Click the “MLNLP” above and select “Star” for the public account
Heavy content delivered first-hand
Author | Yi Zhen
Address | https://zhuanlan.zhihu.com/p/30844905
Column | Machine Learning Algorithms and Natural Language Processing
Understanding RNN (Recurrent Neural Networks) Basics
Basics of Neural Networks
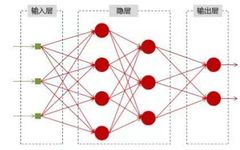
Neural networks can be considered as black boxes that can fit any function. As long as the training data is sufficient, given a specific x, one can obtain the desired y. The structure diagram is as follows:
Once the neural network model is well-trained, by providing an x at the input layer, one can obtain a specific y at the output layer. Given such a powerful model, why do we still need RNN (Recurrent Neural Networks)?
Why RNN (Recurrent Neural Networks) is Needed
They can only process individual inputs independently, with no relation between the previous and subsequent inputs. However, some tasks require better handling of sequential information, where the previous inputs are related to the following inputs.
For example, when we understand the meaning of a sentence, it is not enough to independently understand each word; we need to process the entire sequence that connects these words; When processing a video, we cannot analyze each frame in isolation but must analyze the entire sequence that connects these frames.
Taking a simple part-of-speech tagging task in NLP, we label the words in “I eat apple” as I/nn eat/v apple/nn.
So the input for this task is:
I eat apple (a pre-tokenized sentence)
The output for this task is:
I/nn eat/v apple/nn (tagged sentence)
For this task, we can certainly use a standard neural network directly, formatting the training data as I -> I/nn, which consists of multiple individual words -> tagged words.
However, it is clear that in a sentence, the previous word significantly influences the part-of-speech prediction of the current word. For example, when predicting apple, since the previous word eat is a verb, the probability of apple being a noun is significantly higher than that of it being a verb, as it is common for a verb to be followed by a noun, while it is rare for a verb to be followed by another verb.
Thus, to solve similar problems and better handle sequential information, RNN was born.
RNN Structure
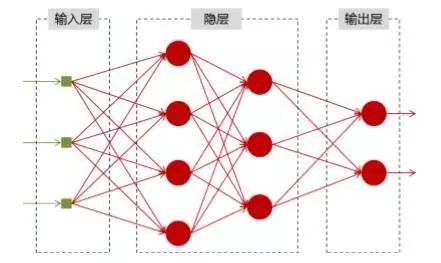
First, let’s look at a simple recurrent neural network, which consists of an input layer, one hidden layer, and one output layer:

I wonder if beginners can understand this diagram; when I first learned, I was confused. Does each node represent an input value, or is it a collection of vector nodes for a layer? How does the hidden layer connect to itself? These doubts are quite abstract.
Now let’s understand it this way: if we remove the arrowed circle with W at the top, it becomes a standard fully connected neural network. x is a vector representing the values of the input layer (the neuron nodes are not shown here); s is a vector representing the values of the hidden layer (there is a node drawn for the hidden layer, but you can imagine this layer actually consists of multiple nodes, with the number of nodes equal to the dimension of vector s);
U is the weight matrix from the input layer to the hidden layer, o is also a vector representing the values of the output layer; V is the weight matrix from the hidden layer to the output layer.
Now, let’s see what W is. The value s of the hidden layer in the recurrent neural network depends not only on the current input x but also on the previous value s of the hidden layer. The weight matrix W serves as the weight of the previous value of the hidden layer as input for the current time step.
We can provide a concrete representation of this abstract diagram:

From the above diagram, we can clearly see how the hidden layer from the previous moment affects the current moment’s hidden layer.
If we expand the above diagram, the recurrent neural network can also be depicted as follows:
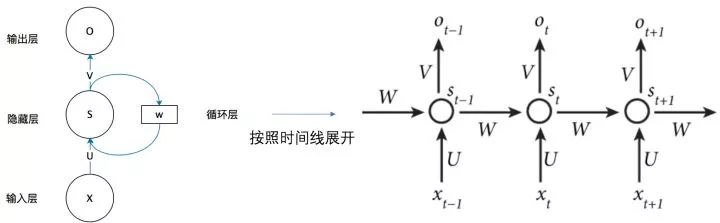
Now it looks clearer. This network receives input at time t  . The value of the hidden layer is
. The value of the hidden layer is  and the output value is
and the output value is  . A key point is that
. A key point is that  depends not only on
depends not only on  but also on
but also on  . We can represent the calculation of the recurrent neural network using the following formula:
. We can represent the calculation of the recurrent neural network using the following formula:
Expressed in the formula as follows:

Conclusion
Alright, this has roughly explained the most basic knowledge points of RNN, which can help everyone intuitively feel RNN and understand why RNN is needed. We will summarize its backpropagation knowledge points later.
Finally, here is a summary diagram of RNN:

Note: To simplify the explanation, biases are not included in the formulas.
Thanks to: Xia Chong and the lab partners Reference: Zero-based Introduction to Deep Learning (5) – Recurrent Neural Networks (Thanks for this great material)
Recommended Reading:
How do research experts read literature?
How did conference papers become a necessary condition for doctoral admission?
How to view the resignation of Yu Gang, the head of the detection group at Megvii, to Tencent PCG’s Light and Shadow Research Lab?
