Click on the above “Beginner’s Guide to Vision“, choose to add “Star Mark” or “Pinned“
Important insights delivered promptly
Author丨Ruoyu

 , γ(ξ) is a weight function that decays with frequency).
, γ(ξ) is a weight function that decays with frequency).

-
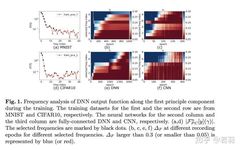
Conducting experiments on functions: 


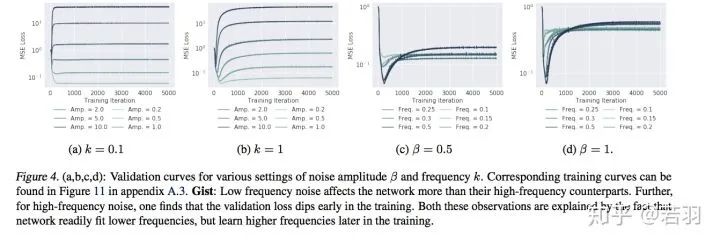



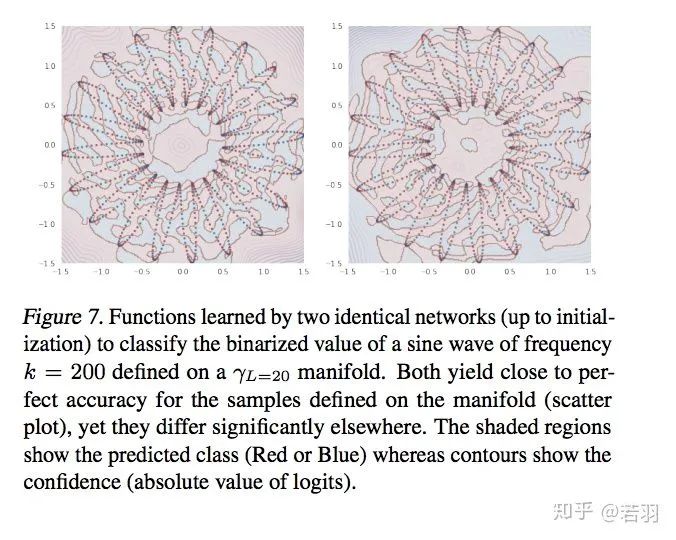
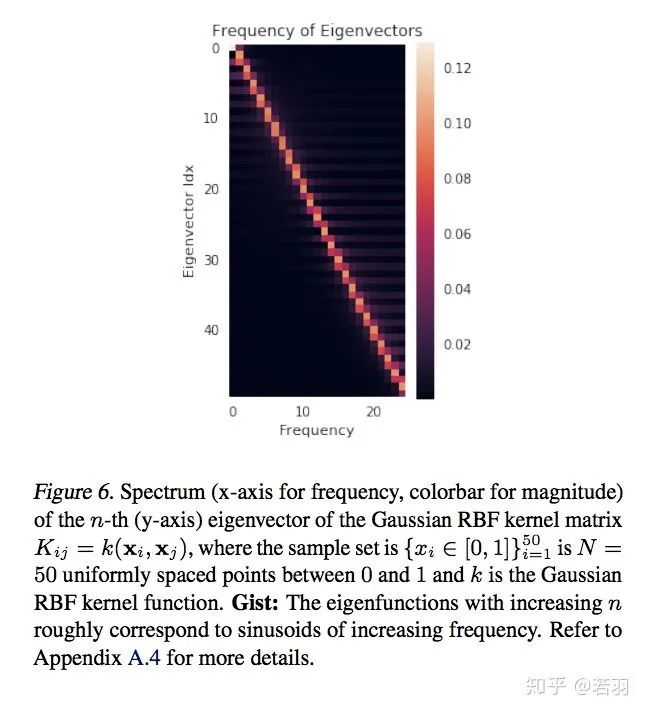
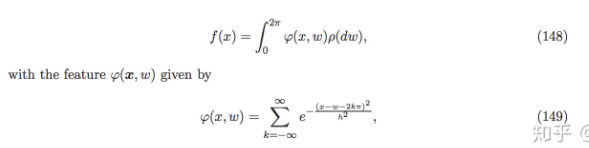
 Probability measure
Probability measure







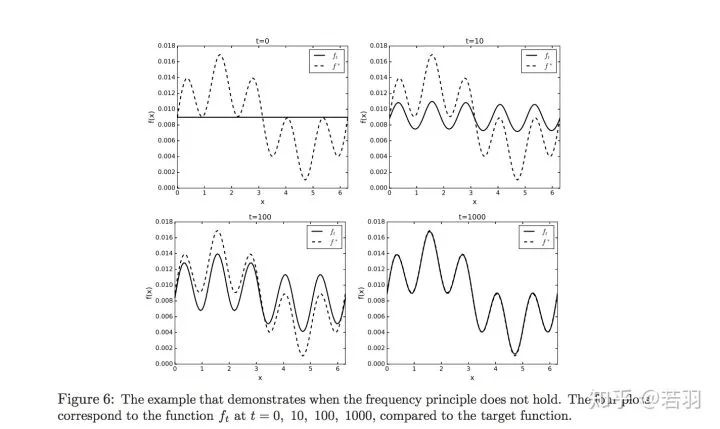
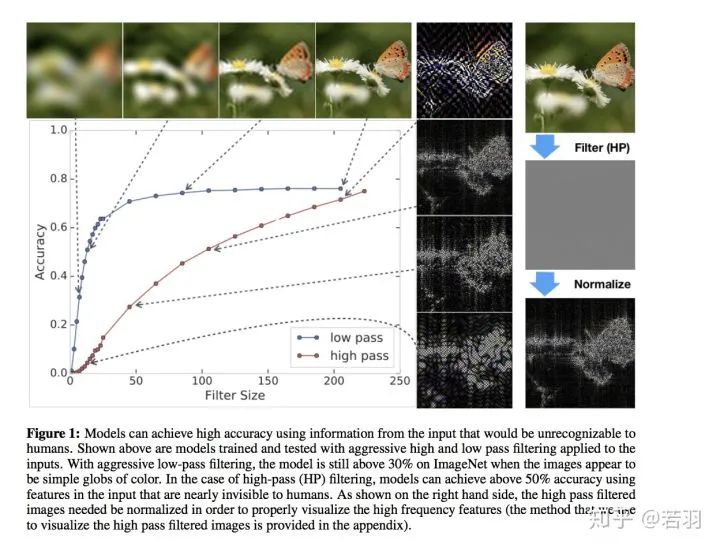
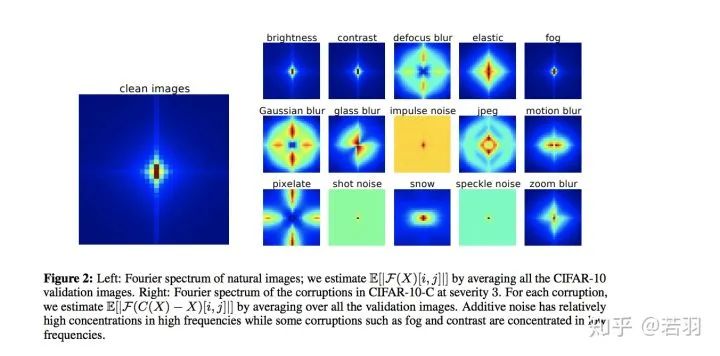
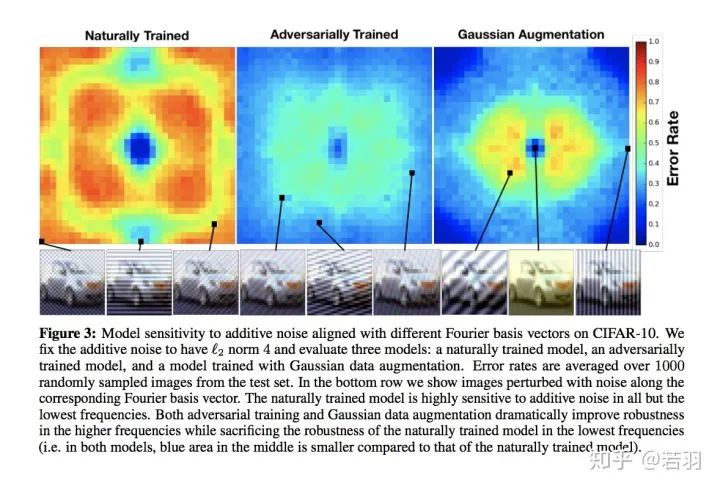
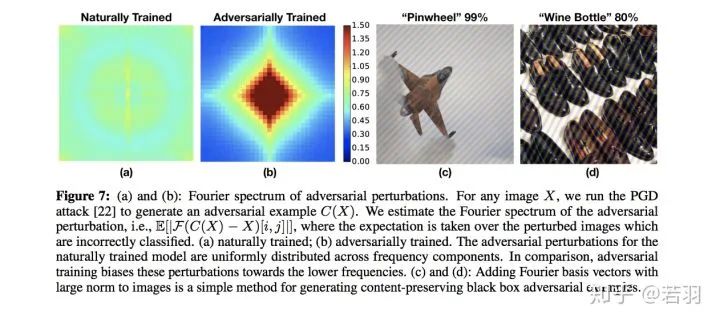

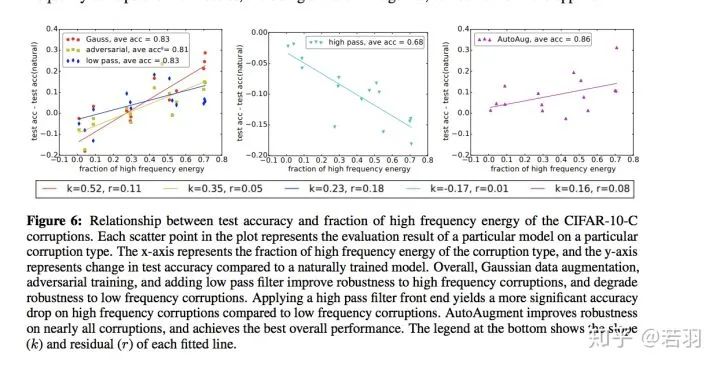



-
For a trained model, we adjusted its weights to make the convolution kernels smoother;
-
Directly filtering high-frequency information on the trained convolution kernels;
-
Adding regularization during the training of convolutional neural networks to make weights at adjacent positions closer.

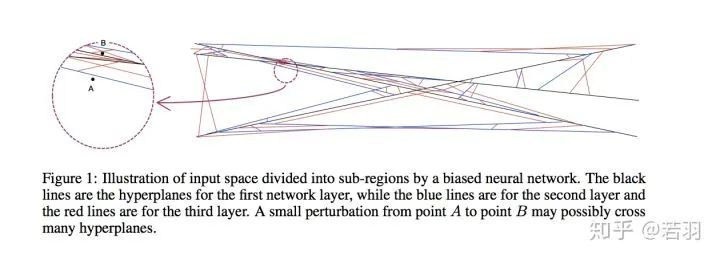


Author丨Xinsi Fengwang

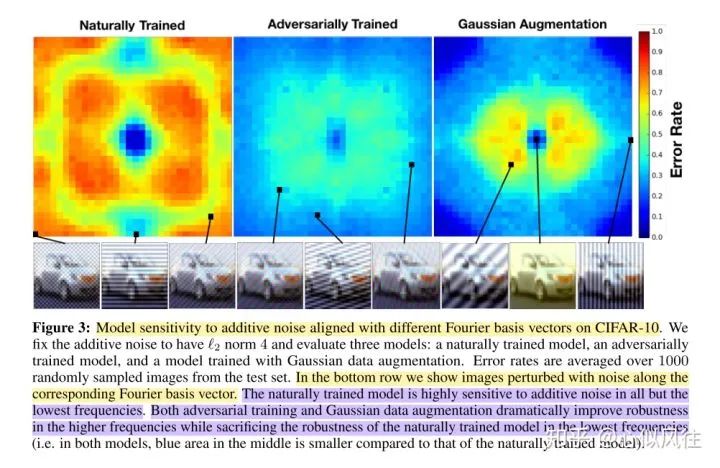

Good News!
Beginner’s Guide to Visual Knowledge Circle
Is now open to the public👇👇👇
Download 1: Chinese Version Tutorial for OpenCV-Contrib Extension Modules
Reply "Chinese Tutorial for Extension Modules" in the backend of the "Beginner's Guide to Vision" public account to download the first Chinese version of the OpenCV extension module tutorial available online, covering over twenty chapters on extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more.
Download 2: 52 Lectures on Practical Python Vision Projects
Reply "Python Practical Vision Projects" in the backend of the "Beginner's Guide to Vision" public account to download 31 practical vision projects, including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help you quickly learn computer vision.
Download 3: 20 Lectures on Practical OpenCV Projects
Reply "20 Practical OpenCV Projects" in the backend of the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes; otherwise, your request will not be approved. After successfully adding, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~