Reading time: approximately 5 minutes
Follow the little blogger and improve a bit every day


Author: gan Link: https://zhuanlan.zhihu.com/p/36312907
Background Introduction and Some Intuitive Understandings
Word2Vec is a word vector model proposed by Google in 2012, which includes two models, Continuous Bag of Words (CBOW) and Skip Gram. The two models build word prediction models from two perspectives: CBOW predicts the target word based on the context of one or more words, while the Skip Gram model predicts the context based on one or more words.
First, we need to understand why we need to encode words, which is called word vectorization. We know that any mathematical model requires numerical inputs, but in natural language processing, we are dealing with text, and text cannot be used directly by mathematical models. Therefore, we need to encode text, which means giving each character a vector representation. Before Word2Vec came out, we mainly used the one-hot encoding method, which represents each word with a vector where one position is 1 and the rest are 0. The dimension of the vector is equal to the size of our vocabulary. Each position in the vector can only represent a unique word. For example, if our vocabulary has only 10 words: today, is, you, I, he, buy, water, fruit, home. Using one-hot encoding, we would get the following results:

As we can see, each word is represented by a unique vector. However, this representation method has some deficiencies:
-
Under common distance metrics, the distance between words is indistinguishable, meaning the distance between “today” and “is” is the same as the distance between “today” and “fruit”.
-
As the vocabulary increases, the dimension of the vector also increases, and there is no unique vector corresponding to new words not in the vocabulary.
-
When the vocabulary is large, i.e., the vector dimension is too high, it inevitably increases the computational load of any machine learning model, reducing computational efficiency…
Therefore, the purpose of proposing word vectors is to solve the above-mentioned problems. The main characteristics of word vectors are as follows:
-
If the vocabulary size is N, then each word can be represented by an n-dimensional vector, where n is much smaller than N. Commonly, n ranges from 100 to 300, or can be set based on specific needs.
-
Each position in the word vector can take any real number, rather than just 0 or 1.
-
The differences between word vectors are meaningful to some extent. For example, if the word vector for China is v1, the vector for Beijing is v2, the vector for the USA is s2, and the vector for Washington is s2, the word vectors learned through Word2Vec exhibit such characteristics
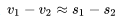 This is a beautiful approximate relationship, meaning that v1-v2 is approximately equal to the capital relationship, which has inspired some encoding algorithms called Trans in knowledge graph representation learning.
This is a beautiful approximate relationship, meaning that v1-v2 is approximately equal to the capital relationship, which has inspired some encoding algorithms called Trans in knowledge graph representation learning. -
Moreover, the distance between place names in the word vector space is closer than the distance between place names and animal word vectors, etc. In other words, the distances between word vectors describing the same attributes and categories are smaller than those between different attributes and categories.
Introduction to the CBOW Model
As mentioned earlier, the CBOW model is used for predicting a word based on its context. In other words, given the context of one or more words, we hope to make a probabilistic prediction of all words in the vocabulary, and the probability of the word we want to predict should be as high as possible. This falls perfectly into the realm of maximum likelihood estimation. If we have a lot of contexts and one or more words to predict, since our model has a probability estimate for each word, we can multiply their probabilities based on our existing samples and maximize this probability by adjusting the model parameters.
One Context Predicting One Word
Let’s start with the simplest case; understanding this will make it straightforward to extend to other complex situations. We can use two simple sentences as examples:
-
“He is very happy today.”
-
“She seems not very happy.”
Generally, when training word vectors in Chinese, sentences are tokenized. Here, I have separated the words with spaces, but I won’t discuss tokenization here. In the CBOW model, there is a window parameter, which defines the context as being within a certain distance from the target word. Let’s set the window size to 2. According to this rule, we can generate the following training samples, where the first position is the context and the second position is the target word.


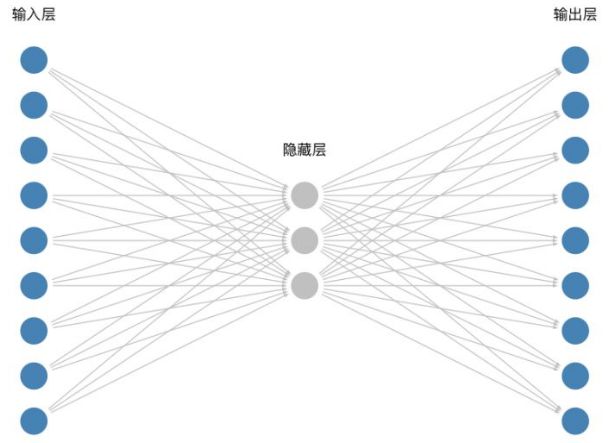
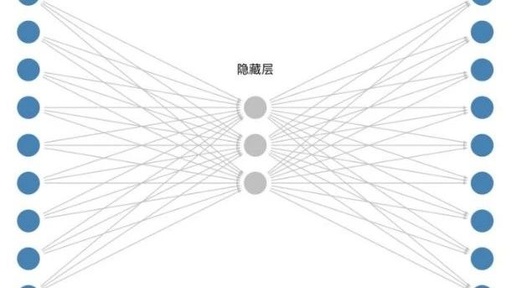
The transformation from the input layer to the hidden layer can be represented by a 9×3 matrix, initialized as follows:

From the hidden layer to the output layer, we can represent it with a 3×9 matrix, initialized as follows:

With these symbols, let’s see what happens when our first sample (today, he) passes through our model. Because today = 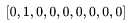 , the transformation from the input layer to the hidden layer involves matrix multiplication:
, the transformation from the input layer to the hidden layer involves matrix multiplication:

And 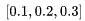 is the encoding for “today” under CBOW. Of course, since these are just initialized values, the model will adjust these values as training samples are processed to obtain the final true encoding for “today”.
is the encoding for “today” under CBOW. Of course, since these are just initialized values, the model will adjust these values as training samples are processed to obtain the final true encoding for “today”.
Continuing from the hidden layer to the output layer, we perform matrix multiplication again, resulting in:

After applying softmax, we find that the predicted probabilities for each word are all 19, while our training sample hopes that the probability corresponding to “he” should be as high as possible, ideally 1, with the probabilities for other words being 0. If there is a deviation between the model’s output and the real sample, we can use this error to perform backpropagation and adjust our model parameters , thus achieving the purpose of learning and tuning.
, thus achieving the purpose of learning and tuning.
If we look back at the calculation process, we can interpret the matrices as follows:
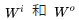 For each word v, we assign two encodings, denoted as
For each word v, we assign two encodings, denoted as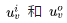 Assuming these vectors are column vectors, then
Assuming these vectors are column vectors, then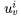 forms the row corresponding to word v in the matrix
forms the row corresponding to word v in the matrix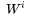 and the column corresponding to word v in the matrix
and the column corresponding to word v in the matrix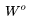 The probability of predicting word s from word v is calculated using the following formula:
The probability of predicting word s from word v is calculated using the following formula:
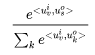
where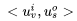 is the dot product of the two vectors. Now that we have a series of observed samples,
is the dot product of the two vectors. Now that we have a series of observed samples, 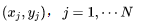 based on the above analysis, we can construct the likelihood function based on these samples:
based on the above analysis, we can construct the likelihood function based on these samples:
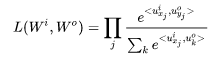
Taking the logarithm gives us:
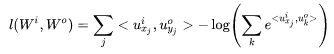
So in the end, we are actually maximizing the likelihood function. Why is it said that calculating the likelihood function is complex? As you can see, the summation term in the logarithm needs to iterate through all words, meaning if we have 10,000 words in our vocabulary, each iteration requires 10,000 calculations. What if the vocabulary has 1 million, 10 million, or even a hundred million words? You can imagine the computational load is quite significant. Therefore, a series of methods have been developed to approximate this calculation, which we will also introduce later, such as hierarchical softmax and negative sampling, which aim to solve this computational efficiency problem.
Multiple Contexts Predicting One Word
Having discussed the case of one context predicting one word, let’s now talk about how to extend to multiple contexts predicting one word, as intuitively, predicting a target word based on multiple contexts is more reliable than using a single context.
For any word v, let the set of context words be C, where the context is defined as all words within a certain distance from the center word v. The model’s probability prediction based on context for v is denoted as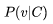 To calculate this probability, we can make a transformation for each word
To calculate this probability, we can make a transformation for each word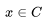 First, we calculate its hidden layer vector
First, we calculate its hidden layer vector 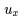 , then average the hidden layer vectors of all context words,
, then average the hidden layer vectors of all context words,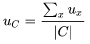 The prediction probability for any word v is as follows:
The prediction probability for any word v is as follows:
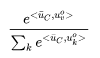
Thus, if we have a series of training samples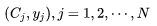 , based on the CBOW model, we can derive the following likelihood function:
, based on the CBOW model, we can derive the following likelihood function:
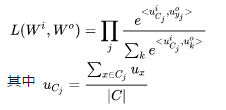
Skip Gram Model
The Skip Gram model is the exact opposite of the CBOW model, as it predicts the context based on the center word. In the paper proposing Word2Vec by Google, this method is recommended for learning word vectors. Similarly, we first understand the case of predicting one context from one center word, then extend to predicting multiple contexts from one word.
One Word Predicting One Context
This is the simplest case, and mathematically it is identical to the CBOW model, with the only difference being that the training samples have changed from (context word, center word) to (center word, context word). We will continue using the previous symbols and also have a simple three-layer neural network. Assuming we have training samples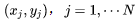 Based on the above analysis, we can construct the likelihood function:
Based on the above analysis, we can construct the likelihood function:
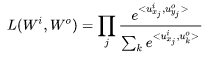
Taking the logarithm gives us:
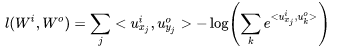
One Word Predicting Multiple Contexts
 To convert to the case of one word predicting one context, we can make the independence assumption, leading to the following formula:
To convert to the case of one word predicting one context, we can make the independence assumption, leading to the following formula:
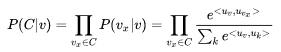
The first equality above is the independence assumption for predicting the context. Similarly, based on a series of samples, 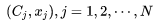 we can write its likelihood function:
we can write its likelihood function:
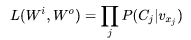
Some Thoughts
Earlier, we mentioned that the encodings learned from the two methods exhibit some excellent features. One of these features is that words with similar parts of speech and semantics have their word vectors located close together in the vector space. This is easily understood through the Skip Gram model. For example, consider two words, 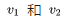 whose contexts are both C. The model’s first step is to find their hidden layer encodings
whose contexts are both C. The model’s first step is to find their hidden layer encodings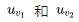 and the subsequent calculations
and the subsequent calculations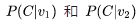 are entirely identical. Theoretically, under optimal conditions,
are entirely identical. Theoretically, under optimal conditions, 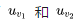 they would ultimately be the same. If their contexts are not exactly the same, but share a large number of similar words, then in the most optimal case,
they would ultimately be the same. If their contexts are not exactly the same, but share a large number of similar words, then in the most optimal case, 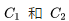 the values would be quite close, leading to
the values would be quite close, leading to 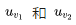 and
and 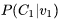 being similar in most cases.
being similar in most cases.
Additionally, the paper recommends using the Skip Gram model. My personal understanding is that the Skip Gram model is more direct and easier to implement, as the architecture remains nearly unchanged, only requiring the target function to be expressed as a product (independence assumption). In contrast, the CBOW model requires averaging all encodings of contexts when predicting a center word, which is not as straightforward as the Skip Gram model. It’s also possible that the Skip Gram model performs better on some datasets, providing stronger interpretability.
Word vector encoding has become a popular method in recent years, and now any NLP problem typically involves encoding text into word vectors before subsequent modeling and calculations, often yielding far better results than direct one-hot encoding. Influenced by the idea of word vector encoding, network encoding has also derived a series of thoughts and methods for knowledge graph representation and inference.
Regardless, I hope this can help those who are starting out in NLP and learning Word2Vec.
References
Distributed Representations of Words and Phrases and their Compositionality
Word2Vec Parameter Learning Explained
Word2Vec Tutorial – The Skip-Gram Model · Chris McCormick
IELTS Vocabulary
undermine vt. to weaken gradually; to dig a foundation
estrange vt. to alienate; to separate
feasible adj. feasible; possible; practical
democratic adj. democratic; pertaining to democracy; popular
qualitative adj. qualitative; relating to quality
Recommended High-Quality Public Accounts
This account is called C Developer, mainly dedicated to sharing technology in the C/C++ and Linux fields. However, this account does not only share technology; every week it also shares some small tools and cognitive experiences summarized from the author’s daily practice. Furthermore, the layout of this account is particularly beautiful, and it has been recommended by well-known internet figures like stormzhang. Highly recommended to follow!

Recommended Reading:
Exciting Knowledge Review
Some Personal Insights on Getting Started with Natural Language Processing
Popular Introduction to the Central Limit Theorem
Detailed Explanation of Activation Functions in Deep Learning
TreeLSTM Sentiment Classification
Detailed Practice of Attention-Based Seq2Seq Machine Translation
[Essentials] Seq2Seq Network Based on Attention Mechanism
Welcome to follow the Deep Learning Natural Language Processing public account, where I will update daily my experiences in Machine Learning, Deep Learning, NLP, Linux, Python and various mathematics knowledge learning! Even the smallest person can have their own brand! Looking forward to progressing together with you!

 Long press to identify the QR code
Long press to identify the QR code
