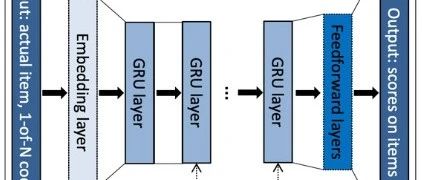
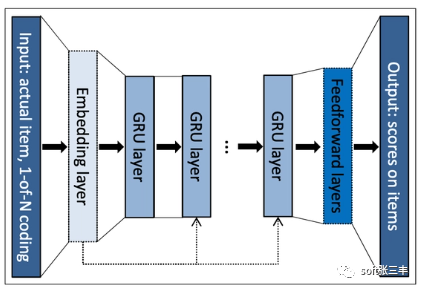
word2vec
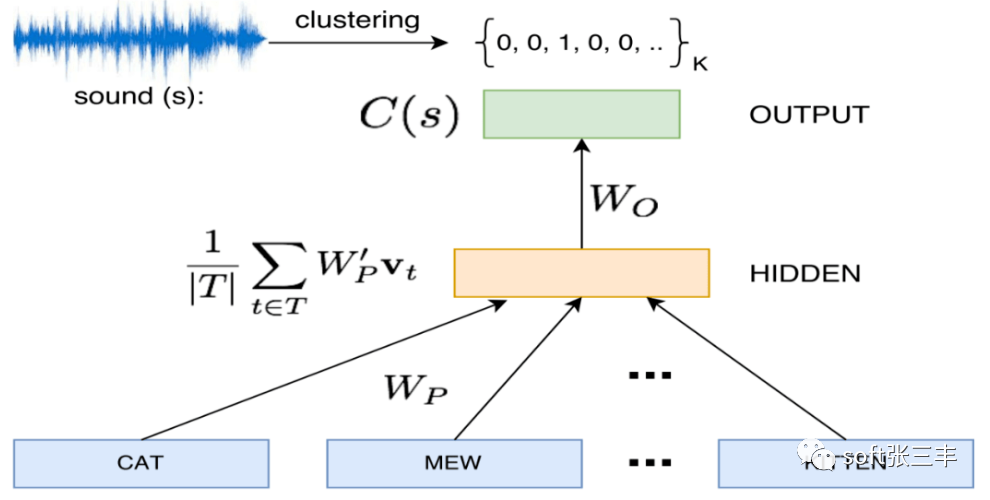
Word2Vec is a model used to generate word vectors. These models are shallow, two-layer neural networks trained to reconstruct linguistic word texts.The network represents words and needs to predict the input words in adjacent positions. In Word2Vec, under the bag-of-words model assumption, the order of words is not important. After training, the Word2Vec model can be used to map each word to a vector, which can represent the relationships between words. These vectors are the hidden layers of the neural network.
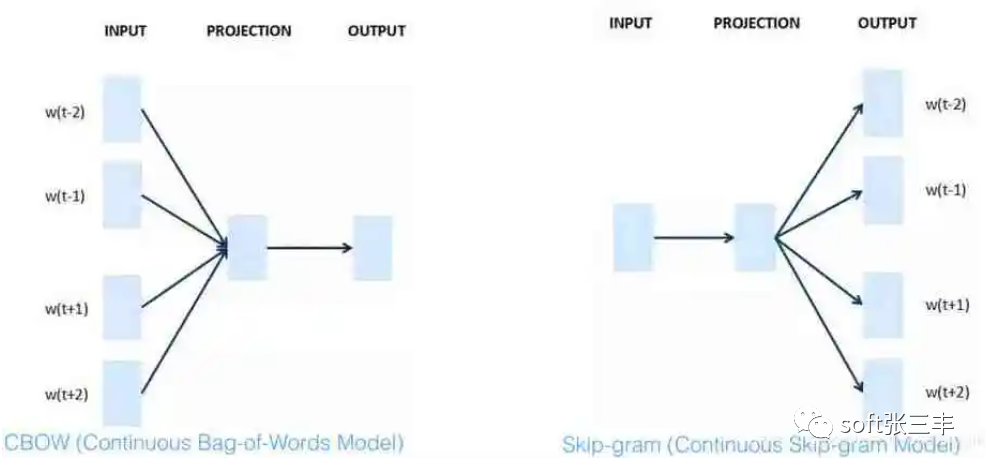
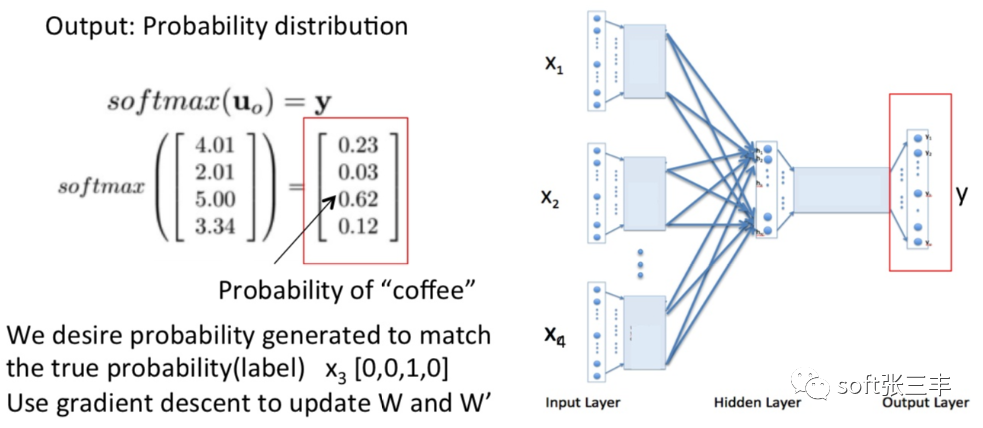
Word2Vec is a technique for converting words in text into vector representations. It is a neural network-based model that maps words to vector representations in high-dimensional space through training. Word2Vec has two main model architectures: CBOW (Continuous Bag of Words) and Skip-gram.The CBOW model attempts to predict the target word given the words in the context, while the Skip-gram model tries to predict the context words given the target word. Both models use a shallow neural network to learn the relationship between inputs and outputs to obtain vector representations of words. The main function of Word2Vec is to convert words into vector representations, enabling computers to better understand and process natural language. With Word2Vec, we can perform tasks such as word similarity calculations, word clustering, and relationship analysis between words. Additionally, Word2Vec can be applied in areas like text classification, semantic search, and information retrieval. By representing words in text as vectors, Word2Vec can capture the semantic and syntactic relationships between words, providing more semantic information and context understanding capabilities.
Main functions include
Word2Vec is an algorithm used to express vocabulary as vectors. By training on a large-scale text corpus, it maps each word to a fixed-length vector, such that words with similar semantics are closer in vector space.The main functions of Word2Vec include: 1. Word Embedding: Word2Vec represents words as vectors, transforming discrete symbols into continuous real-number vectors. This representation captures the semantic and syntactic relationships between words. 2. Semantic Similarity Calculation: Based on the word vectors obtained from Word2Vec training, the similarity between different words can be calculated. By computing the distance between vectors, words with similar semantics can be identified. 3. Word Inference: The vector representation of Word2Vec allows for simple word inference. For example, one can find the vector corresponding to “king” through vector operations, then find the vectors corresponding to “man” and “woman,” ultimately obtaining the vector corresponding to “queen.” 4. Word Clustering and Classification: Based on the word vectors obtained from Word2Vec training, clustering or classification algorithms can be used to group or classify words, facilitating automated processing and analysis of text. In summary, the main function of Word2Vec is to represent words as vectors and use the distances and relationships between vectors for tasks such as word similarity calculation, word inference, and word clustering and classification in natural language processing.
Common Open Source Word2Vec Implementations
Common open-source Word2Vec implementations include: 1. Google’s Original Word2Vec This is the original implementation of the Word2Vec algorithm, open-sourced by the Google team, which includes the C language implementations of word2vec and word2phrase. word2vec supports both CBOW and Skip-gram models. 2. Gensim Word2Vec This is the most commonly used Word2Vec implementation in Python, based on Google’s original Word2Vec, providing a more user-friendly interface. It supports asynchronous training and can easily handle large-scale texts. 3. Deeplearning4j Word2Vec This is a Java implementation of Word2Vec that supports creating, training, and persisting Word2Vec models. It can load pre-trained word vectors from Google. 4. Spark Word2Vec This is a distributed Word2Vec implementation based on Spark, which can utilize Spark for large-scale distributed parallel training. 5. TensorFlow Word2Vec TensorFlow also includes an implementation of Word2Vec, which can be used to build more complex neural network models. 6. FastText Open-sourced by Facebook, it extends Word2Vec to support subword information, resulting in higher training efficiency. 7. PaddlePaddle Word2Vec This is the Word2Vec implementation in Baidu’s PaddlePaddle deep learning platform.
8. PyTorch Word Embeddings
This is the Word2Vec implementation using the PyTorch framework, which can be easily integrated with other deep learning models.
9. TensorFlow and Keras
Both of these open-source deep learning libraries provide implementations of Word2Vec. These implementations allow you to use Word2Vec as part of a neural network model, which can be combined with other types of layers.
These open-source Word2Vec implementations cover mainstream programming languages and can be selected based on needs.
The Relationship Between Tokenizers and Word2Vec
The relationship between tokenizers and Word2Vec mainly reflects in the text processing workflow.A tokenizer is a tool that divides continuous text into a series of words or vocabulary. In many natural language processing tasks, such as information retrieval, text classification, sentiment analysis, etc., it is necessary to first tokenize the text. Meanwhile, Word2Vec is a model used to generate word vectors. Word vectors transform words into real-number vectors, ensuring that semantically similar words are also close in vector space. This plays an important role in further text processing, such as text similarity calculation and text clustering.
The relationship between tokenizers and Word2Vec is: 1. The tokenizer is the input preprocessing module for Word2Vec. The Word2Vec algorithm requires training on a word basis, while natural language text is typically a continuous sequence of characters. Therefore, it is first necessary to use a tokenizer to segment the text into a sequence of words, serving as input for Word2Vec. 2. The quality of tokenization directly affects the training effectiveness of Word2Vec. Whether the tokenization is accurate will directly determine whether the word vectors learned by the Word2Vec model are reasonable. A good tokenizer can provide high-quality input for training Word2Vec. 3. Different languages require different tokenizers. For instance, Chinese requires a Chinese tokenizer, while English can be tokenized by spaces. Word2Vec needs the corresponding tokenizer as a preprocessing module when applied to different languages. 4. Some Word2Vec implementations have built-in tokenization functionality. For example, Gensim’s Word2Vec includes a simple English tokenizer that can directly tokenize English text and then train. 5. Tokenizers and Word2Vec can be used in tandem. One can first use a suitable tokenizer to segment the text, and then input the tokenized results into Word2Vec for training. This tandem usage process is quite common. 6. Tokenizers and Word2Vec can also be jointly trained. Some recent studies have integrated tokenization and Word2Vec into an end-to-end learning framework, achieving joint optimization of tokenization and representation learning. Overall, tokenization is a key input for Word2Vec, and selecting an appropriate tokenizer is crucial for the effectiveness of Word2Vec.
You might also like:
[Low Open] Data Model Driven by Low Open Platform
[Open Source] Real-time CDC and Batch Synchronization of Massive Data, Can Stably and Efficiently Synchronize Trillions of Data
[Open Source] The Simplest Recommendation Algorithm, Collaborative Filtering
[Open Source] Data Desensitization
[Open Source] Vector Database
Add WeChat to join the relevant group chat,
Note “Microservices” to join the group for discussion
Note “Low Open” to join the low open group for discussion
Note “AI” to join the big data, data governance group for discussion
Note “Digital” to join the IoT and digital twin group for discussion
Note “Business” for business communication

Follow the public account soft Zhang Sanfeng 