See “Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review”: https://www.mitpressjournals.org/doi/abs/10.1162/neco_a_00990
4. When Did the Current Connection Between CNNs and the Visual System Appear?
Much of the current enthusiasm in neuroscience for CNNs stems from a handful of studies published around 2014. These studies explicitly compared the neural activity recorded from humans and macaques when viewing the same images to the artificial activity in CNNs.
The first was Yamins et al. (2014). This study explored many different CNN architectures to determine what led to the excellent ability to predict the responses of monkey IT cells. For a given network, a subset of the data was used to train a linear regression model that maps the activity in the artificial network to the activity of a single IT cell. The predictive ability on held-out data was used to evaluate the model. Another method used was representational similarity analysis, which does not involve direct prediction of neural activity but rather asks whether two systems can represent information in the same way. This is achieved by constructing a matrix for each system, where the values represent the similarity of responses to two different inputs. If these matrices look the same across different systems, then they represent information in a similar way.
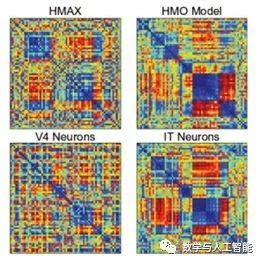
Representational Dissimilarity Matrix of Different Systems
Through these two measures, the performance of CNNs optimized for object recognition surpassed that of other methods. Additionally, the third layer of the network was better at predicting V4 cell activity, while the fourth layer (the last layer) was better at predicting IT cell activity. This indicates a correspondence between model layers and brain regions.
Another finding was that networks that performed better on object recognition also performed better at capturing IT activity without needing to be directly optimized on IT data. This trend generally held across larger and better networks until certain limitations were encountered (see Question 11).
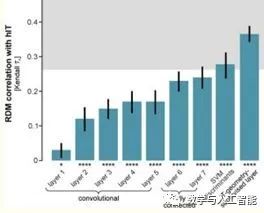
The Later Layers of CNNs Have Representations More Similar to Human IT
Another paper, Khaligh-Razavi and Kriegeskorte (2014), also used representational similarity analysis and compared 37 different models with human and monkey IT. They also found that models that excelled at object recognition also matched IT representations better. Furthermore, deep CNNs trained through supervised learning (like AlexNet) performed the best and matched most closely, with the performance of the later layers of the network being better than that of the earlier layers.
5. Have Neuroscientists Used Similar Methods to CNNs in the Past?
Yes! The neocognitron mentioned in Question 2 was inspired by the findings of Hubel and Wiesel and subsequently inspired modern CNNs, but it also gave rise to some branches of research in the field of visual neuroscience, notably the work of labs led by Tomaso Poggio, Thomas Serre, Maximilian Riesenhuber, and Jim DiCarlo. Models based on convolutional stacks and max pooling have been used to explain various properties of the visual system. These models often used different nonlinearities and unsupervised training of features than current CNNs, and they did not achieve the scale of modern CNNs.
The paths chosen by visual neuroscientists and computer vision researchers have various overlaps and divergences, as they pursue different yet related goals. But overall, CNNs can be well viewed as a continuation of the modeling path of visual neuroscientists. Contributions from the deep learning field have involved computational power and training methods (and data) that ultimately made these models work.
6. What Evidence Do We Have That CNNs Work in a “Brain-like” Manner?
Convolutional neural networks have three main characteristics that support their use as models of biological vision: (1) they can perform visual tasks at levels close to humans, (2) their working architecture replicates known basic functions of the visual system, and (3) their generated activity can be directly correlated with activity in different regions of the visual system.
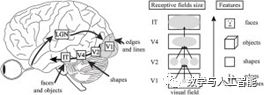
Features of the Visual Hierarchy
First, fundamentally and architecturally, they have two important components of the visual hierarchy. First, the size of the receptive field of individual units increases with the progression of layers in the network, just as receptive fields increase from V1 to IT. Second, as layers progress, the image features that neurons respond to become increasingly complex, similar to how tuning progresses from simple lines in V1 to object parts in IT. This increase in feature complexity can be directly observed through visualization techniques available for CNNs.
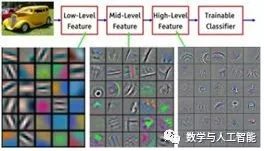
Visualization of Features Learned at Different Layers of the Network
Looking deeper into the third point, many studies following the original 2014 research (Q4) have further determined the relationship between activity in CNNs and the visual system. These have shown the same general findings: when viewing the same images, the activity in artificial networks can be correlated with activity in the visual system. Furthermore, the later layers in the artificial networks correspond to later areas in the ventral visual stream (or later time points in responses obtained using methods like MEG).
Many different methods and datasets have been used to make these points, such as the following studies: Seibert et al. (2016), Cadena et al. (2017), Cichy et al. (2016), Wen et al. (2018), Eickenberg et al. (2017), Güçlü and van Gerven (2015), and Seeliger et al. (2017).
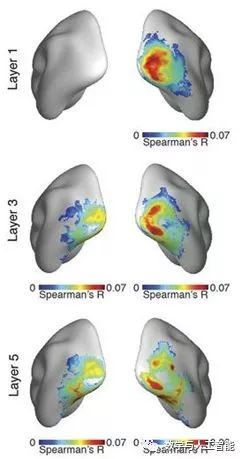
Correspondence of Different CNN Layers with Brain Regions (from Cichy et al.)
The studies focused on the initial neural responses obtained when simple natural images of different target categories were presented. Thus, these CNNs achieve what is known as “core object recognition” or “the ability to rapidly distinguish a given visual target from all other targets, even in the presence of transformations that maintain identity (position, size, angle, and visual background changes).” Generally, standard feedforward CNNs best capture the early components of visual responses, indicating that they replicate the initial feedforward sweep of information from the retina to higher cortical areas.
The series of neural representations created by the visual system can be replicated by CNNs, indicating that they perform a similar “untangling” process. In other words, both systems take representations of different target categories that are inseparable at the image/retinal level and create representations that allow for linear separability.
In addition to comparing activities, we can also look deeper (1), namely the performance of the networks. Detailed comparisons between these networks and human and animal behavior can further validate their use as models and identify areas that still need progress. Findings from such studies have indicated that these networks can achieve patterns of human classification behavior better than previous models from multiple domains (even predicting/manipulating it), but in certain specific areas, these networks perform poorly, such as in cases of noise in images or very subtle differences in images where accuracy drops significantly.
Research on these behavioral effects includes: Rajalingham et al. (2018), Kheradpishesh et al. (2015), Elsayed et al. (2018), Jozwik et al. (2017), Kubilius et al. (2016), Dodge and Karam (2017), Berardino et al. (2017), and Geirhos et al. (2017).
Do all of these meet the standards of an excellent brain model? We should look at what people in the visual field say they want from a model of the visual system:
“Understanding the advances in the brain’s object recognition solutions requires constructing artificial recognition systems (often involving biological inspiration, such as [2-6]), with the ultimate goal of simulating our own visual abilities. Such computational methods are crucial because they provide testable hypotheses through experiments and because the instantiation of effective recognition systems is a particularly effective metric for understanding object recognition.” — Pinto et al., 2007
From this perspective, it is clear that CNNs are not a shift in the goals of the visual sciences but a method for achieving those goals.
7. Are There Other Models That Predict Visual Region Behavior Better?
Overall, no. Some studies have directly compared CNNs with previous models of the visual system (such as HMAX) in their ability to capture neural activity. CNNs excel in this regard. Such studies include: Yamins et al. (2014), Cichy et al. (2017), and Cadieu et al. (2014).
8. Are CNNs Mechanistic Models of the Visual System or Descriptive Models?
A reasonable definition of a mechanistic model is that the internal parts of the model can map to the relevant internal parts of the system. A descriptive model, on the other hand, merely matches their overall input-output relationships. So a descriptive model of the visual system could be a model that takes an input image and outputs target labels consistent with those given by humans, but may not have a clear connection to how the brain works. However, as mentioned above, the layers of CNNs can map to brain regions. Therefore, when CNNs perform object recognition, they serve as mechanistic models of the transformations executed by the ventral system.
Overall, if we are to consider CNNs as mechanistic models, we do not need to have corresponding mechanisms for all components. For instance, traditional brain circuit models use rate-based neurons. Rate-based neural models are simply a function that maps input intensity to output firing rate. Therefore, they are merely descriptive models of neurons: there are no internal components in the model that relate to the neural processes that cause firing rates (more detailed biophysical models like Hodgkin-Huxley neurons are mechanistic). However, we can still use rate-based neurons to construct mechanistic models of circuits (one case I like: https://www.ncbi.nlm.nih.gov/pubmed/25611511). All mechanistic models rely on descriptive models as their basic units (otherwise we would all need to delve into quantum mechanics to build models).
So are the components of CNNs (i.e., layers—composed of convolutions, nonlinearities, possible normalization, and pooling) mechanistic models of brain regions or descriptive models? This question is harder to answer. Although these layers are composed of artificial neurons that can reasonably map to real neurons (or groups of neurons), many of the computational implementations are not biologically plausible. For example, normalization (in networks that use it) is implemented using highly parameterized division equations. We believe these computations could be implemented using realistic neural mechanisms (see the studies cited above), but current models do not use them (though I and some others are researching this issue… see Question 12).
9. How Should We Interpret the Relationship Between Different Parts of CNNs and the Brain?
For neuroscientists used to dealing with cellular-level matters, it may seem that the abstract value of models like CNNs outweighs their practical value (though cognitive scientists who study abstract multi-regional modeling may be more familiar with them).
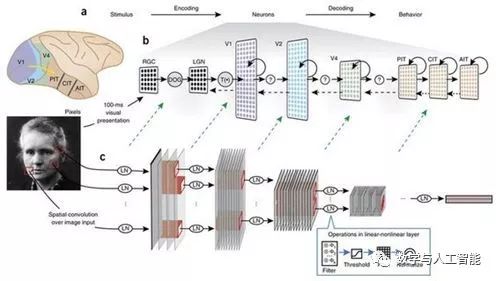
Linking CNNs to Brain Regions and Processing
But even without precise biological details, we can map the components of CNNs to components of the visual system. First, the input to CNNs is typically three-dimensional (RGB) pixel values that have undergone some normalization or whitening, roughly corresponding to the computations performed by the retina and the lateral geniculate nucleus. The feature maps created by convolutions have a spatial layout similar to the retinotopic mapping found in visual areas, meaning that each artificial neuron has a spatially constrained receptive field. The convolution filters associated with each feature map determine the feature modulation of the neurons in that feature map. A single artificial neuron is not meant to map directly to a single real neuron; it may be more reasonable to think of a single unit as a cortical column.
Which layers of CNNs correspond to which brain regions? Studies using early models with only a few layers have provided support for mapping one layer to one brain region. For instance, in Yamins et al. (2014), the last convolutional layer best predicted IT activity, while the second-to-last layer best predicted V4. However, the exact relationships will depend on the models used (deeper models allow more layers per brain region).
The fully connected layers at the end of convolutional networks have more complex interpretations. Their close relationship to the final decision of the classifier and the fact that they no longer have retinotopic topology suggest that they are more akin to the frontal cortex. However, they may also perform well in predicting IT activity.
10. What Does the Visual System Have That CNNs Lack?
Many things. Spiking, saccades, separate excitatory and inhibitory cells, dynamics, feedback connections, feedforward connections skipping certain layers, oscillations, dendrites, cortical layers, neuromodulation, the fovea, lateral connections, different cell types, binocular vision, adaptation, noise, and other details of the brain.
Of course, there are also some features that most standard CNNs currently used as models lack. However, many of these have been studied in updated models, such as: skip connections, feedback connections, saccades, spikes, lateral connections, and the fovea.
So it is clear that CNNs are not a direct replica of primate vision. It should also be clear that this does not mean the models are inadequate. Models cannot (and should not) be complete reproductions of relevant systems. Our goal is for models to possess the necessary characteristics to explain the information we want to understand about vision, so the absence of a particular feature may be more or less important to different people. For instance, what features are needed to predict the average response of IT neurons to images in the first 100 ms? This is an empirical question. We cannot say in advance that a biological feature is necessary or that a model is poor without it.
We can say that models without spikes, E-I types, and other implementation details are more abstract than those that have these details. But abstraction is not a flaw. It just means we are willing to break the problem into different levels and tackle them separately. One day we should be able to combine these different levels of explanation to obtain a replica of the brain at both large and fine scales. But we must remember not to let perfection be the enemy of success.
11. What Can CNNs Do That the Visual System Cannot?
For me, this is a more relevant question. Using some non-biological model to bypass difficult problems is more problematic than using a model that lacks certain specific biological features.
The first issue: convolutional weights can be positive or negative. This means that feedforward connections can be excitatory or inhibitory (while most brain connections between regions are excitatory), and a single artificial neuron can be excitatory or inhibitory. If we only consider the weights as net effects, this is not a big problem; it may actually be achieved by executing feedforward excitatory connections that connect to inhibitory cells.
Next: weights are shared. This means that neurons at a certain position in a feature map will use the same weights as another neuron at a different position in the same feature map. While orientation tuning and similar functions may be the case in the V1 retinotopic map, we do not believe that neurons favoring vertical lines at one position in visual space will have exactly the same input weights as another neuron at a different position also favoring vertical lines. There is no ensuring that all weights are relevant and shared, with no “spooky action at a distance.” Therefore, the weight sharing currently used to help train these networks should be replaced with methods that create spatially invariant modulation more closely resembling biology.
Third: what about max pooling? In neuroscience terms, max pooling operations are akin to the firing rates of neurons, which equal the firing rate of their highest firing input. Since neurons aggregate signals from many other neurons, it is difficult to design a neuron that can directly do this. However, pooling operations were inspired by the discovery of complex cells and were originally used as an averaging operation that neurons could easily implement. However, it has been shown that max pooling performs better in object recognition and fitting biological data, and it is now widely used.
The further development of CNNs by machine learning researchers has allowed them to far exceed the scope of the visual system (since the goal of machine learning researchers is solely performance). Some of the best-performing CNNs now have many features that seem very strange from a biological perspective. Additionally, the extreme depth of these updated models (around 50 layers) has already diminished their activity’s correlation with the visual system.
Of course, there are also issues with how these networks are trained (via backpropagation). This will be discussed in Question 13.
12. Can CNNs Be Made to Function More Like the Human Brain?
One of the main reasons I became a computational neuroscientist is that (without the limitations of experimental setups) we can do anything we want. So yes! We can give standard CNNs more biologically inspired features. Let’s look at what we have achieved:
As mentioned in Question 10, many architectural elements have already been added to different variants of CNNs, making them closer to the ventral stream. Additionally, there have been some research results aimed at increasing the rationality of the learning process (see Question 13).
In addition to these efforts, specific research aimed at reproducing biological details includes:
Biologically inspired work by Spoerer et al. (2017) shows that lateral and feedback connections can help models better recognize occluded and noisy targets.
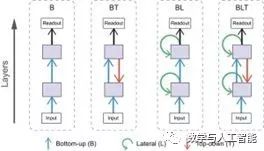
Adding Biologically Inspired Connections, from Spoerer et al. (2017)
Some of my own research (presented at Cosyne 2017 and accurately submitted to journals) has involved incorporating stabilized supralinear networks (a biologically plausible circuit model for implementing normalization) into CNN architectures. This introduces E and I cell types, dynamics, and recurrence into CNNs.
Costa et al. (2017) implemented long short-term memory networks (LSTMs) using biologically inspired components. LSTMs are commonly used when adding recurrence to artificial neural networks, so determining how to implement this functionality in a biological manner would be useful.
13. Is the Method of Learning Weights Through Backpropagation Important for CNNs?
Backpropagation involves calculating how the weights at any position in the network should change to reduce the errors produced by the classifier. This means that a synapse in the first layer has some information about the error and passes it all the way to the top layer. However, real neurons often rely on local learning rules (like Hebbian plasticity), where weight changes are primarily determined by the synapses before and after the neurons, rather than being influenced by distant factors. Therefore, backpropagation should not be seen as a biological way of simulating learning.
This does not need to affect our view of fully trained CNNs as models of the visual system. The parameters in computational models are often fitted using techniques that bear no resemblance to how the brain learns (like Bayesian inference for capturing functional connectivity). But this does not make the resulting circuit models uninterpretable. In extreme cases, we can view backpropagation as just another simple parameter fitting tool, like any other technique. Moreover, Yamins et al. (2014) indeed used a different parameter fitting technique (not backpropagation).
However, adopting this view does not mean that specific aspects of the model are uninterpretable. For example, we do not expect the learning curves (how error changes with model learning) to correlate with how humans or animals learn and make errors.
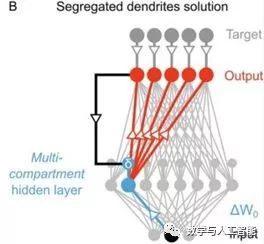
Using Segregated Dendrites for Local Error Computation, from Guerguiev et al.
Although the current implementation of backpropagation lacks biological plausibility, it can be viewed as an abstract version of how the brain actually works. Currently, multiple studies are working to make backpropagation biologically plausible, such as through local computations and realistic cell types, like “Towards deep learning with segregated dendrites” and “An Approximation of the Error Backpropagation Algorithm in a Predictive Coding Network with Local Hebbian Synaptic Plasticity.” This could provide a better biological explanation for this learning process. Whether more biologically plausible learning processes can achieve neural activities that better match the data is still an empirical question.
On the other hand, unsupervised learning appears to be a brain mechanism, as it does not require explicit feedback about labels but instead uses the natural statistics of the environment to develop representations. So far, unsupervised learning has not achieved the same high performance in target classification as supervised learning. However, advancements in making unsupervised learning and methods biologically plausible may ultimately lead to better models of the visual system.
14. What Can We Learn About the Visual System Using CNNs?
By relying solely on CNNs, we learn nothing. All insights and developments need to be validated and extended through interaction with experimental data. In other words, CNNs can contribute to our understanding of the visual system in three ways.
The first is validating our intuitive understanding. As Feynman said, “We cannot understand what we cannot create.” With all the collected data and developed theories of the visual system, why can’t neuroscientists create a functioning visual system? This should alert us and make us realize that we have missed some key elements. Now we can say that our intuitive understanding of the visual system is basically correct; we just lack computational power and training data.
The second contribution is allowing the realization of an ideal experimental testing platform. This is a common approach in the scientific community for mechanistic models. We can use existing data to build a reasonable model that simulates what we are interested in. Then we test its various parts to see which parts are important for functional realization. This can generate hypotheses for future experiments and/or explain previously unused data in constructing that model.
The third way is through mathematical analysis. This is always the case for computational modeling; integrating our beliefs about how the visual system works into concrete data terms opens up new research directions. Although analysis of models often requires further simplification, it still provides helpful insights into the general trends and limitations of model behavior. In this particular case, there may also be some additional momentum for development, as certain machine learning researchers are also interested in mathematically dissecting these models. Their insights can, in appropriate situations, become our insights, such as http://www.cs.toronto.edu/~wenjie/papers/nips16/top.pdf
15. What Have We Learned by Using CNNs as Models of the Visual System?
First, we have shown that our intuitive understanding can actually be used to construct a functioning visual system, thereby validating these intuitive understandings. Moreover, this approach has helped us define (in Marr’s terms) the computational and algorithmic levels of the visual system. The ability to obtain so much neural and behavioral data through training on object detection indicates the core computational function of the ventral stream. A series of convolutions and poolings is part of the algorithms needed to achieve this.
I believe that the success of these networks has also helped change our view of the basic research unit in the field of visual neuroscience. Much of visual neuroscience (and indeed all of neuroscience) has historically been dominated by approaches centered around individual cells and their tuning preferences. An abstract model that does not strictly correspond to one neuron per neuron acquisition data will focus on population coding. One day, attempts to understand individual tuning functions may yield similar results, but currently, population-level approaches seem more effective.
Furthermore, viewing the visual system as a whole system rather than isolated regions can reshape our understanding of these regions. A lot of work has been invested in studying V4, for example, trying to describe what causes cells in that region to respond using language or simple mathematics. When V4 is viewed as an intermediate foothold in the object recognition pathway, it seems less likely that it can be described in isolation. As stated in this review paper “Deep neural networks: a new framework for modeling biological vision and brain information processing”: “A verbal functional explanation of a unit (such as as an eye or face detector) may help us directly understand something important. However, such verbal explanations may exaggerate the degree of classification and localization and underestimate the statistical and distributed nature of these representations.” In fact, analyses of trained networks have shown that strong and interpretable modulation of individual units is not related to good performance, indicating that the historical focus on individual units has been misguided.
There are many more cases. Overall, given that research in this area only truly began around 2014, I would say the volume of research has been quite impressive.
Original link: https://neurdiness.wordpress.com/2018/05/17/deep-convolutional-neural-networks-as-models-of-the-visual-system-qa/