
Click on the above “Visual Learning for Beginners” to choose to add a Star or “Pin”
Heavyweight content delivered first-hand
From | Zhihu
Author | Lucas
Link | https://zhuanlan.zhihu.com/p/85995376
Understanding RNN: Recurrent Neural Networks and Their PyTorch Implementation
Recurrent Neural Networks (RNN) are a type of neural network with short-term memory capabilities. Specifically, the network remembers previous information and applies it to the current output calculation, meaning that the input to the hidden layer includes not only the output from the input layer but also the output from the previous hidden layer. In simple terms, RNNs are designed to handle sequential data. If CNNs simulate human vision, then RNNs can be seen as simulating human memory capabilities.
Why Do We Need RNN? What Are the Main Differences from CNN?
-
CNNs are akin to human vision and lack memory capabilities; they cannot process new tasks based on previous memories. In contrast, RNNs are based on the idea of human memory, expecting the network to recognize features that appeared earlier and complete downstream tasks based on those features.
-
CNNs require fixed-length inputs and outputs, while RNNs can have variable-length inputs and outputs.
-
CNNs only have a one-to-one structure, while RNNs have multiple structures.
Structure Composition
A simple RNN consists of three parts: input layer, hidden layer, and output layer (obviously). If we expand the diagram above, the recurrent neural network can be illustrated as follows:
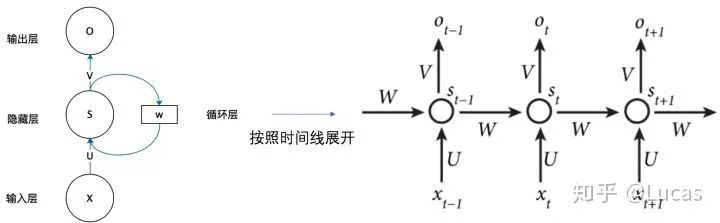
Why can a recurrent neural network look back at any number of input values?
Look, this is the calculation formula for the output layer o and hidden layer s.

If we substitute formula 2 into formula 1 continuously, we get:

Memory Capability
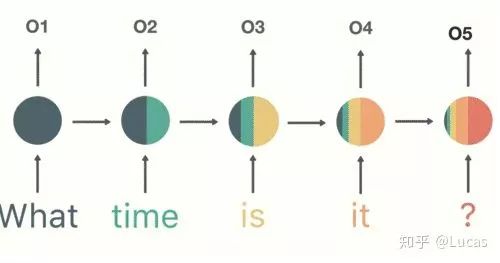
This model has a certain memory capability, capable of sequentially processing information of any length. Previous inputs influence the future. What does this mean? As shown in the figure below. When we input the phrase “What time is it?” into the neural network, each word will influence the next word.
Disadvantages: Gradient Vanishing and Gradient Explosion

From the above example, we have found that short-term memory has a significant impact (as shown in the orange area), but the impact of long-term memory is minimal (as shown in the black and green areas), which is the short-term memory problem of RNNs.
Morvan Python explains this very vividly:
‘Today I want to make braised pork ribs, first I need to prepare the ribs, then…., finally the delicious dish is ready.’ Now, please ask RNN to analyze what dish I am making today. RNN might give the answer “spicy chicken.” Due to the misjudgment, RNN has to start learning the relationship between this long sequence X and “braised pork ribs,” but the key information “braised pork ribs” appears at the beginning of the sentence.
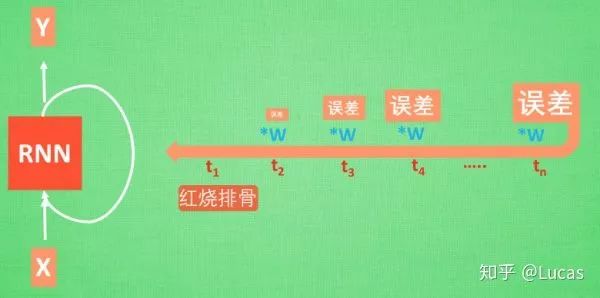
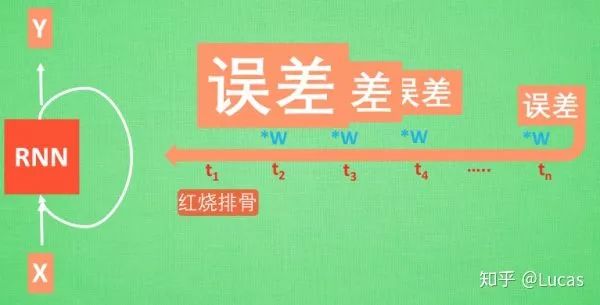
The memory of the information “braised pork ribs” has to travel a long way to reach the last time point. Then we get an error, and during backpropagation, the error at each step is multiplied by a parameter W. If this W is a number less than 1, say 0.9, this 0.9 keeps multiplying the error, and the error reaching the initial time point will be close to zero, so for the initial moment, the error effectively disappears. We call this problem gradient vanishing. Conversely, if W is a number greater than 1, say 1.1, it keeps multiplying, resulting in an infinitely large number, causing RNN to crash due to this infinite number. We call this situation gradient explosion, which is why ordinary RNNs cannot recall distant memories.
Thanks to
@Morvan
for the explanation of the fundamental knowledge of machine learning, allowing juniors to grow rapidly. Knowledge sharing is a noble quality of humanity. I sincerely thank you!
Basic Model Implementation in PyTorch
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
def forward(self, input, hidden):
# Combine input and previous hidden layer parameters.
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined) # Calculate hidden layer parameters
output = self.i2o(combined) # Calculate the output of the network
return output, hidden
def init_hidden(self):
# Initialize hidden layer parameters
return torch.zeros(1, self.hidden_size)References
morvanzhou.github.io/tu
easyai.tech/ai-definiti
Code Link:
github.com/zy1996code/n
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "OpenCV Extension Module Chinese Tutorial" in the backend of the “Visual Learning for Beginners” public account to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of the “Visual Learning for Beginners” public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, helping you quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of the “Visual Learning for Beginners” public account to download 20 practical projects based on OpenCV for advanced learning.
Group Chat
Welcome to join the reader group of the public account to exchange with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will be gradually subdivided in the future). Please scan the WeChat number below to join the group, with remarks: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for remarks; otherwise, you will not be approved. After successful addition, you will be invited to related WeChat groups based on your research direction. Please do not send advertisements in the group, or you will be removed. Thank you for your understanding~