

XGBoost is an integrated machine learning algorithm that can be used for various problems such as regression, classification, and ranking, and is widely used in machine learning competitions and industrial fields. Successful cases include: web text classification, customer behavior prediction, sentiment mining, ad click-through rate prediction, malware classification, item classification, risk assessment, and predicting dropout rates for massive online courses.
XGBoost is one of the models that beginners should deeply understand; it connects knowledge points such as decision trees, boosting, and GBDT, and it is highly recommended that everyone try it out themselves. In this article, I will introduce XGBoost from the aspects of XGBoost origins and advantages, model principles and optimization derivation, XGBoost model parameter analysis, tuning examples, and XGBoost visualization.
XGBoost Origins and Advantages
In data modeling, the Boosting method is often used, which combines hundreds or thousands of tree models with low classification accuracy into a highly accurate predictive model. This model iterates continuously, generating a new tree with each iteration. However, when the dataset is complex, it may require thousands of iterations, leading to significant computational bottlenecks.
To address this issue, Dr. Tianqi Chen from the University of Washington developed XGBoost (eXtreme Gradient Boosting), which implements parallel construction of regression trees in C++ through multithreading and improves upon the original Gradient Boosting algorithm, greatly enhancing model training speed and prediction accuracy.
The main advantages of XGBoost are as follows:
1. GBDT uses only first-order derivative information during optimization, while XGBoost utilizes both first-order and second-order derivatives and supports custom loss functions, provided that the loss function is differentiable to the first and second order;
2. It introduces regularization terms to control model complexity and prevent overfitting;
3. Drawing from the approach of random forests, it supports column sampling (randomly selecting features), which not only reduces overfitting but also decreases computation;
4. When searching for the best split point, it implements an approximate method and considers sparse datasets and missing value handling, significantly improving algorithm efficiency;
5. Supports parallelization;
6. Uses an approximate histogram algorithm for efficiently generating candidate split points;
7. Many optimizations have been made during algorithm implementation, greatly enhancing efficiency, and when memory space is insufficient, it utilizes block processing, prefetching, compression, and multithreading cooperation.
XGBoost Model Principles and Optimization Derivation
XGBoost is actually a type of GBDT and is still an additive model with a forward optimization algorithm.
An additive model means that the strong classifier is formed by linearly adding a series of weak classifiers. The general combination form is as follows:
Where, each is a weak classifier, is the optimal parameter learned by the weak classifier, represents the weight of the weak learning in the strong classifier, and P is the combination of all and . These weak classifiers are linearly added to form the strong classifier.The forward step means that the classifier produced in the next iteration is trained based on the previous iteration. This can be expressed in the following form:What does the XGBoost model look like?
- Where K is the number of trees.
- is the regression tree, which satisfies
- q represents the structure of each tree, mapping a training sample instance to the corresponding leaf index.
- T is the number of leaves in the tree.
- Each corresponds to an independent tree structure q and leaf weight w.
- is the function space composed of all regression trees.
Unlike decision trees, each regression tree contains a continuous value at each leaf, which we use to represent the score at the i-th leaf. For a given sample instance, we use the decision rules on the tree (given by q) to classify it into the leaf and calculate the final predicted value by summing the scores at the corresponding leaves (given by w).
Learning in XGBoost
To learn this set of functions in the model, we minimize the following regularized objective function:Where: is the loss function, commonly there are 2 types: square loss function:logistic regression loss function:: regularization term, used to penalize complex models to avoid overfitting the training data. Common regularizations are L1 regularization and L2 regularization: L1 regularization (lasso): L2 regularization:The next step is to learn the objective function, retaining the original model unchanged and adding a new function to our model.Where is the prediction for the i-th instance at the t-th iteration, we need to add the tree, and then minimize the following objective function:Assuming the loss function uses square loss, the above expression can be further written as:Now, we use Taylor expansion to define an approximate objective function:Where:are the first-order and second-order gradients on the loss function.For those who have forgotten the basics, let’s briefly review Taylor’s theorem.Taylor’s theorem is a formula that describes the values of a function near a point using information about the function at that point. Its original intention was to use polynomials to approximate the behavior of functions around a point.The basic form of the function at is as followsThere is also another common expression, expanding at , we get:Now, we remove the constant and re-examine our new objective function:Define as the set of instances for leaf j. Incorporating the regularization term, we expand the objective function:It looks a bit complex, let: , the above expression simplifies to:The above expression is mutually independent and is a square term. For a given structure, we can calculate the optimal weights:Substituting into the above expression, we obtain the optimal solution for the loss:This can serve as a scoring function to measure the quality of a tree structure.We have a method to measure how good a tree is, now let’s look at the second problem optimized by XGBoost: how to choose which features and feature values to split to minimize our loss function?Feature selection and split point selection indicators in XGBoost are defined as:
How to Split Specifically?
XGBoost selects split points that maximize the gain after splitting at each step. The selection of split points previously enumerated all split points, which is called the exact greedy algorithm, enumerating all possible partitions across all features.

- Based on the current node, attempt to split the decision tree, with the default score=0, G and H being the sum of the first-order and second-order derivatives of the current node that needs to be split.
- For feature index k=1,2…K:
- Sort the samples by feature k in ascending order, sequentially taking out the i-th sample and calculating the first-order and second-order derivative sums for the left and right subtrees after placing the current sample into the left subtree:
- Attempt to update the maximum score:
- Split the subtree based on the feature and feature value corresponding to the maximum score.
- If the maximum score is 0, the current decision tree is completed, calculating all leaf regions, obtaining the weak learner, updating the strong learner, and entering the next iteration of weak learner. If the maximum score is not 0, continue attempting to split the decision tree.
When the data volume is enormous, the Exact Greedy algorithm can be very slow, so XGBoost introduces an approximate algorithm, which is very similar to Exact Greedy, and will not be elaborated here.

Principle Derivation (Simplified Version)
Below is a simplified version of the principle derivation of XGBoost for students to review.
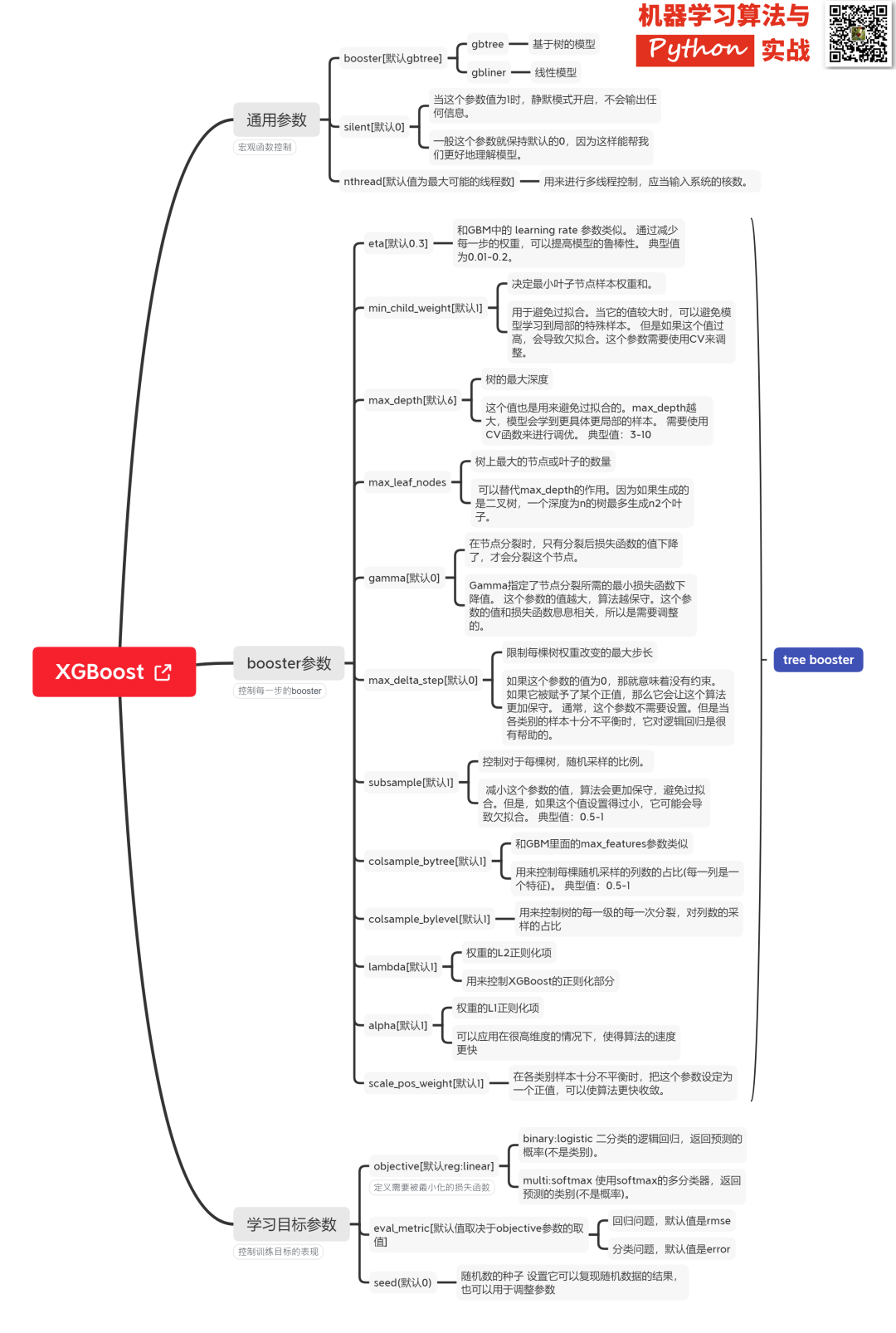
Xgboost@sklearn Model Parameter Analysis
XGBoost has both a native version and a Scikit-learn version, with some minor differences in usage. Here is the parameter explanation for xgboost.sklearn. XGBoost stores parameters in a key-value dictionary:
# Some important parameters
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # Multi-class problem
'num_class': 10, # Number of classes, used with multisoftmax
'gamma': 0.1, # Parameter for controlling whether to prune, larger values are more conservative, generally around 0.1 or 0.2.
'max_depth': 12, # Depth of the tree, larger values are more prone to overfitting
'lambda': 2, # Weight for L2 regularization, larger values make the model less prone to overfitting.
'subsample': 0.7, # Randomly sampling training samples
'colsample_bytree': 0.7, # Column sampling during tree generation
'min_child_weight': 3,
'silent': 1, # Set to 1 for no output information, best to set to 0.
'eta': 0.007, # Similar to learning rate
'seed': 1000,
'nthread': 4, # Number of CPU threads
}
Due to space constraints, tuning examples and XGBoost visualization will be discussed next time. If you found this helpful, please feel free to give a like, save, or share.
References
https://www.cnblogs.com/pinard/p/10979808.htmlhttps://www.biaodianfu.com/xgboost.html
https://www.zybuluo.com/vivounicorn/note/446479
https://www.cnblogs.com/chenjieyouge/p/12026339.html
I am Dong Ge, and I am currently creating the series topic 👉 "100 Pandas Operations," welcome to subscribe. After subscribing, article updates will be pushed to the subscription account in real-time, ensuring you don't miss any article.
Finally, I would like to share "100 Python E-books," including Python programming skills, data analysis, web scraping, web development, machine learning, and deep learning.
Now sharing for free, interested readers can download and learn by replying with the keyword: Python in the public account "GitHuboy".
Recommended Reading
Incredible! It's so comfortable to use this tool to view code.
Bilibili, take off!
Goodbye, Baidu Search!
Customer churn prediction and marketing plan (Python)
Open wide, the most powerful Python editor detailed usage guide!
Wow, B station has launched the latest "Machine Learning System" series from Stanford, learn during the holidays!
Those who love to like will not have too bad luck.