
Click on the above“Beginner Learning Vision” to selectStar or “Top”
Important Content, Delivered First Time
Important Content, Delivered First TimeConvolutional Neural Networks (CNNs) are a type of neural network commonly used for image classification, object detection, and other computer vision tasks. One of the key components of CNNs is the feature map, which is a representation of the input image generated by applying convolutional filters.

Understanding Convolutional Layers
1. Convolution Operation
The concept of convolution is at the core of CNN operations. Convolution is a mathematical operation that combines two functions to produce a third function. In the context of CNNs, these two functions are the input image and the filter, and the result is the feature map.
2. Convolutional Layers
The convolutional layer involves sliding the filter over the input image and calculating the dot product between the filter and the corresponding patch of the input image. The resulting output values are then stored in the corresponding positions in the feature map. By applying multiple filters, each detecting a different feature, we can generate multiple feature maps.
3. Important Parameters
Stride: Stride refers to the step size that the convolutional filter moves across the input data during the convolution operation.
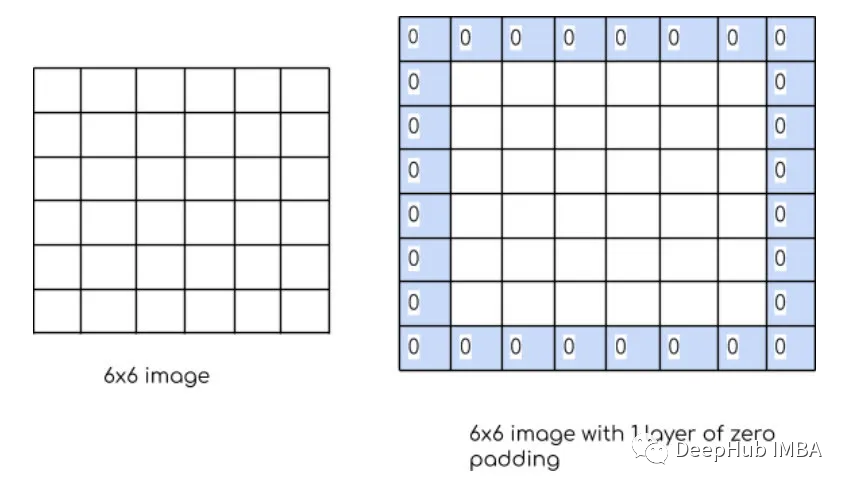
Padding: Padding refers to the addition of extra pixels around the boundary of the input image or feature map before applying the convolution operation.
The purpose of padding is to control the size of the output feature map, ensuring that the filter window can cover the edges of the input image or feature map. Without padding, the filter window will not cover the edges of the input data, leading to a reduction in the size of the output feature map and loss of information. There are two types of padding: “valid” and “same”.
Kernel/Filter: A kernel (also known as a filter or weight) is a small matrix of learnable parameters used to extract features from the input data.
In the diagram below, the size of the input image is (5,5), and the size of the filter is (3,3). The green area represents the input image, and the yellow area represents the filter applied to that image. The filter slides over the input image, calculating the dot product between the filter and the corresponding pixels of the input image. Padding is valid (meaning no padding). The stride value is 1.
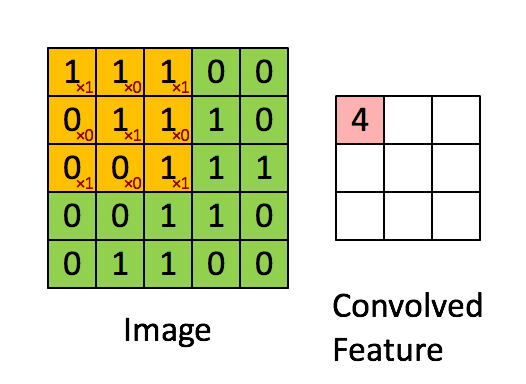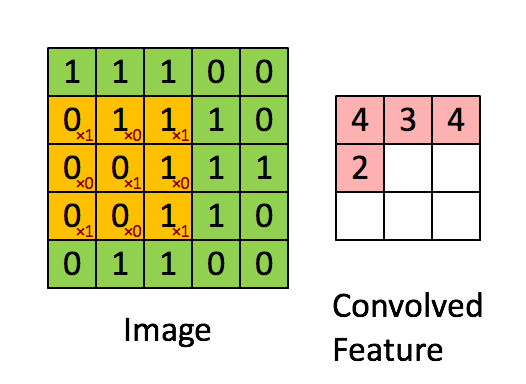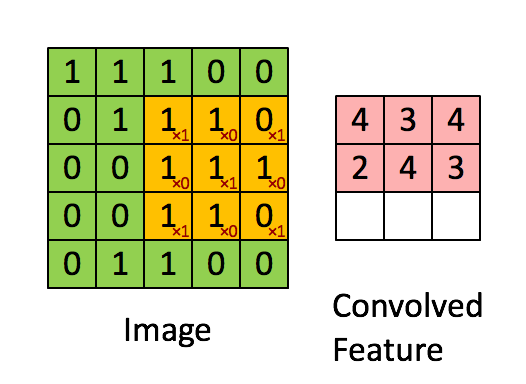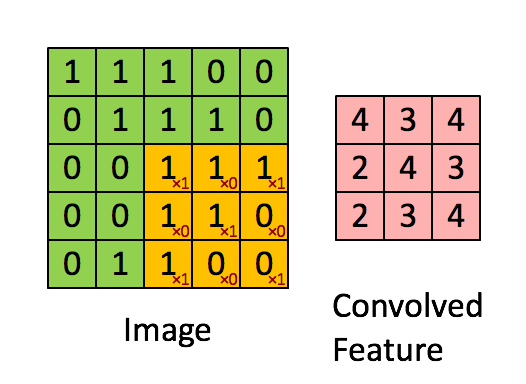
4. Feature Map:
The feature map is the output of the convolutional layer in a Convolutional Neural Network (CNN). They are two-dimensional arrays that contain the features extracted from the input image or signal by the convolutional filters.
The number of feature maps in a convolutional layer corresponds to the number of filters used in that layer. Each filter generates a single feature map by applying the convolution operation to the input data.
The size of the feature map depends on the size of the input data, the filters used in the convolution operation, and the sizes of padding and stride. Typically, as we move deeper into the network, the size of the feature maps decreases while the number of feature maps increases. The size of the feature map can be calculated using the following formula:
Output_Size = (Input_Size - Filter_Size + 2 * Padding) / Stride + 1This formula is very important, as it will definitely be used when calculating the output, so remember it well.
The feature maps from one convolutional layer serve as the input data for the next layer in the network. As the number of layers increases, the network can learn increasingly complex and abstract features. By combining features from multiple layers, the network can recognize complex patterns in the input data and make accurate predictions.
Visualizing Feature Maps
Here we use TensorFlow as the framework for demonstration.
## Importing libraries
# Image processing library
import cv2
# Keras from tensorflow
import keras
# In Keras, the layers module provides a set of pre-built layer classes that can be used to construct neural networks.
from keras import layers
# For plotting graphs and images
import matplotlib.pyplot as plt
import numpy as npUsing OpenCV to import an image and resize it to 224 x 224 pixels.
img_size = (224, 224)
file_name = "./data/archive/flowers/iris/10802001213_7687db7f0c_c.jpg"
img = cv2.imread(file_name) # reading the image
img = cv2.resize(img, img_size)We add 2 convolutional layers:
model = keras.Sequential()
filters = 16
model.add(layers.Conv2D(input_shape = (224, 224, 3), filters = filters, kernel_size= 3))
model.add(layers.Conv2D(filters = filters, kernel_size= 3))Retrieve the filters from the convolutional layer.
filters, bias = model.layers[0].get_weights()
min_filter = filters.min()
max_filter = filters.max()
filters = (filters - min_filter) / (max_filter - min_filter)Visualization
figure = plt.figure(figsize= (10, 20))
filters_count = filters.shape[-1]
channels = filters.shape[0]
index = 1
for channel in range(channels):
for filter in range(filters_count):
plt.subplot(filters_count, channels, index)
plt.imshow(filters[channel, :, :, filter])
plt.xticks([])
plt.yticks([])
index+=1
plt.show()Input the image into the model to obtain the feature map.
normalized_img = (img - img.min()) / (img.max() - img.min())
normalized_img = normalized_img.reshape(-1, 224, 224, 3)
feature_map = model.predict(normalized_img)The feature map needs to be normalized so that it can be displayed in matplotlib.
feature_map = (feature_map - feature_map.min())/ (feature_map.max() - feature_map.min())Extract and display the feature maps.
total_imgs = feature_map.shape[0]
no_features = feature_map.shape[-1]
fig = plt.figure(figsize=(10, 50))
index = 1
for image_no in range(total_imgs):
for feature in range(no_features):
# plotting for 16 filters that produced 16 feature maps
plt.subplot(no_features, 3, index)
plt.imshow(feature_map[image_no, :, :, feature], cmap="gray")
plt.xticks([])
plt.yticks([])
index+=1
plt.show()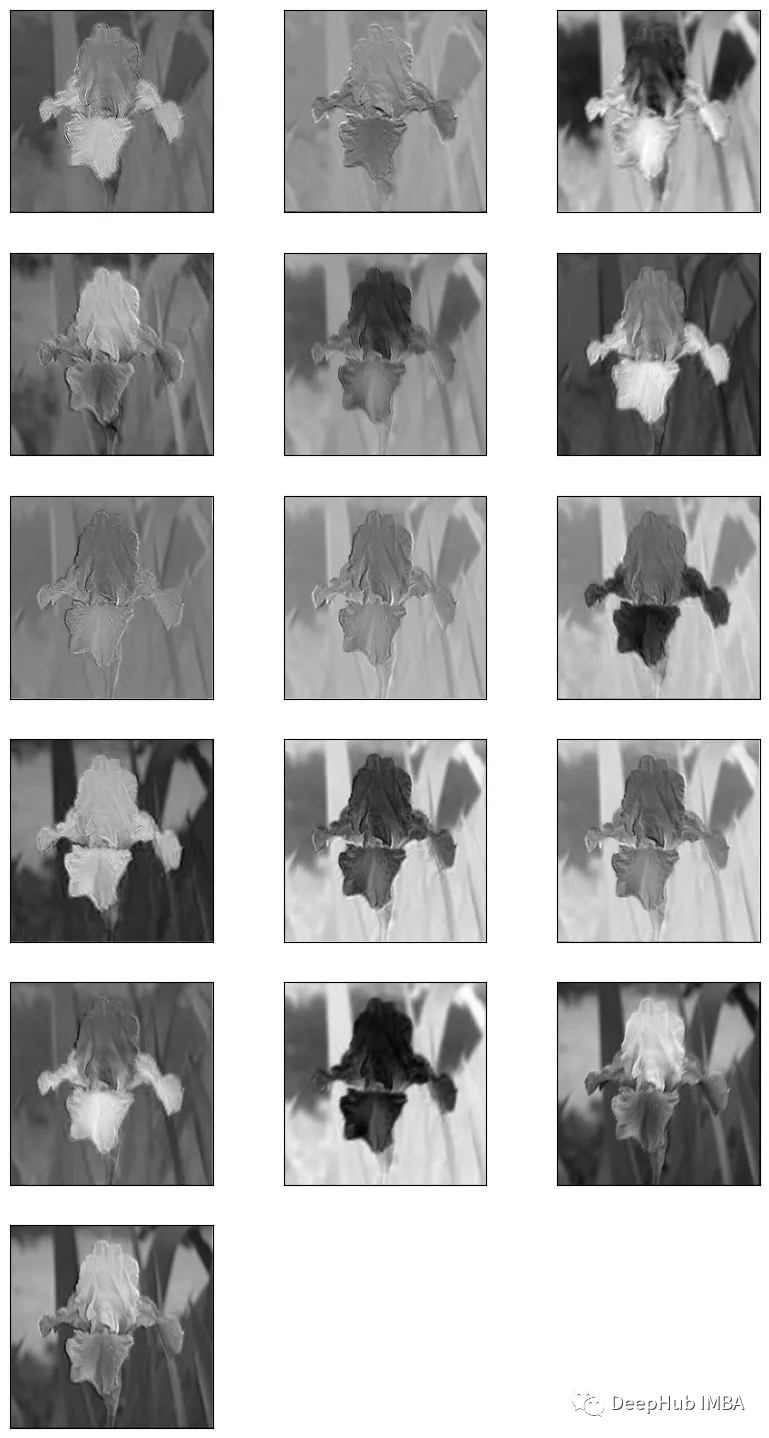
Conclusion
By visualizing the feature maps of different layers of a CNN, we can better understand what the network “sees” when processing images. For example, the first layer may learn simple features such as edges and corners, while later layers may learn more abstract features such as the presence of specific objects. By examining the feature maps, we can also identify areas in the image that are important to the network’s decision-making process.
Author: Ahzam Ejaz
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Beginner Learning Vision" public account to download the first OpenCV extension module tutorial in Chinese online, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Projects 52 Lectures
Reply "Python Vision Practical Projects" in the background of the "Beginner Learning Vision" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eye line addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the background of the "Beginner Learning Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will gradually be subdivided). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes; otherwise, access will not be granted. After successful addition, you will be invited to relevant WeChat groups based on research direction. Please do not send advertisements in the group; otherwise, you will be removed. Thank you for your understanding~