Author: Tian Yu Su
Zhihu Column: Machine Learning
Link: https://zhuanlan.zhihu.com/p/27234078
Before We Start
The column has finally been approved, but I am currently applying for a name change, which may take a few days for review.In the future, I will periodically update the column with some content on machine learning and deep learning, mainly including code for machine learning competitions, algorithm ideas for deep learning, and practical deep learning code.Since I am currently interning at a company, I will focus on my work during working hours, and I will take time to write this column after work and on weekends. I will also try to respond to questions in the comment section!This sharing mainly consists of translations, understanding, and integration of two English documents introducing the Skip-Gram model in Word2Vec.The next column article will implement a basic version of the Word2Vec Skip-Gram model using TensorFlow, so this article will lay a theoretical foundation.For the original English documents, please refer to the links:– Word2Vec Tutorial – The Skip-Gram Model– Word2Vec (Part 1): NLP With Deep Learning with Tensorflow (Skip-gram)
What Are Word2Vec and Embeddings?
Word2Vec is a model that learns semantic knowledge from a large amount of text data in an unsupervised manner, and it is widely used in Natural Language Processing (NLP).So how does it help us with NLP?Word2Vec represents the semantic information of words through word vectors by learning from text, meaning that semantically similar words are close together in an embedding space.Embedding is actually a mapping that maps words from their original space to a new multidimensional space, effectively embedding the original space of words into a new space.From an intuitive perspective, the word ‘cat’ and ‘kitten’ are semantically close, while ‘dog’ and ‘kitten’ are not as close, and ‘iphone’ is even further from ‘kitten’ semantically.By learning this numerical representation of words in the vocabulary (i.e., converting words into word vectors), we can perform vectorized operations based on these numbers to derive interesting conclusions.For example, if we perform the operation on word vectors ‘kitten’, ‘cat’, and ‘dog’:‘kitten’ – ‘cat’ + ‘dog’, the resulting embedded vector will be very close to the word vector for ‘puppy’.
Part One
Model
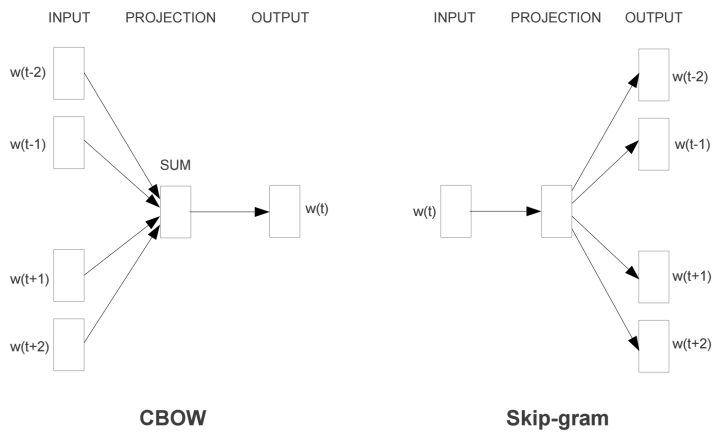
In the Word2Vec model, there are mainly two models: Skip-Gram and CBOW. Intuitively, Skip-Gram predicts context given an input word, while CBOW predicts the input word given the context.This article will only explain the Skip-Gram model.
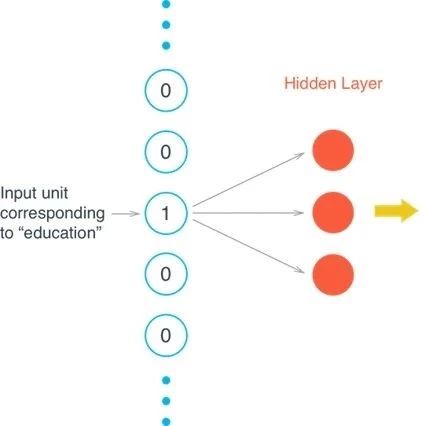
The basic form of the Skip-Gram model is very simple. To explain the model more clearly, let’s first look at the most general basic model of Word2Vec (hereafter, all references to Word2Vec refer to the Skip-Gram model).
The Word2Vec model is actually divided into two parts: the first part is building the model, and the second part is obtaining the embedded word vectors through the model.The entire modeling process of Word2Vec is quite similar to the idea of an auto-encoder, where we first construct a neural network based on training data. Once this model is trained, we do not use this trained model to handle new tasks; what we really need are the parameters learned by the model from the training data, such as the hidden layer’s weight matrix—what we are trying to learn in Word2Vec is actually these “word vectors”.We call the modeling process based on training data “Fake Task”, meaning that modeling is not our ultimate goal.
The method mentioned above is actually seen in unsupervised feature learning, the most common being auto-encoders: by encoding and compressing the input in the hidden layer and then decoding the data to restore the initial state in the output layer. After training, we will “cut off” the output layer and only keep the hidden layer.
The Fake TaskAs mentioned above, the true purpose of training the model is to obtain the hidden layer weights learned by the model based on the training data.To get these weights, we first need to build a complete neural network as our “Fake Task”, and later we will return to see how we can indirectly obtain these word vectors through the “Fake Task”.Next, let’s see how to train our neural network.Suppose we have a sentence: “The dog barked at the mailman”.
-
First, we select a word from the middle of the sentence as our input word, for example, we select “dog” as the input word;
-
After obtaining the input word, we define a parameter called skip_window, which represents the number of words we select from one side (left or right) of the current input word.If we set
 , then the words we finally obtain in the window (including the input word) are [‘The’, ‘dog’, ‘barked’, ‘at’].
, then the words we finally obtain in the window (including the input word) are [‘The’, ‘dog’, ‘barked’, ‘at’]. represents selecting 2 words to the left of the input word and 2 words to the right into our window, so the total window size is
represents selecting 2 words to the left of the input word and 2 words to the right into our window, so the total window size is .Another parameter called num_skips represents how many different words we select from the entire window as our output word. When
.Another parameter called num_skips represents how many different words we select from the entire window as our output word. When ,
, , we will get two sets of training data in the form of (input word, output word), namely (‘dog’, ‘barked’) and (‘dog’, ‘the’).
, we will get two sets of training data in the form of (input word, output word), namely (‘dog’, ‘barked’) and (‘dog’, ‘the’). -
The neural network will output a probability distribution based on these training data, which represents the probability of each word in our vocabulary being the output word.This sentence is a bit convoluted, so let’s look at an example.In the second step, we obtained two sets of training data with skip_window and num_skips=2. Suppose we first take a set of data (‘dog’, ‘barked’) to train the neural network, then the model, by learning this training sample, will tell us the probability of each word in the vocabulary being “barked”.
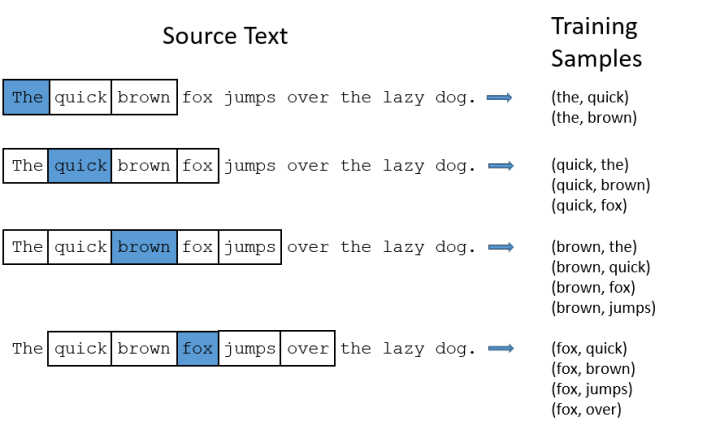
The model’s output probability indicates how likely each word in our vocabulary is to appear simultaneously with the input word.For example, if we input the word “Soviet” into the neural network model, then in the final output probabilities, words like “Union” and “Russia” will have much higher probabilities than unrelated words like “watermelon” and “kangaroo”.This is because “Union” and “Russia” are more likely to appear in the context of “Soviet” in the text.We will train the neural network by inputting pairs of words that appear in the text to perform the probability calculations mentioned above.The following figure shows some examples of our training samples.We select the sentence “The quick brown fox jumps over lazy dog” and set our window size to 2 ( ), which means we only select two words before and after the input word along with the input word for combination.In the diagram below, blue represents the input word, and the words within the box are the words located within the window.
), which means we only select two words before and after the input word along with the input word for combination.In the diagram below, blue represents the input word, and the words within the box are the words located within the window.
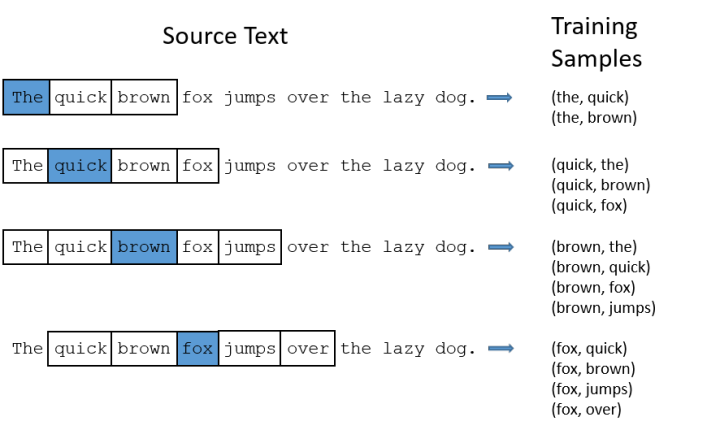
Our model will learn statistical results from the occurrence of each pair of words.For example, our neural network may obtain more training sample pairs like (“Soviet”, “Union”), while it has seen very few combinations like (“Soviet”, “Sasquatch”).Therefore, when our model completes training, given the input word “Soviet”, the output results will assign higher probabilities to “Union” or “Russia” than to “Sasquatch”.Model Details
How do we represent these words?
First, we all know that neural networks can only accept numerical inputs; we cannot input a string of words, so we need to find a way to represent these words.The most common method is to construct our own vocabulary based on the training documents and then perform one-hot encoding on the words.
Assuming we extract 10,000 unique words from our training documents to form a vocabulary.We perform one-hot encoding on these 10,000 words, resulting in each word being a 10,000-dimensional vector, where each dimension can only be 0 or 1. If the word “ants” appears in the vocabulary at the third position, then the vector for “ants” would be a 10,000-dimensional vector with the third dimension being 1 and all other dimensions being 0 ( ).
).
Using the previous example, “The dog barked at the mailman”, we can construct a vocabulary of size 5 (ignoring case and punctuation):(“the”, “dog”, “barked”, “at”, “mailman”), and we will number the words in this vocabulary from 0 to 4.Thus, “dog” can be represented as a 5-dimensional vector [0, 1, 0, 0, 0].
If the model’s input is a 10,000-dimensional vector, then the output is also a 10,000-dimensional vector (the size of the vocabulary), containing 10,000 probabilities, each representing the probability of the current word being the output word in the input sample.The figure below illustrates the structure of our neural network:
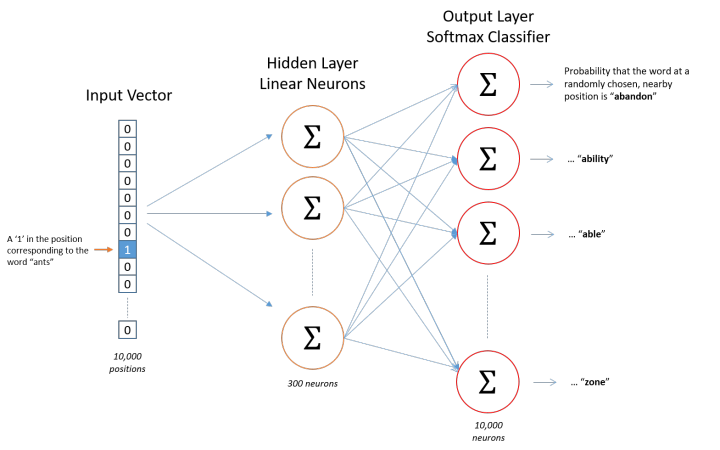
The hidden layer does not use any activation function, but the output layer uses softmax.We train the neural network based on pairs of words, where the training samples are in the form of (input word, output word), and both the input word and output word are one-hot encoded vectors.The final output of the model is a probability distribution.Hidden LayerHaving discussed word encoding and the selection of training samples, let’s take a look at our hidden layer.If we now want to represent a word using 300 features (i.e., each word can be represented as a 300-dimensional vector), then the weight matrix of the hidden layer should be 10,000 rows and 300 columns (the hidden layer has 300 nodes).
Google’s latest model trained on the Google News dataset uses 300 features for word vectors.The dimensionality of the word vectors is a hyperparameter that can be adjusted (in Python’s gensim package, the default word vector size for the Word2Vec interface is 100, and the window size is 5).
Look at the image below, where the left and right images represent the input layer to hidden layer weight matrix from different angles.In the left image, each column represents a 10,000-dimensional word vector connected to the weight vector of a single neuron in the hidden layer.From the right image, each row actually represents the word vector of each word.
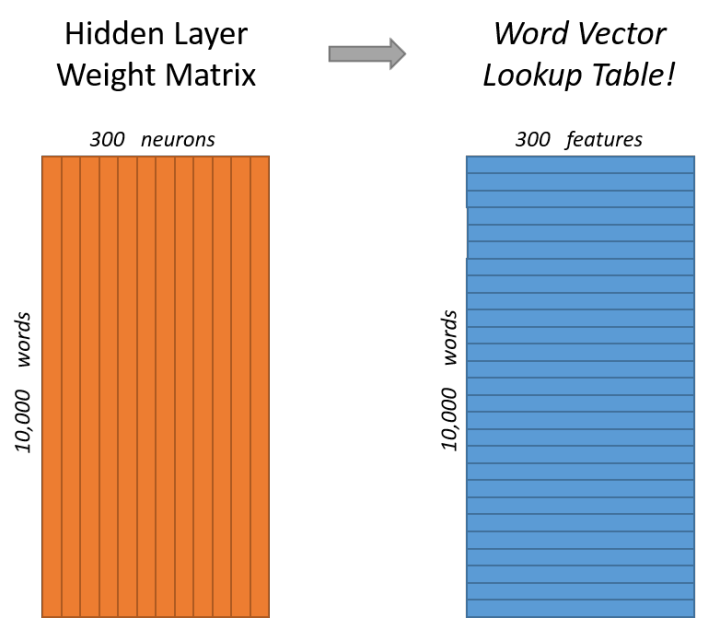
Therefore, our ultimate goal is to learn this weight matrix of the hidden layer.
Now let’s continue training our model based on the definition of the model.
As mentioned earlier, the input word and output word will be one-hot encoded.Upon careful consideration, most dimensions of our input will be 0 after one-hot encoding (actually only one position will be 1), so this vector is quite sparse. What will this result in?If we multiply a 1 x 10,000 vector by a 10,000 x 300 matrix, it will consume a considerable amount of computational resources. To compute efficiently, it will only select the rows in the matrix corresponding to the indices where the vector has a value of 1 (this sentence is a bit convoluted), and the diagram will clarify it.

Let’s look at the matrix operation in the image above. The left side shows a 1 x 5 and a 5 x 3 matrix, and the result should be a 1 x 3 matrix. Following the rules of matrix multiplication, the element in the first row and first column of the result is , and similarly, the other two elements are 12 and 19.If the matrix has 10,000 dimensions, using this calculation method is quite inefficient.
, and similarly, the other two elements are 12 and 19.If the matrix has 10,000 dimensions, using this calculation method is quite inefficient.
To perform calculations effectively, this sparse state will not perform matrix multiplication. It can be seen that the result of the matrix calculation is actually the weights corresponding to the indices where the vector has a value of 1. In the example above, the left vector has a value of 1 in the 3rd dimension (index starting from 0), so the calculation result is the 3rd row of the matrix (index starting from 0)—[10, 12, 19]. This way, the hidden layer weight matrix in the model becomes a “lookup table”; during matrix calculations, it directly retrieves the weight values corresponding to the dimensions where the input vector has a value of 1.The output of the hidden layer is the “embedded word vector” for each input word.
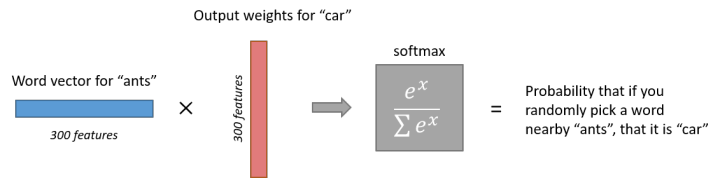
Output LayerAfter the computations in the hidden layer of the neural network, the word “ants” will change from a 1 x 10,000 vector to a 1 x 300 vector, which is then input into the output layer.The output layer is a softmax regression classifier, and each node will output a value between 0 and 1 (probability), with the sum of the probabilities of all output layer neurons equaling 1.The following is an example of a training sample where (input word: “ants”, output word: “car”) is shown in a diagram.
Intuitive UnderstandingNext, we will engage in some intuitive thinking.If two different words have very similar “contexts” (i.e., the window words are very similar, such as “Kitty climbed the tree” and “Cat climbed the tree”), then through our model training, the embedded vectors for these two words will be very similar.
So what does it mean for two words to have similar “contexts”?For example, for the synonyms “intelligent” and “smart”, we think these two words should have the same “context”. Similarly, related words like “engine” and “transmission” may also have similar contexts.In fact, this method can also help you with stemming, for instance, the neural network will learn similar word vectors for “ant” and “ants”.
Stemming is the process of removing affixes to obtain the root word.
— Divider between Part One and Part Two —
Part Two
In the first part, we learned about the input layer, hidden layer, and output layer of the Skip-Gram model.In the second part, we will continue to delve into how to efficiently train on the Skip-Gram model.After completing the explanation in the first part, we will find that the Word2Vec model is a super large neural network (with a very large weight matrix scale).For example, if we have a vocabulary of 10,000 words and want to embed 300-dimensional word vectors, both the input-hidden layer weight matrix and the hidden-output layer weight matrix will have 10,000 x 300 = 3 million weights, and performing gradient descent in such a large neural network is quite slow.Worse still, you need a large amount of training data to adjust these weights and avoid overfitting.A weight matrix on the order of millions and training samples on the order of billions means training this model will be a disaster (too brutal).The authors of Word2Vec emphasized these issues in their second paper, and here are three innovations mentioned by the authors in that paper:
-
Treat common word pairs or phrases as single “words”.
-
Sample high-frequency words to reduce the number of training samples.
-
Use the “negative sampling” method for optimizing objectives, so that each training sample only updates a small portion of the model weights, thereby reducing computational burden.
It has been proven that sampling common words and using “negative sampling” not only reduces the computational burden during training but also improves the quality of the trained word vectors.Word pairs and “phrases”The authors of the paper pointed out that some combinations of words (or phrases) have meanings that are completely different from when they are separated.For example, “Boston Globe” is the name of a newspaper, while the individual words “Boston” and “Globe” do not convey this meaning.Therefore, whenever “Boston Globe” appears in the article, we should treat it as a single word to generate its word vector, rather than separating it.Similar examples include “New York”, “United States”, etc.In the model released by Google, there are 100 billion words in the training samples from the Google News dataset, but in addition to individual words, there are more than 3 million word combinations (or phrases).If you are interested in the model’s vocabulary, you can click here, and you can also browse this vocabulary directly.If you want to know how this model extracts phrases in documents, you can refer to the chapter “Learning Phrases” in the paper, and the corresponding code word2phrase.c has been released here.Sampling High-Frequency WordsIn the explanation of the first part, we demonstrated how training samples are generated from the original document, and I will repeat it here.Our original text is “The quick brown fox jumps over the lazy dog”. If I use a window size of 2, then we can obtain the training samples shown in the diagram.
However, for common high-frequency words like “the”, this processing method has the following two issues:
-
When we obtain paired word training samples, training samples like (“fox”, “the”) do not provide us with more semantic information about “fox” because “the” appears in almost every context of words.
-
Due to the high probability of common words like “the” appearing in the text, we will have a large number of training samples of the form (“the”, …), and these samples far exceed the number of training samples needed to learn the word vector for “the”.
Word2Vec solves the high-frequency word problem through “sampling”.The basic idea is as follows:For each word we encounter in the training original text, there is a certain probability that we will delete it from the text, and this deletion probability is related to the word’s frequency.If we set the window size (i.e.,
(i.e., ), and delete all instances of “the” from our text, then the following results will occur:
), and delete all instances of “the” from our text, then the following results will occur:
-
Since we have deleted all instances of “the” from the text, it will never appear in our context window when “the” is the input word.
-
When “the” is the input word, we will at least reduce 10 training samples.
This sentence should be understood as follows: if our text contains only one “the”, then when this “the” is the input word, setting span=10 will yield 10 training samples (“the”, …). If we remove this “the”, we will reduce 10 training samples.In practice, there is more than one “the” in our text, so when “the” is the input word, we will reduce at least 10 training samples.
The two impacts mentioned above actually help us solve the problems posed by high-frequency words.Sampling RateThe C implementation of word2vec has a formula to compute the probability of retaining a certain word in the vocabulary. is a word,
is a word, is
is the frequency of this word in all corpora.For example, if the word “peanut” appears 1,000 times in a corpus of 1 billion words, then
the frequency of this word in all corpora.For example, if the word “peanut” appears 1,000 times in a corpus of 1 billion words, then .In the code, there is also a parameter called “sample”, which represents a threshold, with a default value of 0.001 (in the gensim package’s Word2Vec class documentation, this parameter defaults to 0.001, and the documentation explains this parameter as “threshold for configuring which higher-frequency words are randomly downsampled”).The smaller this value, the smaller the probability of this word being retained (i.e., the greater the probability of being deleted).
.In the code, there is also a parameter called “sample”, which represents a threshold, with a default value of 0.001 (in the gensim package’s Word2Vec class documentation, this parameter defaults to 0.001, and the documentation explains this parameter as “threshold for configuring which higher-frequency words are randomly downsampled”).The smaller this value, the smaller the probability of this word being retained (i.e., the greater the probability of being deleted). represents the probability of retaining a certain word:
represents the probability of retaining a certain word:
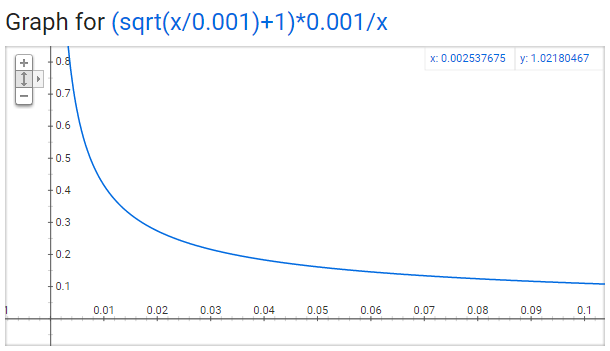
The x-axis in the figure represents the frequency of a word in the corpus, and the y-axis represents the probability of retaining a certain word.For a large corpus, the frequency of a single word will not be very high; even for common words, it cannot be particularly high.From this figure, we can see that as the frequency of a word increases, its probability of being sampled and retained decreases. We can also draw some interesting conclusions:
the frequency of a word in the corpus, and the y-axis represents the probability of retaining a certain word.For a large corpus, the frequency of a single word will not be very high; even for common words, it cannot be particularly high.From this figure, we can see that as the frequency of a word increases, its probability of being sampled and retained decreases. We can also draw some interesting conclusions:
-
When
 ,
, 。When the frequency of a word in the corpus is less than 0.0026, it is 100% retained, meaning that only those words that appear more than 0.26% in the corpus will be sampled.
。When the frequency of a word in the corpus is less than 0.0026, it is 100% retained, meaning that only those words that appear more than 0.26% in the corpus will be sampled. -
When
 ,
, , this means that this part of the words has a 50% probability of being retained.
, this means that this part of the words has a 50% probability of being retained. -
When
 ,
, , this means that this part of the words has a 3.3% probability of being retained.
, this means that this part of the words has a 3.3% probability of being retained.
If you look at that paper, you will find that the authors have some differences in the definition of the function formula and its implementation in C language code, but I believe the C language code’s formula implementation is more authoritative.
Negative Sampling
Training a neural network means inputting training samples and continuously adjusting the weights of the neurons, thereby continuously improving the accuracy of predictions for the target.Each time the neural network goes through a training sample, its weights are adjusted.As discussed above, the size of the vocabulary determines that our Skip-Gram neural network will have a large-scale weight matrix, and all these weights need to be adjusted through billions of training samples, which is very resource-intensive and will be very slow in practice.Negative sampling solves this problem; it is a method used to improve training speed and enhance the quality of the resulting word vectors.Unlike originally updating all weights for each training sample, negative sampling allows a training sample to update only a small portion of the weights, thus reducing the computational load during the gradient descent process.When we use the training sample (input word: “fox”, output word: “quick”) to train our neural network, both “fox” and “quick” are one-hot encoded.If our vocabulary size is 10,000, we expect the neuron node corresponding to the word “quick” in the output layer to output 1, while the other 9,999 should output 0.Here, the 9,999 neuron nodes that we expect to output 0 are referred to as “negative words”.When using negative sampling, we will randomly select a small number of negative words (for example, choosing 5 negative words) to update the corresponding weights.We will also update the weights for our “positive” word (in our example, this word refers to “quick”).
In the paper, the authors note that for small-scale datasets, selecting 5-20 negative words is preferable, while for large-scale datasets, selecting only 2-5 negative words is sufficient.
Recall that our hidden-output layer has a weight matrix of 300 x 10,000.By using negative sampling, we only update the weights corresponding to the positive word “quick” and the 5 negative words we choose, totaling 6 output neurons, which means we only calculate weights.For 3 million weights, this means we only computed 0.06% of the weights, significantly improving computational efficiency.How to Select Negative WordsWe use a “unigram distribution” to select “negative words”.It is important to note that the probability of a word being selected as a negative sample is related to its frequency; the higher the frequency of the word, the more likely it is to be chosen as a negative word.In the C implementation of word2vec, you can see the formula for this probability calculation.The probability of each word being selected as a “negative word” is calculated based on its frequency.The formula implemented in the code is as follows:
weights.For 3 million weights, this means we only computed 0.06% of the weights, significantly improving computational efficiency.How to Select Negative WordsWe use a “unigram distribution” to select “negative words”.It is important to note that the probability of a word being selected as a negative sample is related to its frequency; the higher the frequency of the word, the more likely it is to be chosen as a negative word.In the C implementation of word2vec, you can see the formula for this probability calculation.The probability of each word being selected as a “negative word” is calculated based on its frequency.The formula implemented in the code is as follows: Each word is assigned a weight, which is
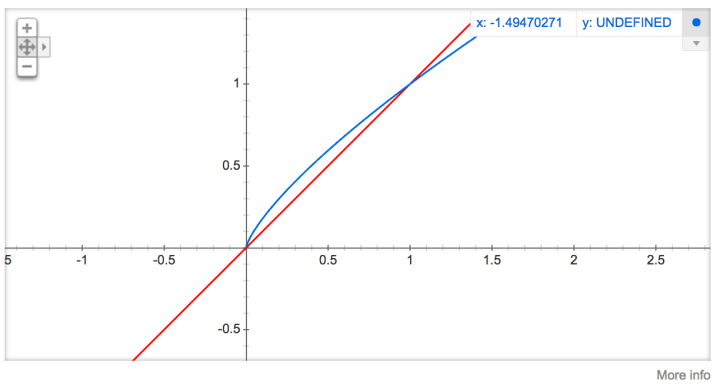
Each word is assigned a weight, which is , which represents the frequency of the word.The formula’s root of 3/4 is entirely empirical, and the paper mentions that this formula performs better than others.You can enter “plot y = x^(3/4) and y = x” into Google’s search bar to see these two graphs (as shown below) and carefully observe the values of y when x is in the range [0,1],
, which represents the frequency of the word.The formula’s root of 3/4 is entirely empirical, and the paper mentions that this formula performs better than others.You can enter “plot y = x^(3/4) and y = x” into Google’s search bar to see these two graphs (as shown below) and carefully observe the values of y when x is in the range [0,1], which will show a small arc segment, with values above
which will show a small arc segment, with values above the function.
the function.
The negative sampling implementation in C language is very interesting.The unigram table has an array containing 100 million elements filled with the index numbers of each word in the vocabulary, and this array has duplicates, meaning some words will appear multiple times.So how do we determine how many times each word’s index appears in this array? There is a formula: , meaning the calculated negative sampling probability * 100 million = the number of times the word appears in the table.With this table, each time we perform negative sampling, we only need to generate a random number in the range of 0-100 million and select the word corresponding to that random number’s index in the table as our negative word.The higher the negative sampling probability of a word, the more frequently it appears in this table, and the greater its probability of being selected.So far, the Skip-Gram model in Word2Vec has been covered, and I haven’t delved into the specific mathematical formula derivation details.This article only elaborated on some ideas regarding implementation details.
, meaning the calculated negative sampling probability * 100 million = the number of times the word appears in the table.With this table, each time we perform negative sampling, we only need to generate a random number in the range of 0-100 million and select the word corresponding to that random number’s index in the table as our negative word.The higher the negative sampling probability of a word, the more frequently it appears in this table, and the greater its probability of being selected.So far, the Skip-Gram model in Word2Vec has been covered, and I haven’t delved into the specific mathematical formula derivation details.This article only elaborated on some ideas regarding implementation details.
Recommended Reading:
Practical | Pytorch BiLSTM + CRF for NER
How to Evaluate the FastText Algorithm Proposed by the Author of Word2Vec? Does Deep Learning Have No Advantage in Simple Tasks Like Text Classification?
From Word2Vec to Bert, Let’s Talk About the Past and Present of Word Vectors (Part 1)
