Analyst Network of Machine Heart
Author: Wang Zijia
Editor: Joni
In this article, the author first introduces the basic knowledge of word2vec to the readers, and then uses six papers as examples to detail how current research utilizes classic word2vec for expansion research. The key focus of the author is the generation process of the knowledge embedding space. Readers interested in its complete application can refer to the original papers.
With the rise of deep learning, every model requires an input, and objects in our real life (text, images, etc.) are not numerical, making them difficult for computers to process. Therefore, determining a suitable “input” for each task becomes particularly important, a process also known as representation learning.
Word2Vec transforms text into inputs that make sense to computers. In simple terms, it maps these elements into a space. Typically, we represent positions in three-dimensional space, i.e., xyz. However, in fields like images and text, three dimensions are often insufficient, leading to the use of another N-dimensional space. In this space, similar objects should also be close together, just as in three-dimensional space, where a person’s nose is close to their mouth. For example, in text, we expect “nose” and “mouth” to be closer together as they both belong to facial features, while “nose” and “leg” should be farther apart.
As the name implies, word2vec converts text into inputs recognizable by computers. Hence, the technology’s initial and most frequent application is in the field of Natural Language Processing (NLP). Previously, I provided two high-level summaries based on ICLR and CVPR regarding representation learning. However, this article focuses specifically on word2vec, delving into details to explore how the discovered space in word2vec is improved and utilized, while also examining the new spaces discovered based on the principles of word2vec. Before diving into the main topic, I will briefly introduce the relevant basic concepts used in this article to prevent any misunderstanding of word2vec.
1. Introduction to Word2Vec
What is Word2Vec:Word2Vec is a process (technology) that uses text as training data for a neural network, where the output vector of this neural network is called an embedding. These embeddings (vectors) will contain semantic information about words after training. The process involves embedding each word from a multi-dimensional space into a much lower-dimensional continuous vector space. Vector embeddings can bridge the gap between the “discrete” world of real objects and the “differentiable” world of machine learning, thus holding enormous potential in database research. The embedding vector of a class of objects is mapped from X to a vector space, referred to as the latent space, which we typically assume to be a finite-dimensional real vector space R^d.
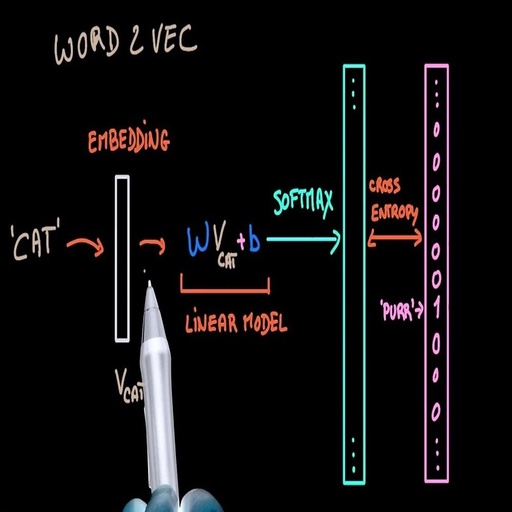
Where are they used:Ultimately, word2vec will produce a set of vectors (word embeddings) as shown in Figure 1, which can serve as inputs for neural network models in subsequent tasks.
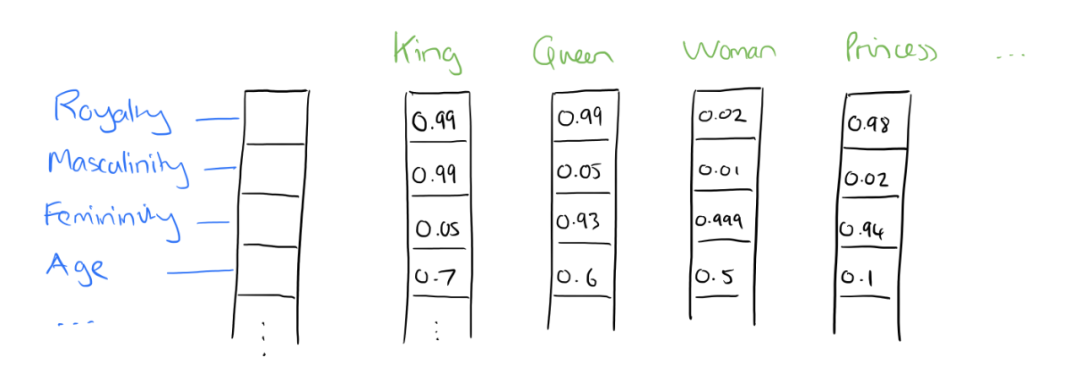
Figure 1: Example of word embedding. Source: https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
Why use Word2Vec:As mentioned earlier, these embeddings capture the semantics of text, where words with similar meanings will be closer together (Figure 2 illustrates one of the most common similarity measures—cosine similarity). Moreover, through extensive practice, researchers have found that this semantic encoding performs well across various NLP tasks.
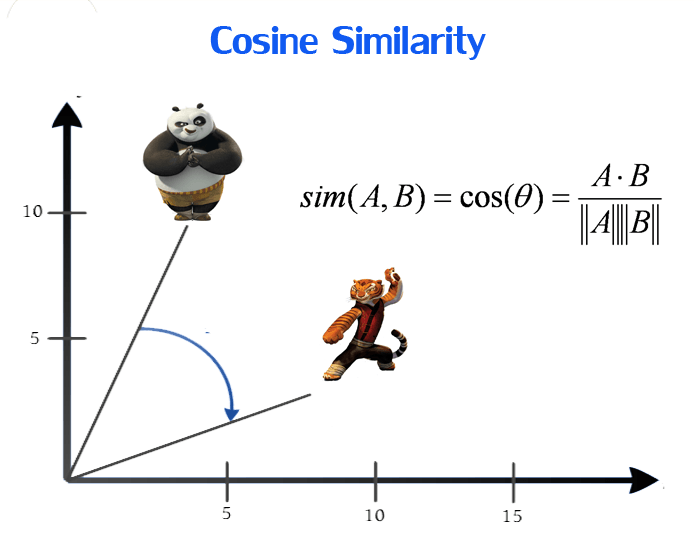
Figure 2: Example of distance measurement—cosine similarity. Source: https://towardsdatascience.com/introduction-to-word-embedding-and-word2vec-652d0c2060fa
Basic Models:The common methods for training word2vec are CBOW and skip-gram. As shown in Figure 3, w(t) denotes the current word, w(t-?) denotes the preceding words, and w(t+?) denotes the following words. In simple terms, CBOW uses surrounding words to predict the current word, while the skip-gram model utilizes the current word to attempt to predict the words within a window of size c. For specific computational details, refer to the source article of Figure 3; I will not elaborate further here.

Figure 3: Skip-gram and CBOW. Source: https://towardsdatascience.com/nlp-101-word2vec-skip-gram-and-cbow-93512ee24314
How to Measure:When using embeddings, we should consider several questions—what attributes of the objects are represented by the embeddings? What is the significance of the distance measurement we use? Do the geometric properties of the latent space correspond to meaningful relationships on X? Of course, we also need to consider the computational cost of calculating the vector embeddings.
2. Improving the Old Space
Having understood the basic knowledge of word2vec, we can officially enter the main topic. As mentioned in the previous section, when establishing an embedding space, we need to consider which attributes of the objects need to be represented in the embedding space. Word2vec performs well in traditional NLP tasks, but in some new, more complex tasks, certain attributes cannot be well represented because the original word2vec model is entirely text-based for training, and many relationships are difficult to reflect in text. For example, the words “look” and “eat” are hard to associate when viewed in isolation.
However, if we add Figure 4, do they become connected? This image can be described in two ways: one is that a little girl is “looking” at ice cream; the other adds a certain association— the little girl is “eating” ice cream. In this description, both statements are correct. This example not only illustrates the limitations of learning from pure text but also highlights the importance of such information in tasks like image description.
Figure 4: The little girl eating ice cream. Source: [1]
It’s not hard to understand that humans utilize not only vision but also other sensory modalities such as hearing and smell to perceive the world. Similarly, when looking, we do not only rely on written text; language serves as a carrier of knowledge. Therefore, researchers are beginning to use different sensory modalities (sound, images) to learn language models (multi-modal learning), enabling the embeddings learned by language models to more comprehensively represent our understanding as humans.
From a technical perspective, tracing back to the origins of language models, they are akin to siblings of transfer learning, albeit in different domains, resulting in different names. For instance, in NLP tasks, a language model is trained first, and then the pre-trained model is directly used for subsequent tasks, resembling frozen layers in transfer learning (if this concept is unclear, it won’t significantly affect the understanding of what follows. Those who find it challenging can refer to previous articles from Machine Heart that offer many foundational tutorials, and I won’t elaborate further here).
The reason it is called transfer learning is that to achieve the goal of enhancing the word2vec space, it is similar to a global finetune in transfer learning, incorporating the previously “frozen” layers of the language model into the training.
To demonstrate how current research utilizes word2vec for expanded applications, this section briefly introduces four papers, showcasing how images and sounds enhance the representational capabilities of existing word2vec embedding spaces. Of course, the knowledge embedding space generation process described here contains other innovations in the original papers; interested readers can refer to the complete papers for more details.
2.1 Visual Word2Vec (vis-w2v) [1]

Paper link: https://arxiv.org/pdf/1511.07067.pdf
This method addresses the issues raised in the example of Figure 4. Here, the authors aim to incorporate the semantic representation of images into the existing word embeddings, meaning that images are added as background to the w2v training.This method is based on CBOW and employs surrogate labels as representations of image backgrounds.
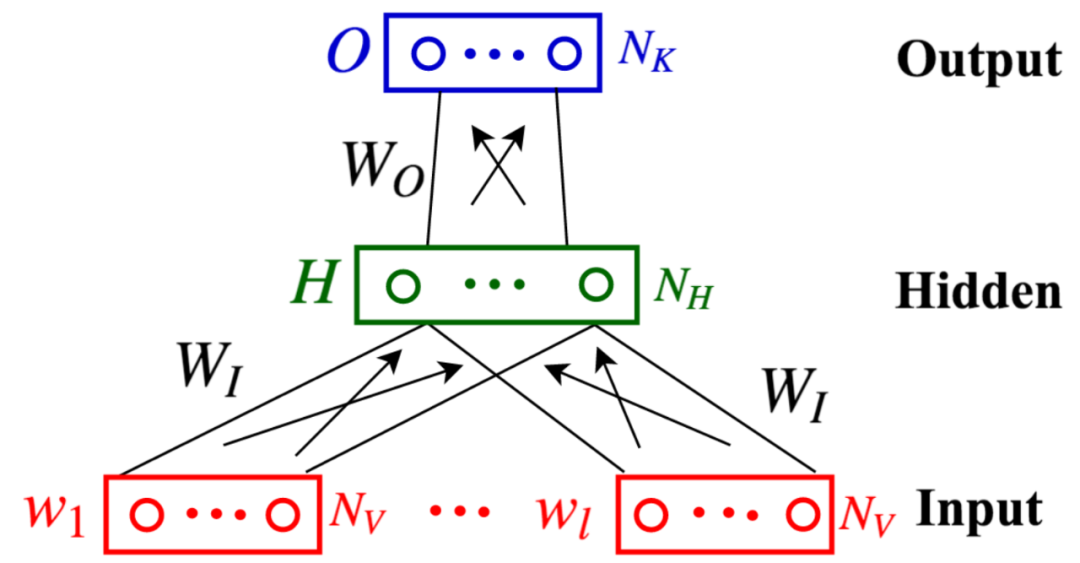
Figure 5: Network structure in vis-w2v. Source: [1]
The specific model is illustrated in Figure 5. The model’s input consists of image-text pairs D = {(v, w)}, where v refers to the features of the image, and w is the corresponding text description of v. The form of w (sentence or word) can vary based on the context.
Figure 5 displays a window that may contain some words from w or the entire w, depending on the context. Here, w_1 to w_l represent the words included in a window, encoded using one-hot encoding (N_V denotes the dimension of one-hot encoding). H_wi is obtained by multiplying wi with W_I, where W_I is shared, meaning all w_i are multiplied by the same W_I. Since one-hot encoding is used, it essentially takes a specific row of W_I. Ultimately, H is obtained by averaging the various H_wi:
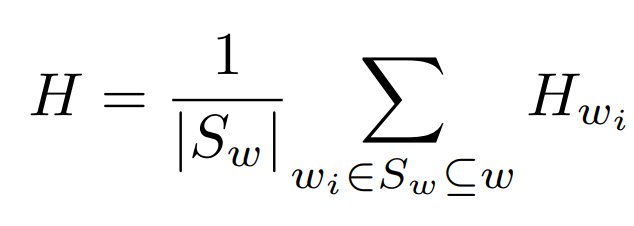
After obtaining H (N_H is the embedding dimension), this H serves as the final feature vector, which is mapped to N_K dimensions using W_O. After performing a softmax operation, we can determine which category the text (w_1-w_l) belongs to; this step involves classification.
If you are familiar with NLP tasks, the first step of obtaining H is similar to how we usually obtain embeddings, as W_I is initialized to the traditional CBOW weights. Hence, this step essentially retrieves the traditional embeddings for these words and averages them to obtain the features for all words in the window, followed by a classification task.
Now we reach the core of this article—previously mentioned as a classification task. So, where do the labels for this classification task come from? This is where surrogate labels come into play—the authors cluster the images v into N_K categories, and each v’s corresponding class becomes the label for w during the classification task.
Returning to w, here w allows for selecting various forms of w, such as complete sentences or tuples (main object, relation, secondary object). The choice of w depends on the task we are concerned with. For example, in common sense assertion classification and text-based image retrieval, w is a phrase from the tuple, while in visual interpretation, w is a sentence. Given w, S_w is also adjustable. It can include all w (for example, when learning from a phrase in a tuple) or a subset of words (for example, when learning from an n-gram context window from a sentence).
Lastly, regarding the effectiveness, this task essentially fine-tunes the existing w2v. According to the paper, this direct global finetuning can maintain the original w2v effectiveness; if certain words do not appear during finetuning, they will retain their original semantic characteristics. This global finetuning does not degrade the performance of the new w2v in traditional tasks.
As shown in Table 1, the performance of vis-w2v in visual narration tasks significantly exceeds that of the pure w2v task.

Table 1: Average accuracy (AP) in visual narration tasks. Source: [1]
2.2 Visually Supervised Word2Vec (VS-Word2Vec) [2]

Paper link: https://ieeexplore.ieee.org/abstract/document/8675640?casa_token=lw7U2LlGUk4AAAAA:uhM9BVykvRQyYoWE5KCq3BfjUSjLRED2yV7nktCUgw3jDcAh_R2xx8iV7Az3pBWTZPBQ87cQzEgd
This paper also aims to convey information from images to w2v, enabling the w2v space to better represent the information in images. The previous paper added general image information to w2v (guiding word similarity through image similarity), while this paper’s full title is Embedded Representation of Relation Words with Visual Supervision, which, as the name suggests, aims to allow the embedding space to better represent relational words (e.g., “holding” in “I am holding a bag”).
Figure 6 shows examples of relational words, while [3] provides a dataset similar to this as one of the input forms for this paper.

Figure 6: Relational words. Source: [3]
The basic structure of VS-Word2Vec is shown in Figure 7. This architecture is divided into upper and lower parts. The upper part is a CNN, where images like those in Figure 6 serve as inputs, and the output is a feature vector, which serves as the embedding for the relational words corresponding to the image (Visual relation feature space); the lower part is the traditional CBOW, which also produces word embeddings.
Besides the difference in the information represented compared to the first paper, the methods used are also different; its fundamental idea is: if the word is a relational word, then the embedding produced by the upper part (CNN) should be as similar as possible to the embedding produced by the lower part; however, if the word is not a relational word, the upper part is disregarded, and the training proceeds exactly as traditional CBOW.
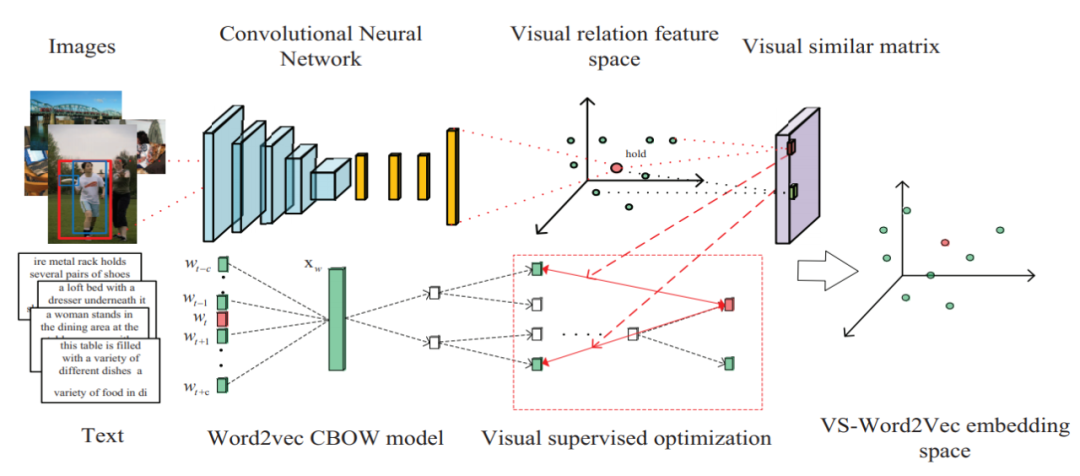
Figure 7: VS-Word2Vec network structure. Source: [2]
Specifically, the overall algorithm is illustrated in Figure 8. The first two lines correspond to the upper part of Figure 7, the CNN, which first calculates the visual representation (Visual relation feature, algorithm line 4):
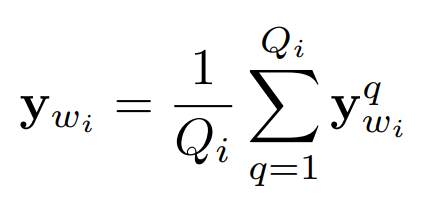
Here, y_wi is the representation of a relational word wi, specifically obtained by using VGG to retrieve all images corresponding to this relational word (Q_i images) and averaging their feature vectors (y_wi^q). As previously mentioned, if the trained word is a relational word, the authors aim to ensure that the embeddings generated by CBOW and the embeddings generated by CNN are as similar as possible; the inconsistency in this paper is measured using the following formula:
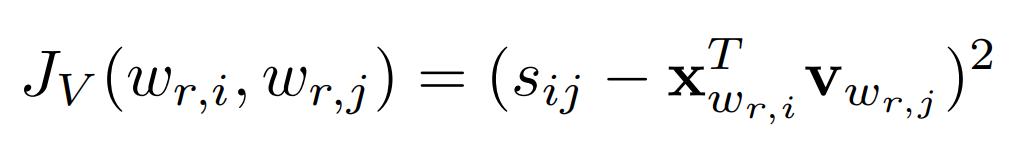
In this formula, s_ij denotes the cosine similarity between relational words i and j, with the subscript r indicating that this is a relational word, while x represents the word embedding produced by CBOW, and v represents the word embedding generated by CNN. The smaller J is, the better.
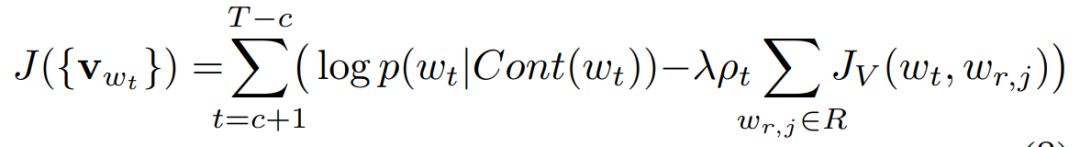
Figure 8: VS-Word2Vec algorithm process. Source: [2]
The final steps in lines 4 to 19 of Figure 8 reflect the overall idea mentioned above, which involves calculating the following formula while simultaneously updating parameters (gradient ascent):
Here, D is the training set for CBOW. For each word in this training set, two losses e1 and e2 are calculated. e1 corresponds to the first half, which is the traditional CBOW loss, while e2 is the second half, measuring the inconsistency between the two types of embeddings (J_V). The lambda is a tunable hyperparameter, and p_t indicates whether w_t is a relational word; if it is, p_t=1, retaining the second half; if not, the process reverts to the traditional CBOW training.
Note that line 15 employs a for loop. Thus, the goal of this paper is not to make the embeddings for a relational word produced by the upper and lower parts exactly the same, but to ensure that the embeddings for relational words maintain the “consistency” illustrated in Figure 7, hence using J_V instead of directly applying cosine similarity.
Using this method, the authors compared the performance of their model with nine categories of synonyms (SYNONYMS, ANTONYMS, HYPER/HYPONYMS, COHYPONYM, NONE) in SimVerb-3500, as shown in Table 2. Overall, it performs better than CBOW, with significant improvements in some particularly special categories.
Table 2: Synonym consistency results. Source: [2]

Paper link: https://arxiv.org/pdf/1901.00484.pdf
This is another paper exploring visual information, but here the focus shifts to videos (as it encodes actions). As shown in Figure 9, the concept is similar to the previous papers, but this time it involves a genuine comparison of two words (pairwise ranking loss) rather than assessing consistency.
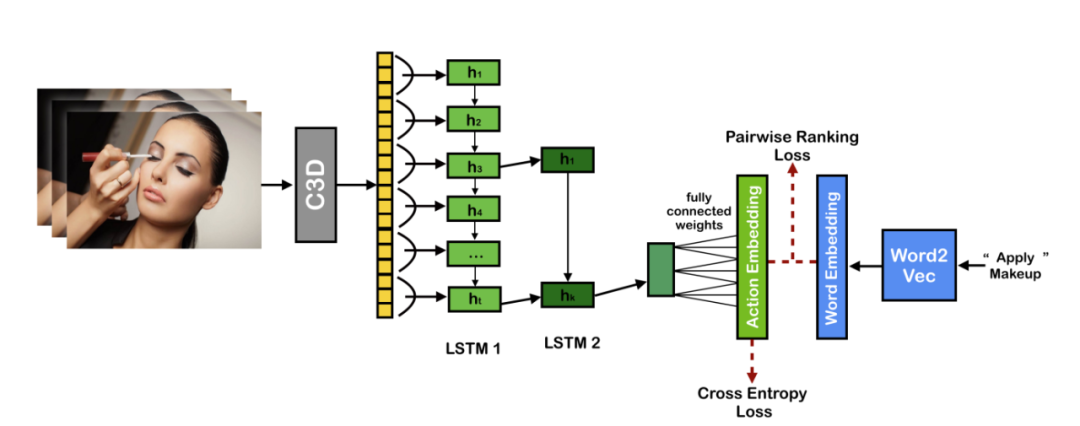
Figure 9: Action2Vec end-to-end architecture. Source: [4]
Specifically, on the left, the C3D model pre-trained on the dataset from [5] is used to extract feature vectors from each frame of the image, then a Hierarchical Recurrent Neural Network (HRNN) is employed with a self-attention mechanism. Finally, a fully connected layer transforms the video embeddings obtained from LSTM2 into vectors of the same dimension as word embeddings, followed by a classification task to determine the action corresponding to the video. A “dual loss” (cross-entropy + pairwise ranking) is used to ensure that the improved joint embedding space retains both video and text semantic information.
HRNN:The HRNN refers to using two layers of LSTM, where the first layer extracts local features (input is each frame of the image), and the second layer (LSTM2) takes the output of LSTM1 every s frames as its input. In the example of Figure 9, the step size is 3, meaning that every three frames (h1-h3, h4-h6, …) will output a vector, which serves as the output of LSTM2. The attention calculations in the self-attention mechanism will not be elaborated on here.
Dual Loss:This dual loss refers to cross-entropy plus pairwise ranking loss. The cross-entropy will not be elaborated on here as it corresponds to the classification task. If you are unfamiliar with pairwise ranking loss (PR loss), you can refer to this article (https://gombru.github.io/2019/04/03/ranking_loss/) for a clearer understanding of the following formula. The PR loss is defined as follows:
In this formula, a_i and v_i represent the action word embeddings produced by the HRNN and word2vec models, respectively, while a_x and v_x correspond to the negative samples (embeddings of non-action word i). It’s important to note that Figure 9 does not fully illustrate the cross-entropy (CE) corresponding to the classification task, which occurs after the action embedding passes through a fully connected layer.
Finally, it’s worth mentioning that due to the potential mismatch between the words in the two databases, some verbs in the video database may not exist in the word2vec vocabulary. In such cases, these action verbs are transformed into their corresponding forms (e.g., “walking” becomes “walk”).
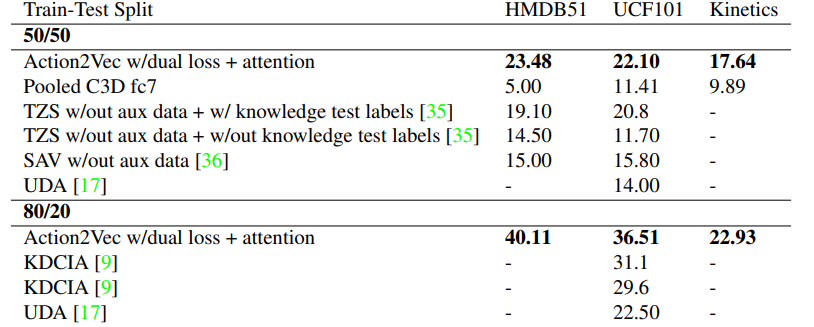
In the experimental section, the authors compared their model’s performance in the ZSAL (Zero Shot Action Learning) task with other ZSL models, demonstrating that their proposed model consistently outperformed others across various datasets.
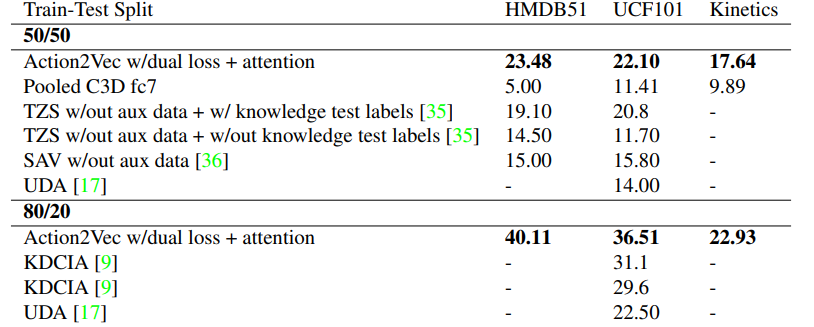
Table 3: Comparison of ZSAL (Zero Shot Action Learning) model performance. Source: [4]

Paper link: https://arxiv.org/pdf/1703.01720.pdf
The previous papers focused on visual information, while this final paper delves into auditory information, specifically sound signals. Although most sounds have onomatopoeic words, many of these words are not commonly found in text, and compared to direct sounds, the semantic information corresponding to these words is challenging to learn. Therefore, the authors of this paper integrate the acoustic features of these sounds into the traditional word embedding space. Notably, surrogate labels (clustering) are also utilized here. The overall structure of this model is shown in Figure 10.
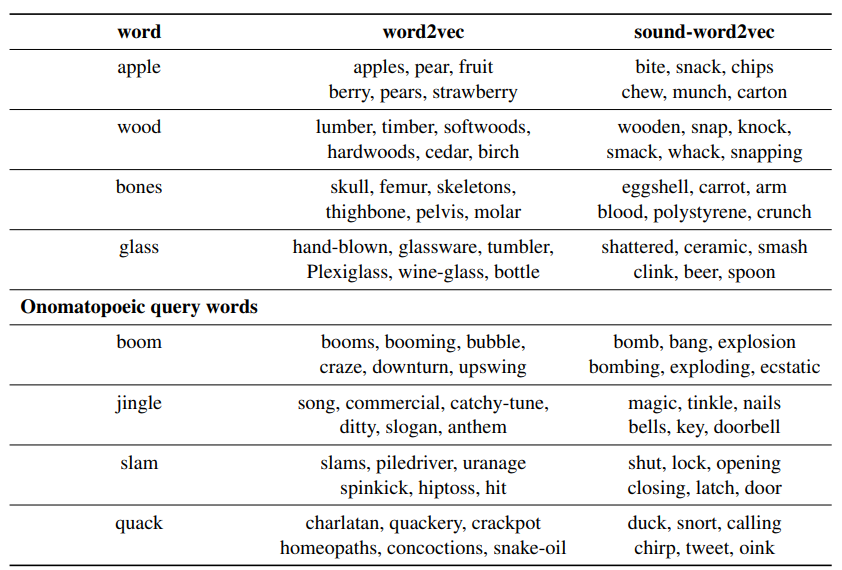
Figure 10: sound-word2vec. Source: [7]
In Figure 10, the input of this model is based on FreeSound, generating input pairs {s, T}, where s is the sound, and T is a series of tags provided by users corresponding to this sound (a set of words). These tags are first transformed into embeddings through W_P (initialized using weights from a pre-trained word2vec model), and then the average of these embeddings yields the hidden layer value H. Finally, H undergoes a classification task through a fully connected layer (W_O) to output a category.
Similar to the first paper, the classification task’s labels are again derived from clustering. The sound s is clustered to obtain category labels, which are then used to train W_P and W_O. Overall, the idea in this paper is quite similar to that in the first paper, but the sound processing regarding how to represent sounds is quite enlightening. Moreover, this paper once again demonstrates that global finetuning can yield positive results in enhancing traditional word embedding spaces.
The effectiveness of this method is shown in Table 4. For common words, the performance is comparable to word2vec, but for onomatopoeic words, sound-word2vec performs significantly better. The authors also conducted experiments in some text-based onomatopoeic word recognition tasks, achieving much better results than standard baseline models (specific details can be found in the original paper).
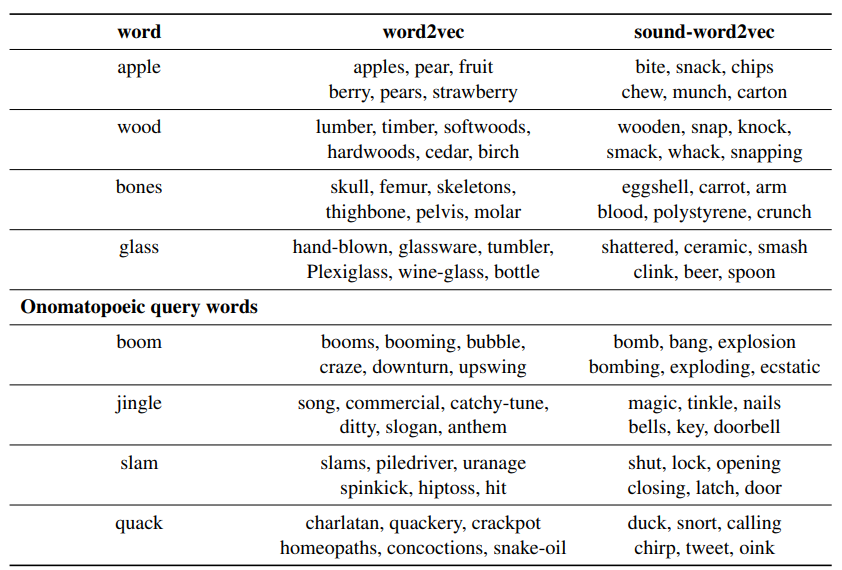
Table 4: Example of similar words. Source: [7]

Paper link: https://link.springer.com/article/10.1007/s00521-018-3923-1
Last year, Google utilized language models to convert protein sequences into embeddings, achieving significant breakthroughs in many related tasks. I once wrote a dedicated article on this, so I won’t elaborate here. Today, I mainly introduce how this method is applied to music, producing a new music-based embedding space, representing music theory knowledge—Music + word2vec [6].
Because this paper contains specialized music theory knowledge, the corresponding machine learning methods are relatively traditional, involving a skip-gram model combined with encoding of musical scores. However, the paper provides a detailed analysis of how various musical theory knowledge is represented in the musical score embedding space, indicating that skip-gram can effectively learn musical theory knowledge from scores.
Regarding the encoding of musical scores, Figure 11 shows the first six measures of Chopin’s Mazurka Op. 67 No. 4, along with examples of encoding for the first three measures. Here, it treats a beat as a character in text, where the first segment contains E, which represents the pitch class E5 in a quarter note. Since the second beat’s pitch includes both E5 and A3, the second segment contains E and A. Note that the author includes E in the second measure, even though the pitch E5 is connected to the first beat (not starting a new one), it still sounds in the second beat. Similarly, the third beat includes pitches E3, A3, E4, and E5 (from a tied note) and F5, thus the third segment contains the pitch classes E, A, and f. The example in Figure 2 can also be used to explain why beats are chosen as segments of duration.

Figure 11: Musical score classification. Source: [6]
If a sound lasts longer than one beat, we may lose subtle differences in pitch and chord changes. Conversely, if the segments are shorter than a beat, it could lead to excessive repetition (where the content between segments is the same). Finding the optimal duration for segments is also crucial, though this paper does not address it. I believe a better encoding method would enhance the effectiveness of this research.
Because the value of this paper does not lie in the machine learning methods employed, but rather in the use of skip-gram, I will not discuss the training process further. Of course, this paper not only proves that skip-gram can effectively acquire chord and harmonic features in the music domain but also provides many datasets that can be utilized in the music field (section 4). These datasets are quite useful for anyone interested in conducting research in this area.
The results of this paper’s analysis are overly specialized. If you want to see how music masters evaluate this model, you can refer to the original paper. In summary, this model performs excellently across various aspects. Those familiar with music can check how the original paper analyzes it, which may greatly assist in subsequent tasks.

Paper link: https://arxiv.org/pdf/1908.01211.pdf
Finally, after discussing how to enhance traditional word embedding spaces and how to create new embedding spaces, it’s also important to consider how to utilize these spaces. However, since this article does not serve as an introduction to word2vec, I will not elaborate on its applications in traditional NLP tasks, as there are already many practical and theoretical popular science articles available online. Here, I will mainly introduce how word embeddings are applied in reinforcement learning—Word2vec to behavior [8].
Here, a represents the acoustic neural cells. Initially, commands are input, and the embedding of this command initializes the hidden layers h_i. This initialization uses the embeddings of five command words to pre-train and initialize h_1-h_5, where the command words are ‘forward’, ‘backward’, ‘stop’, ‘cease’, ‘suspend’, and ‘halt’, with the latter four expressing similar meanings, so one is not used for initialization and serves as a test group. Once initialized, these dashed connections are removed, and the robot enters the simulator to begin simulation. The command embeddings are input into the robot, which then performs actions based on the information obtained from various sensors (s).
Aside from the aforementioned mechanism, the overall network in Figure 12 is not complex. The first layer is called the sensor layer, which gathers data from the robot’s sensors. These neurons are fully connected to the subsequent hidden layers, where the second hidden layer is a recurrent neural network with self-connections. Finally, this hidden layer is also fully connected to the action layer (on the far right).
Figure 12: Word2vec to behavior training network. Source: [8]
In summary, the entire training process is illustrated in Figure 13. By providing the neurons a in the input layer with word2vec embeddings related to commands such as “stop”, we can set the initial values for the hidden layers controlling the robot’s strategy. This strategy is then downloaded to the robot, and the sensor data generated from its movements is fed back into the input layer’s remaining neurons (dashed arrows), further altering the hidden and motor layers.
After evaluation, the robot’s behavior is scored based on the objective function paired with the commands (e.g., a penalty function for movement). Subsequently, the same strategy is evaluated four or more times for the other four commands and target functions (B and C correspond to two evaluations each), training the strategy to maximize the average score across all five functions (D). After training, the optimal strategy will provide a sixth synonym “cease” not present during training, and its behavior will be scored based on the “stop” objective function (E).
Figure 13: Training process. Source: [8]
From the analytical or innovative papers mentioned in this article, it is evident that skip-gram and CBOW can effectively capture the semantics of many objects in our lives (music, sound, etc.), while multi-modal learning is a great method to enhance existing embedding spaces. In the absence of labels, reasonable clustering can also provide auxiliary labels for the model. This embedding space is not only applicable to the NLP field but can also be directly applied to many other areas using embeddings generated from w2v (such as RL).
Of course, there are still many other directions to explore in the future, such as developing the relatively nascent music field and how to incorporate emotions from sounds into traditional w2v models.
In summary, language is a fundamental element in our observation and description of the world, covering nearly every aspect of our lives. On certain levels, it reflects the laws of the objective world (for instance, the linguistic principle of compositionality). When faced with unsolvable learning problems, language models may offer some insights.
[1] Kottur, Satwik, et al. “Visual word2vec (vis-w2v): Learning visually grounded word embeddings using abstract scenes.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
[2] Wang, Xue, et al. “Embedded Representation of Relation Words with Visual Supervision.” 2019 Third IEEE International Conference on Robotic Computing (IRC). IEEE, 2019.
[3] Lu, Cewu, et al. “Visual relationship detection with language priors.” European conference on computer vision. Springer, Cham, 2016.
[4] Hahn, Meera, Andrew Silva, and James M. Rehg. “Action2vec: A crossmodal embedding approach to action learning.” arXiv preprint arXiv:1901.00484 (2019).
[5] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014. 4
[6] Chuan, C.-H., Agres, K., & Herremans, D. (2018). From context to concept: exploring semantic relationships in music with word2vec. Neural Computing and Applications. doi:10.1007/s00521-018-3923-1
[7] Vijayakumar, Ashwin K., Ramakrishna Vedantam, and Devi Parikh. “Sound-word2vec: Learning word representations grounded in sounds.” arXiv preprint arXiv:1703.01720 (2017).
[8] Matthews, David, et al. “Word2vec to behavior: morphology facilitates the grounding of language in machines.” arXiv preprint arXiv:1908.01211 (2019).
The author of this article is Wang Zijia, currently pursuing a Master’s in Artificial Intelligence at Imperial College. His main research direction is recommendations in NLP, and he loves cutting-edge technology and quirky ideas, aspiring to be a researcher who takes unconventional paths!
About Machine Heart’s Global Analyst Network Synced Global Analyst Network
The Synced Global Analyst Network is a global knowledge-sharing network initiated by Machine Heart, focusing on artificial intelligence. Over the past four years, hundreds of students, scholars, engineering experts, and business professionals in the AI field from around the world have shared their research ideas, engineering experiences, and industry insights with the global AI community through online sharing, column interpretations, knowledge base construction, report releases, evaluations, and project consulting, while gaining personal growth, experience accumulation, and career development.
Interested in joining the Synced Global Analyst Network? Click Read the original text to submit an application.