Source: Submission Author: Aksy
Editor: Senior Sister
Video Link: https://ai.deepshare.net/detail/p_5ee62f90022ee_zFpnlHXA/6

Article Title: Efficient Estimation of Word Representations in Vector Space Author: Tomas Mikolov (First Author) Unit: Google Conference and Time: ICLR 2013
1. Research Background
1.1 Prior Knowledge
Mathematics Knowledge:
-
Calculus in Advanced Mathematics -
Matrix Operations in Linear Algebra -
Conditional Probability in Probability Theory
Machine Learning:
-
Basic principles and concepts in machine learning, such as logistic regression classifiers, gradient descent methods, etc.
Neural Networks:
-
Understanding basic knowledge of neural networks -
Knowing the concepts of feedforward neural networks and recurrent neural networks -
Understanding the concept of language models
Programming:
-
Understanding the basic usage of Pytorch, such as data reading, model building, etc.
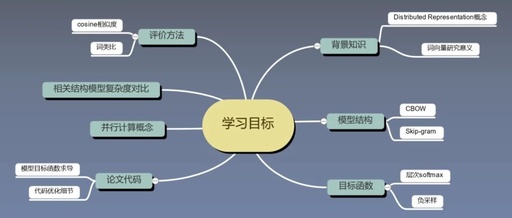
1.2 Learning Objectives
| Serial Number | Title | Content |
|---|---|---|
| 1 | Understand the Background Knowledge of Word Vectors | Historical Background, Mathematical Foundation |
| 2 | Understand Previous Work | SVD, Feedforward Neural Networks, RNN Language Models |
| 3 | Master Evaluation Methods for Word Vectors | Cosine/Analogy: Similarity/Word Pair Analogy, Datasets in the Paper |
| 4 | Master Model Structure | CBOW, Skip-gram |
| 5 | Key Techniques in Word2vec: Speeding Up Training | Hierarchical Softmax, Negative Sampling |
| 6 | Master the Word2vec Code | Key Code, Efficiency Improvement Details |
Comparison Models: NNLM, RNNLM (LM: Language Model)
2. Background Knowledge of Word Vectors
2.1 Language Models
Intuitive Concept: A language model is a model that calculates the probability of a sentence being a sentence, that is, given a sentence, it judges whether it conforms to semantics and grammar; sentences that conform to both have a higher probability.
Example:
| Sentence | Probability | Analysis |
|---|---|---|
| The paper class of Deep Eye is really good! | 0.8 | Conforms to semantics and grammar |
| The paper class of Deep Eye is really average! | 0.01 | Does not conform to semantics because the class of Deep Eye is better |
| The paper class of Deep Eye is really good! | 0.000001 | Does not conform to grammar, therefore also does not conform to semantics |
The applications of language models are many; for example, when inputting pinyin in an input method: zi ran yu yan chu li, it returns the corresponding Chinese result, which is a language model.
| Sentence | Probability |
|---|---|
| Natural Language Processing | 0.9 |
| Child-like Prophesy Output | 0.01 |
| Purple-like Jade Eye Storage Example | 0.0001 |
2.2 Development of Language Models
This section discusses how to construct a language model?
2.2.1 Language Models Based on Expert Grammar Rules
Linguists attempt to summarize a set of universal grammar rules, such as adjectives following nouns, verbs followed by adverbs, etc.; sentences that conform to these rules are valid. The downside is that language is ever-changing and it is difficult to summarize a universal grammar rule. Moreover, with the passage of time, new words emerge, making it challenging to summarize parts of speech, for example, “laughing is none of your business.”
2.2.2 Statistical Language Models
Statistical language models characterize language models through probability calculations: transforming the probability of a sentence into the product of the probabilities of all the words appearing.
Method for Calculating the Probability of a Word:
Solution Method: Use the frequency of the corpus to replace probability (Frequency School)
Statistical language models are constructed using a very large corpus, known as background corpus. Through the formula shown above, the frequency of each word can be calculated, using frequency to replace probability.
Solution Method: Frequency School + Conditional Probability
Example of Language Model:
-
P(Zhang San is very handsome) = P(Zhang San) * P(very | Zhang San) * P(handsome | Zhang San, very) -
P(Zhang is very handsome) = P(Zhang is very handsome) * P(very | Zhang is very handsome) * P(handsome | Zhang is very handsome, very): Zhang is very handsome is a rare name, it may not have appeared in the corpus, but this does not mean it does not exist, P(Zhang is very handsome) = 0 is unreasonable. -
P(Zhang San is very beautiful) = P(Zhang San) * P(very | Zhang San) * P(beautiful | Zhang San, very): Longer sentences (phrases) may also have low probabilities in the corpus, such as Zhang San’s classmate’s sister’s friend’s good friend is very beautiful.
Smoothing Operations in Statistical Language Models
-
Some words or phrases may not have appeared in the corpus, but this does not mean they do not exist. -
Smoothing operations assign a small probability to those words or phrases that have not appeared. -
Laplace Smoothing ( Laplace Smoothing): Also known as add-one smoothing, adds one to each word’s original occurrence count.
Example:

Indicates the number of words in the corpus
Disadvantage: Mainly solves the word problem; if longer phrases appear, the number of words and phrases needing smoothing increases significantly.
Example: Assume the corpus only contains one sentence, Zhang San is very beautiful.
-
P(Zhang San is very handsome) = P(Zhang San) * P(very | Zhang San) * P(handsome | Zhang San, very) -
P(Zhang San is very table) = P(Zhang San) * P(very | Zhang San) * P(table | Zhang San, very) -
After smoothing, P(handsome | Zhang San, very) = P(table | Zhang San, very), meaning the probabilities of the two sentences are equal. However, the second sentence is unreasonable; generally, the probability of the first sentence should be higher than that of the second.
The issue with smoothing operations could lead to a grammatically incorrect sentence having the same probability as a correct one.
Reason for the Problem:
-
Parameter Space Too Large: The parameters related to the model can be numerous. For example: calculating parameters have (one for each parameter), representing the vocabulary size, and calculating parameters have (one for each numerator), and so on, leading to a model parameter space of:
.
-
Severe Data Sparsity: After smoothing, the probabilities of rarely occurring words are small. When fewer words account for a larger proportion, the data becomes very sparse. Ultimately, most data values approach zero, with only a few not equal to zero. Similarly, a large computational load can lead to issues, such as data being too sparse. This is because we want to consider many preceding words for each word, and the probabilities of combining many words together are not actually high. The more words combined, the more sparse the data becomes.
Solution: Markov Assumption
Markov Assumption: The occurrence of the next word depends only on the previous one or a few words.
Language Model Example: I played badminton this afternoon.
2.3 Evaluation Metrics for Language Models
Perplexity
A language model is essentially a multi-class classification problem concerning vocabulary size, with each class being a word. The larger the sentence probability, the better the language model, and the smaller the perplexity.
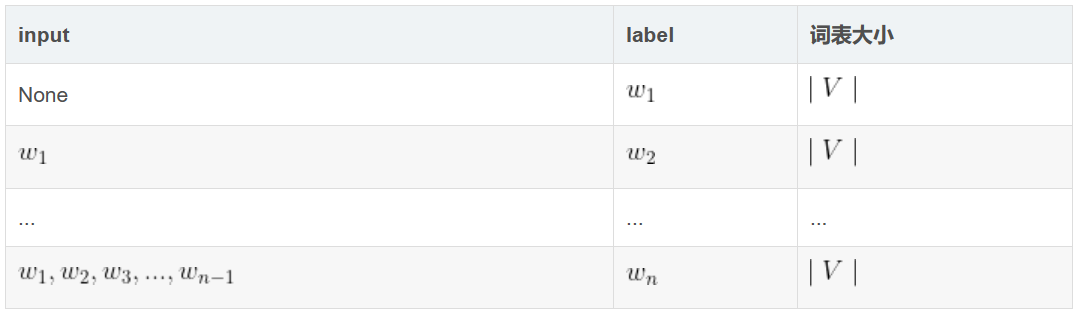
The language model can only determine the probability of a sentence being a sentence; it is not a complete supervised learning method. The smaller the perplexity, the larger the corresponding sentence probability, indicating that the probabilities of each class in the vocabulary size multi-class classification problem are larger. The smaller the perplexity, the better.
2.4 n-gram Features
In text feature extraction, n-grams are often seen. It is an algorithm based on language models, with the basic idea being to perform a sliding window operation of size N on the text content in byte order, ultimately forming a sequence of byte segments of length N. See the example below:
I came to visit the data.
-
The corresponding bigram features are: I came, came to, to visit, visit the, the data. -
The corresponding trigram features are: I came to, came to visit, to visit the, visit the data.
Note: The term “gram” in n-grams has different meanings based on granularity. It can be byte-granularity or word-granularity. The examples given above are byte-granularity n-grams, while word-granularity n-grams are shown in the example below:
I came to visit the data.
-
The corresponding bigram features are: I/ came, came/ to, to/ visit the data. -
The corresponding trigram features are: I/ came/ to visit the data, came/ to visit the data/.
The features produced by n-grams are only a candidate set of text features; you may later use information entropy, chi-square statistics, IDF, and other text feature selection methods to filter out more important features.
3. Paper Overview
3.1 Background Knowledge of the Paper
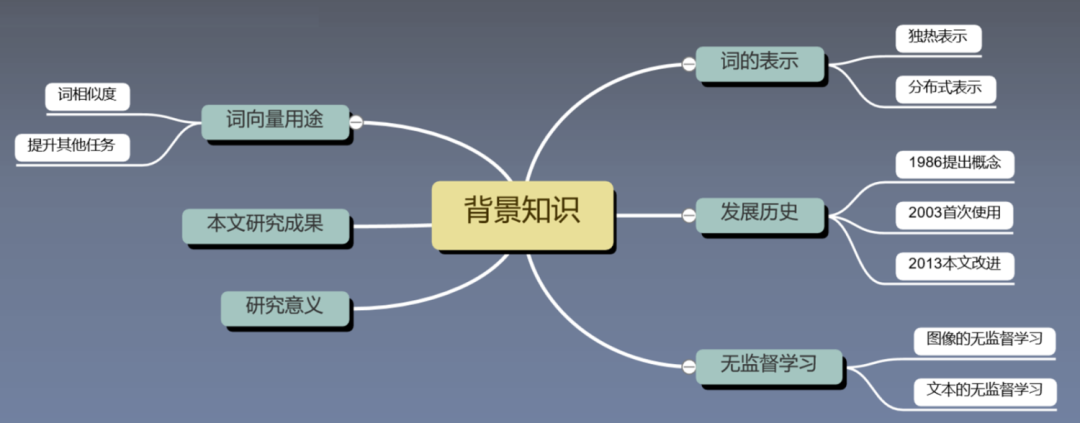
3.1.1 Representation of Words
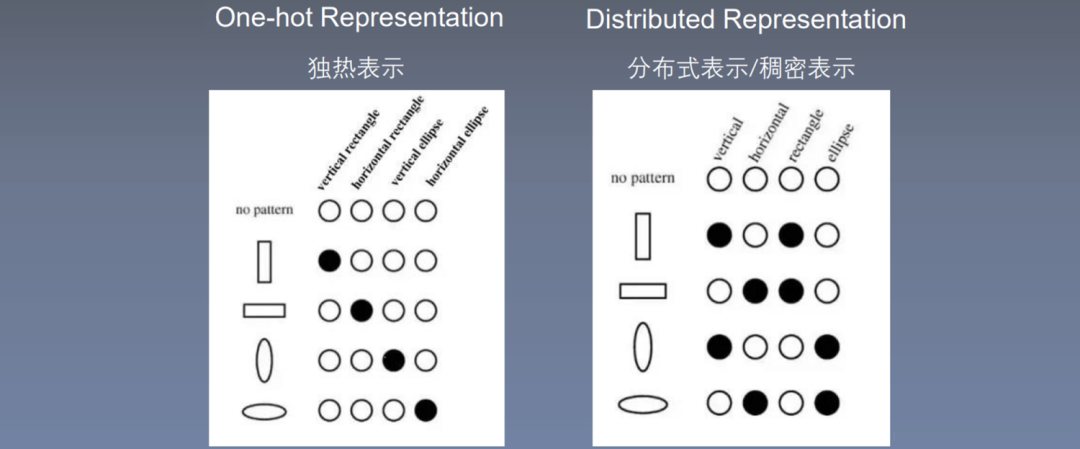
1. One-hot Representation
For example, representing “microphone” as: [0, 0, 0, 0, 1, 0, 0,……], representing “microphone” as [0, 0, 1, 0, 0, 0, 0, ……], etc.
-
Advantages: Simple representation. -
Problems: As the number of words increases, the dimensionality increases, with the dimension equal to the vocabulary size V, and it cannot represent the relationships between words.
2. SVD
This method is based on a window-based co-occurrence matrix (Window based Co-occurrence Matrix), where a word is only related to the words within a specific window around it; if two words co-occur, it adds one. For example: 1) I enjoy flying. 2) I like NLP. 3) I like deep learning.
First, set the diagonal to 0, then construct a co-occurrence matrix with a window size of 1. Through co-occurrence, certain similar relationships can be reflected, for example, both and are adjacent to , but this matrix size is still related to vocabulary size, has a high dimension, and is quite sparse. Therefore, dimensionality reduction is needed: .
The first method of using word vectors involves SVD decomposition. SVD decomposition can obtain the similarity between words to a certain extent, but the matrix is too large, SVD decomposition is inefficient, and the learned word vectors have poor interpretability.
Decomposing a matrix into three parts, , , , all three dimensions are equal to the matrix dimensions. Only the diagonal elements are non-zero, representing the importance of the features in the matrix. Generally, the feature values are sorted from largest to smallest, so the top features can be retained. Correspondingly, only the top vectors can be retained.
Retaining the top:
Each word is represented by a dimensional vector,
Advantages: Can obtain the similarity between words to a certain extent.
Disadvantages: The matrix is too large, SVD matrix decomposition is inefficient, and the learned word vectors have poor interpretability. Because some unimportant information is discarded, it cannot explain the reasons for the unimportance, similarly, important information cannot explain its importance.
3. Distributed Representation/Dense Representation, also known as Word Vectors/Word Embedding – Proposed in this paper
Its dimension is no longer the size of the dictionary, and the numbers in each dimension are no longer 0; these relationships between numbers are obtained through training, and the trained word vectors can bring similar words closer together.

Each word is represented as a dimensional vector, D<<V. Similar to 10,000 people, 10,000 positions, compressed into 300 positions, training forces similar people together to save space. This is equivalent to using a 300-dimensional space to accommodate 10,000-dimensional space words, forcing similar words to be together, exhibiting very good properties. Dimensionality reduction to two dimensions can represent the relationship between two words using cosine similarity.
Reference Link:
Quora: https://www.quora.com/Deep-Learning-What-is-meant-by-a-distributed-representation
3.1.2 Development History
-
1996: Hinton proposed Distributed Representation in 1986. -
2003: Bengio first used word vectors in A Neural Probabilistic Language Model, training word vectors using language training methods, achieving good results. -
2003-2013: Many methods for training word vectors were proposed, but they were slow and similar to SVD, unable to train on large corpora. -
2013: This paper improved open-source word2vec, achieving very fast training speeds and capable of training on large corpora.
3.2 Research Achievements of This Paper
-
Proposed a new model structure word2vec. -
Proposed optimization training methods to speed up training. -
Provided training code for word2vec, enabling single-machine training. -
Results: The trained word vectors are both fast and of good quality, and can be trained on large-scale corpora.
3.3 Research Significance
Research significance:
-
Measure the similarity between word vectors: cosine similarity and word analogy. -
As a pre-trained model to improve NLP tasks.
1. Measure the similarity between word vectors, which is also an evaluation method: cosine similarity and word analogy.
1) Cosine Similarity:
Subjective validation: For example, finding similar word vectors for frog, all are frogs.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| frog | frogs | toad | litoria | leptodactylidae | rana | lizard | eleutherodactylus |

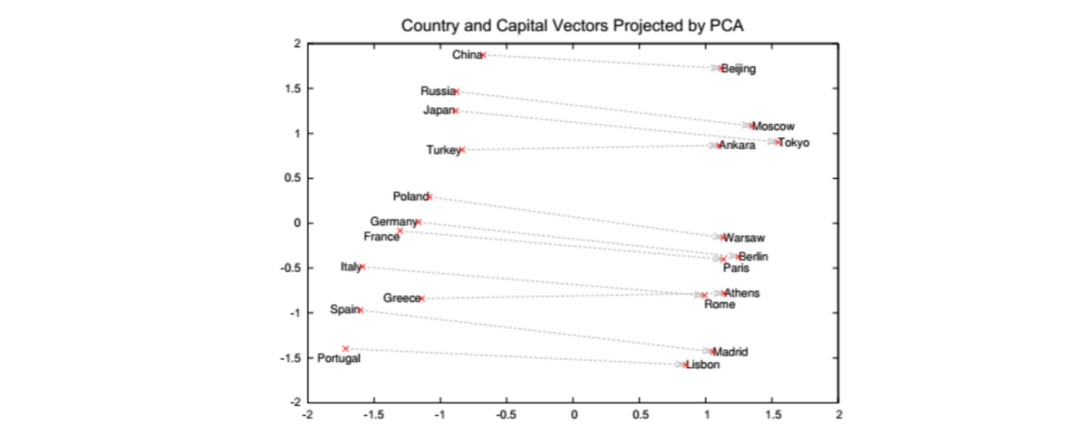
2) Word Analogy (Semantic Relationship):
Verification of method effectiveness, the relationship between country and capital: calculate France – Paris + Rome, check the closest word vector to the result; if it is Italy, the method is effective.
-
France Paris -
Italy Rome
W(“woman”)-W(“man”)=W(“aunt”)-W(“uncle”) W(“woman”)-W(“man”)=W(“queen”)-W(“king”)
Reference Links:
https://nlp.stanford.edu/projects/glove/
http://www.fit.vutbr.cz/~imikolov/rnnlm/word-test.v1.txt
2. As a pre-trained model to improve the accuracy and effectiveness of downstream NLP tasks.
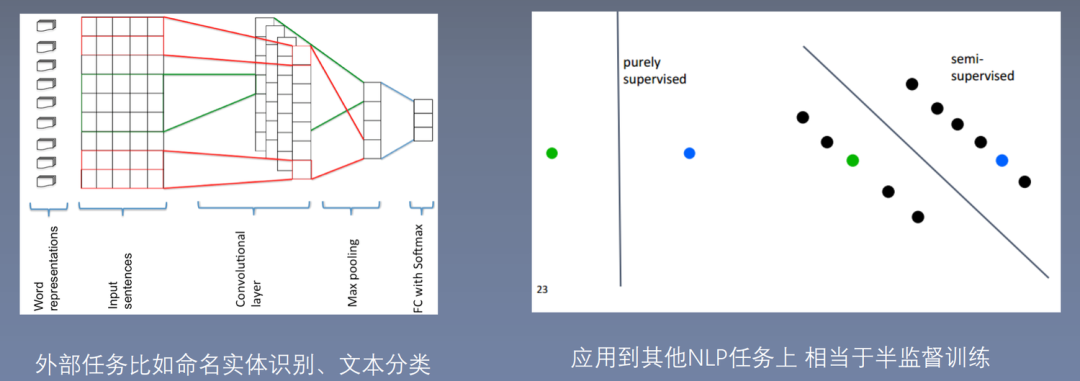
1) External tasks such as named entity recognition, text classification.
2) Applied to other NLP tasks, equivalent to semi-supervised training.
3) Bilingual word embeddings, Word embedding, similar to Chinese-English dictionaries.

Reference Links:
https://nlp.stanford.edu/~socherr/SocherGanjooManningNg_NIPS2013.pdf
3.4 Overview of the Paper
| Serial Number | Title | Content |
|---|---|---|
| Abstract | Proposed two new efficient computation structures for word vectors and validated the effectiveness using word similarity tasks. | |
| 1 | Introduction | Introduced the background of word vectors; the goals of this paper; previous work. |
| 2 | Model Architectures | LSA/LDA; Feedforward Neural Networks; Recurrent Neural Networks; Parallel Network Computing. |
| 3 | New Log-linear Models | Introduced two new model structures: CBOW, Skip grams. |
| 4 | Results | Described evaluation tasks; maximized accuracy; compared model structures; parallel computing of large data on models; Microsoft Research sentence completion competition. |
| 5 | Examples of the Learned Relationships | Examples: The relationships learned between words. |
| 6 | Conclusion | Conclusion: High-quality word vectors; high-efficiency training methods; as pre-trained word vectors applied to other NLP tasks can enhance effectiveness. |
| 7 | Follow-Up Work | Subsequent work: C++ single-machine code. |
| 8 | References | References. |
This article actually discusses two papers:

4. General Reading of the Paper
4.1 Abstract
-
Proposed two novel model structures for computing word vectors. -
Used a word similarity task to evaluate and compare the quality of word vectors. -
Significantly reduced model computation load can enhance word vector quality. -
Furthermore, on our semantic and syntactic tasks, our word vectors achieve the best performance currently.
4.2 Introduction
-
Traditional NLP treats words as the smallest units and can achieve good results on large corpora, one example being the n-grams model. -
However, many natural language processing tasks can only provide very small corpora, such as speech recognition and machine translation; simply expanding the data scale to improve the performance of simple models is no longer applicable in these tasks, so we must seek more advanced models. -
Distributed representation can train good language models on large corpora and can outperform n-grams models, making it a promising technology for improvement.
4.3 Evaluation Methods for Word2vec Word Vectors
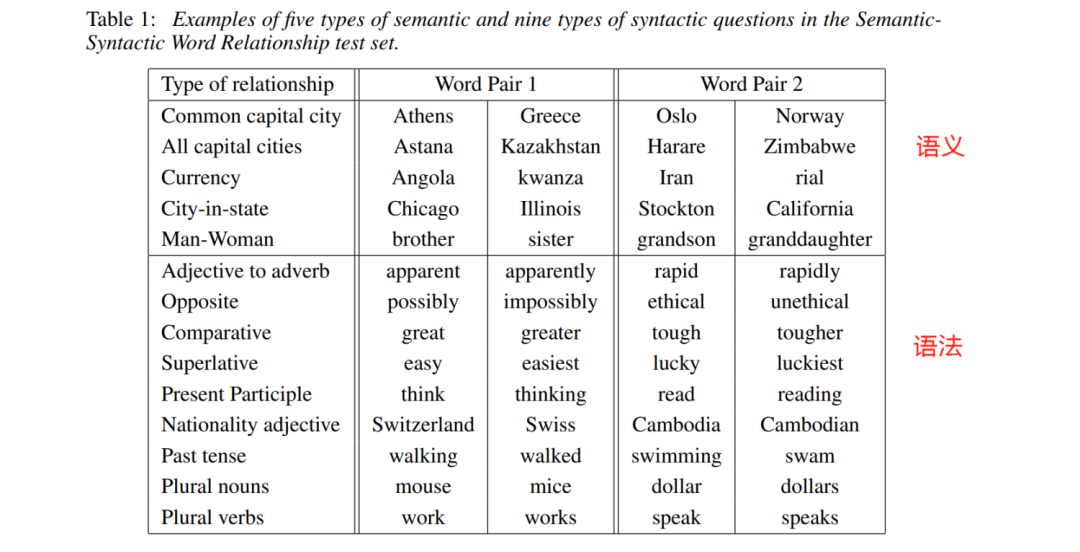
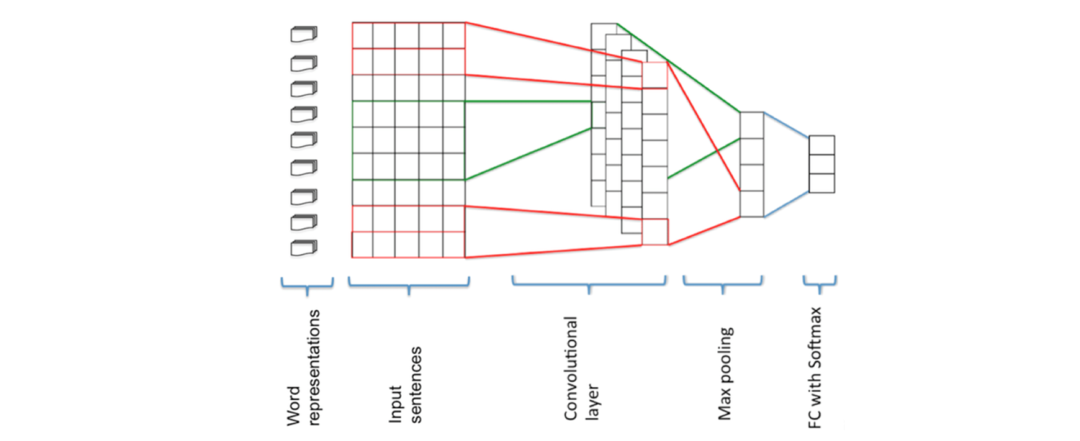
Internal task evaluation: train what task to evaluate what task. The following image shows five types of semantic and nine types of grammatical evaluations.
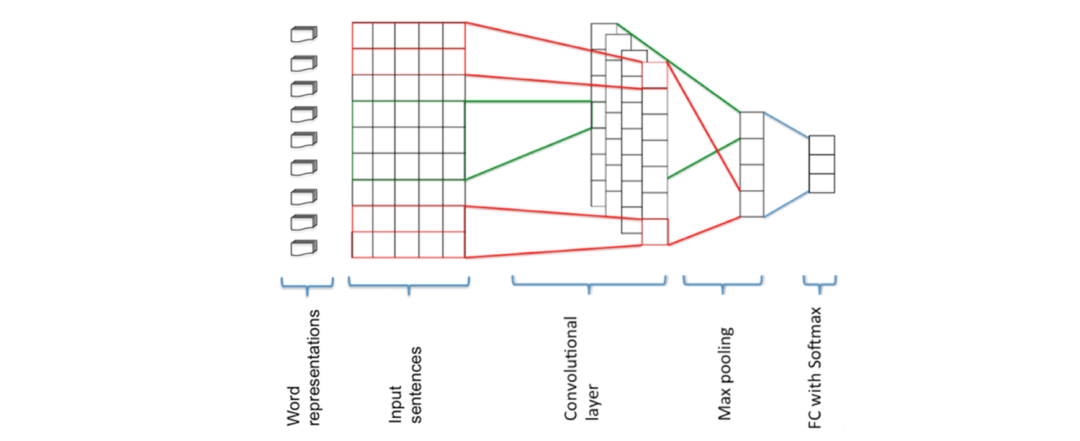
External task evaluation: External tasks such as named entity recognition, text classification.
The remaining part will be in the next post!!

Click here👇 to follow me, I update AI technical content every Tuesday!
Previous Highlights
👉Kaggle Competition Baseline Collection
👉Classic Paper Recommendations Collection
👉Must-Read Books on Artificial Intelligence
👉Learning Experiences for Undergraduate and Graduate Studies