Author丨Mia Luo @ Zhihu (Authorized Reprint)
Source丨https://zhuanlan.zhihu.com/p/486360176Editor丨Xiaoshutong, Jizhi Shutong
1. Background Introduction
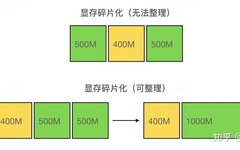
The analysis of the PyTorch memory management mechanism mainly aims to reduce the impact of “memory fragmentation”. A simple example is:

As shown in the figure above, suppose we want to allocate 800MB of memory. Although the total free memory is 1000MB, the free memory shown in the upper figure consists of two non-contiguous 500MB blocks, which is insufficient to allocate the 800MB memory; whereas in the lower figure, if the two 500MB free blocks are contiguous, we can organize the memory fragments into a single larger block of 1000MB, which is enough to allocate 800MB. The situation in the upper figure is referred to as “memory fragmentation”.
“Solution”: When multiple Tensors can be released, it is preferable to release those Tensors that have free memory adjacent to them in the memory space. This facilitates PyTorch in organizing these free blocks into a larger contiguous block.
“Core Issue/Prerequisite”: Can we obtain the block we want to release and the size of the adjacent free space with very low cost (O(1) or O(logn) complexity)? With this, we can sort the Tensors and prioritize releasing the ones with the maximum size of “adjacent free blocks + self size”.
This prerequisite can be transformed into finding the following two functions (pseudo code):
block = get_block(tensor) # Find the Block storing this Tensor
size = get_adjacent_free_size(block) # Return the free space before and after this Block for sortingQuestions that may be answered after studying the PyTorch memory management mechanism:
-
Why does the error message indicate sufficient memory, yet we still encounter OOM? -
What is the multi-level allocation mechanism of memory? Why is it designed this way?
2. Source Code Interpretation
Mainly look at c10/cuda/CUDACachingAllocator.cpp in the DeviceCachingAllocator class (L403)
Link: https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L403
2.1 Main Data Structures
Block:
-
The basic unit for allocating/managing memory blocks, the triplet (stream_id, size, ptr) can specifically locate a Block, meaning the Block maintains a ptr pointing to a memory block of size. -
All contiguous Blocks (whether free or not, as long as they are obtained from Allocator::malloc) are organized in a doubly linked list for quick checks of adjacent fragments when freeing a Block, allowing them to be merged directly.
struct Block {
int device; // gpu
// The Block is bound to the stream of the caller at allocation, and cannot be used by other streams even if released.
cudaStream_t stream; // allocation stream
stream_set stream_uses; // streams on which the block was used
size_t size; // block size in bytes
BlockPool* pool; // owning memory pool
void* ptr; // memory address
bool allocated; // in-use flag
Block* prev; // prev block if split from a larger allocation
Block* next; // next block if split from a larger allocation
int event_count; // number of outstanding CUDA events
};BlockPool:
-
A memory pool that stores pointers to Blocks using std::set, sorted by (cuda_stream_id -> block size -> addr) in ascending order. All Blocks stored in BlockPool are free.
struct BlockPool {
BlockPool(
Comparison comparator,
bool small,
PrivatePool* private_pool = nullptr)
: blocks(comparator), is_small(small), owner_PrivatePool(private_pool) {}
std::set<Block*, Comparison> blocks;
const bool is_small;
PrivatePool* owner_PrivatePool; // For CUDA Graphs, not detailed here
};-
The DeviceCachingAllocatormaintains two types of BlockPool (large_blocks, small_blocks) for storing smaller and larger blocks (to speed up small and large requests respectively), categorizing blocks <= 1MB as small and > 1MB as large. Intuitive understanding of Block and BlockPool is shown in the figure below:
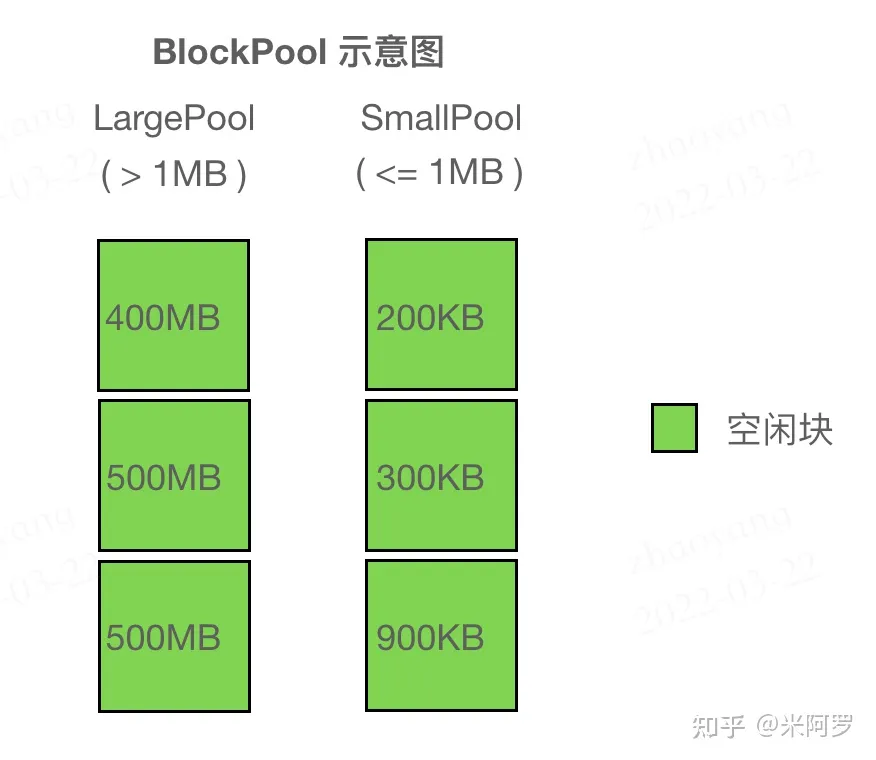
“Summary”: Blocks in the Allocator are organized in two ways: explicitly organized in BlockPool (red-black tree) sorted by size; and implicitly organized in a doubly linked list for contiguous address Blocks (through the prev and next pointers in the struct), allowing O(1) time checks for adjacent Blocks to see if they are free, facilitating merging fragments when freeing the current Block.
2.2 malloc Function Analysis: Returns a Usable Block (L466)
A Distinction:
For brevity, the following text will differentiate between these two expressions without further elaboration.
-
“size”: The requested size of memory allocation. -
“alloc_size”: The size of memory needed for cudaMalloc.
A Hard-coded:
The actual alloc_size is determined based on size (get_allocation_size function, L1078):
-
Allocate 2MB for sizes less than 1MB; -
Allocate 20MB for sizes between 1MB and 10MB; -
Allocate {size rounded up to the nearest 2MB multiple} MB for sizes >= 10MB.
Finding a suitable block involves “five steps”. If none of these five steps find a suitable Block, the classic [CUDA out of memory. Tried to allocate …] error will occur (see below for the “allocation failure situation”).
2.3 Step One: get_free_block Function (L1088)
“TLDR”: Attempt to find a suitably sized free Block in the Allocator’s own maintained pool.
-
TLDR = Too Long; Didn’t Read -
Create a Block Key using the current (size, stream_id) pair to search in the corresponding BlockPool; -
The environment variable PYTORCH_CUDA_ALLOC_CONFspecifies a thresholdmax_split_size_mb, and there are two cases where allocation will not occur in this step:
-
The required size is less than the threshold but the found Block is larger than the threshold (to avoid wasting a block); -
Both sizes are larger than the threshold but the block size exceeds the required size by too much (here the buffer is 20MB, so the largest fragment does not exceed the buffer size).
-
This threshold max_split_size_mbinvolves an interesting feature that will be discussed later. -
If a Block is successfully allocated, it will be removed from the BlockPool. When it is later freed, it will be inserted back in (see free_block: L976).
2.4 Step Two: trigger_free_memory_callbacks Function (L1106)
“TLDR”: Manually perform a round of garbage collection to reclaim unused Blocks, then execute step one again.
-
If the first step’s get_free_blockfails, in the second step, first calltrigger_free_memory_callbacks, then call the first step’sget_free_blockagain; -
trigger_free_memory_callbacksessentially calls theCudaIPCCollectfunction through registered callbacks, which in turn callsCudaIPCSentDataLimbo::collectfunction (torch/csrc/CudaIPCTypes.cpp : L64); -
The CudaIPCSentDataLimboclass manages all Blocks with a non-zero reference count, so the call to collect is essentially a lazy update, called only when there are no Blocks available for allocation to clean up those “Blocks with reference count already at 0” (notably, the destructor of this class will first call the collect function, see torch/csrc/CudaIPCTypes.cpp : L58); -
Related source code can be found in torch/csrc/CudaIPCTypes.h&.cpp.
2.5 Step Three: alloc_block Function (L1115)
“TLDR”: If the Allocator cannot find a suitable Block among the existing ones, it calls cudaMalloc to create a new Block.
-
If the reuse of blocks fails in steps one and two, then use cudaMalloc to allocate memory of size alloc_size; -
Note that there is a parameter set_fraction that limits the allocatable memory to the current remaining memory * fraction (if the requested allocation exceeds this limit, it fails), but it is still unclear where this will be specified (TODO); -
The newly allocated memory pointer will be used to create a new Block, with the new Block’s device and cuda_stream_id consistent with the caller.
The above steps attempt to find some “free memory”, while the following two steps attempt to perform “fragmentation management” to create a larger block of memory.
2.6 Step Four: release_available_cached_blocks Function (L1175)
“TLDR”: First release some larger Blocks in its own pool, then use cudaMalloc to allocate again.
-
If the alloc_blockabove fails, it will try to call this function to find the largest Block among those smaller than size, releasing them from largest to smallest until the total size of released Blocks >= size (note that this step will only release those Blocks larger than the thresholdmax_split_size_mb, which can be understood as first releasing some larger ones); -
The function to release blocks is seen in release_block(L1241), which mainly involves cudaFree the pointer, handling CUDA graphs dependencies, updating other data structures, and finally removing this Block from the BlockPool; -
Blocks that can be released from the current entire BlockPool (as a reminder, the Allocator has two BlockPools, here referring to the initially specified large or small pool based on size) must meet two conditions: the cuda_stream_id must be the same, and the size must be larger than the threshold max_split_size_mb. If all such Blocks are released and the space is still smaller than size, then this step will fail. -
After releasing a batch of Blocks, the alloc_blockfunction from step three is called again to create a new Block.
2.6 Step Five: release_cached_blocks Function (L1214)
-
If releasing some Blocks is still insufficient, all large/small pools in the Allocator are released (also calling release_block: L1241), and the alloc_blockfunction is called again.
2.7 Situations Where malloc Allocation Fails
It will report the classic CUDA out of memory. Tried to allocate ... error, for example:
CUDA out of memory. “Tried to allocate” 1.24 GiB (GPU 0; 15.78 GiB “total capacity”; 10.34 GiB “already allocated”; 435.50 MiB “free”; 14.21 GiB “reserved” in total by PyTorch)
-
“Tried to allocate”: refers to the expected alloc_size during this malloc; -
“total capacity”: total memory of the device returned by cudaMemGetInfo; -
“already allocated”: the total size of requests allocated so far recorded by statistics; -
“free”: the remaining memory of the device returned by cudaMemGetInfo; -
“reserved”: the total size of all Blocks in the BlockPool, along with the total size of already allocated Blocks.
That is, [reserved] = [already allocated] + [sum size of 2 BlockPools]
Note that reserved + free does not equal total capacity because reserved only records the memory allocated through PyTorch; if the user manually calls cudaMalloc or allocates memory through other means, it cannot be tracked in this error message (and since generally, the memory allocated by PyTorch accounts for most, the allocation failure error message is usually reported by PyTorch).
In this example, the device only has 435.5MB left, which is insufficient for 1.24GB, while PyTorch retains 14.21GB (stored in Blocks), of which 10.3GB is allocated, leaving 3.9GB. So why can’t it allocate 1.2GB from this remaining 3.9GB? The reason is definitely fragmentation, and even after attempting to organize, it still fails.
3. Key Features for Implementing Automatic Fragmentation Management: Split
As previously mentioned, the environment variable specifies a threshold max_split_size_mb, which actually indicates the maximum size of Blocks that can be “split”.
In the beginning of this section, it was explained that the alloc_block function in step three creates a new Block of size alloc_size calculated based on the alloc_size instead of the user-requested size. Therefore, if malloc successfully returns a Block in the above five steps, the Allocator will check through the function should_split (L1068):
-
Due to excessive memory allocation, the size of the remaining fragment within the Block, alloc_size – size, is referred to as remaining; -
If this Block belongs to small_blocks and remaining >= 512 Bytes; or remaining >= 1MB and the size of this Block does not exceed the aforementioned threshold, then this Block needs to be split.
The operation of splitting is straightforward; the current Block will be divided into two Blocks, the first being exactly the requested size, and the second being the size of remaining, which will be linked to the next pointer of the current Block (this process can be seen in the source code L570–L584). As the program runs, larger Blocks (as long as they remain below the threshold max_split_size_mb) will continue to be split into smaller Blocks. It is noteworthy that since the only way to create new Blocks is through the alloc_block function in step three via cudaMalloc, there is no guarantee that new Blocks will be contiguous with other Blocks, so all Blocks maintained in the doubly linked list with contiguous address space are derived from an initially allocated Block.
A segment of contiguous space internally (the Blocks organized by the doubly linked list) is shown in the figure below:
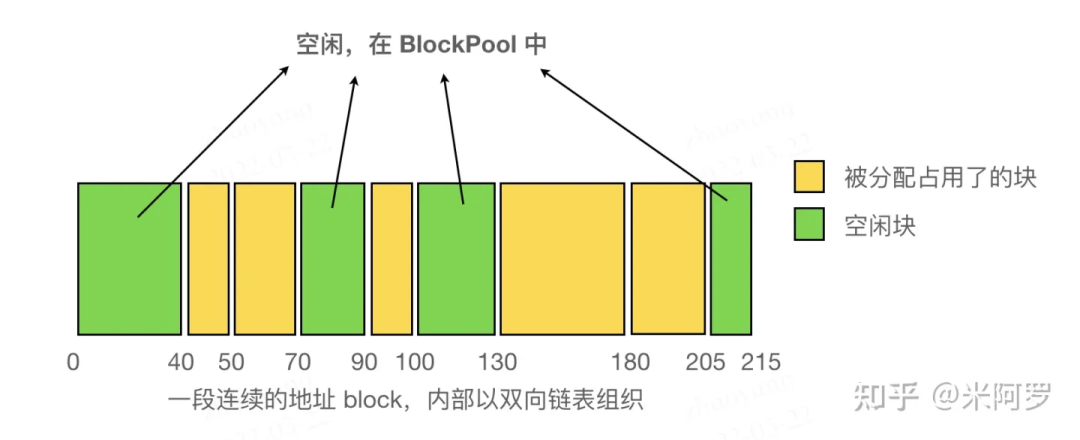
When a Block is released, it checks whether its prev and next pointers are null, and if not, whether they are in use. If they are not in use, it will use try_merge_blocks (L1000) to merge adjacent Blocks. Since each Block release checks for this, there will never be two adjacent free Blocks, so only the adjacent Blocks need to be checked for availability. This checking process can be seen in the free_block function (L952). Because only when releasing a Block can multiple free blocks become contiguous, fragmentation management is only necessary when releasing Blocks.
Regarding the threshold max_split_size_mb, intuitively, it should be set such that larger Blocks are split into smaller ones; however, it is set to split Blocks smaller than this threshold. My understanding is that PyTorch statistically assumes most memory requests are below a certain threshold, and these smaller Blocks are processed conventionally, split, and managed for fragmentation; whereas for larger Blocks, PyTorch believes that these large allocations have significant overhead (time, risk of failure) and should be reserved for future larger requests, hence not suitable for splitting. By default, the threshold variable max_split_size_mb is set to INT_MAX, meaning all Blocks can be split.
4. Conclusion
Analyzing the PyTorch memory management mechanism can help us better find ideas for memory optimization. Currently, we are collaborating with the author of Dynamic Tensor Rematerialization (DTR) @Round Corner Knight Marisa to promote the industrial application of DTR technology on PyTorch, one of which is to address the memory fragmentation issue mentioned in the training process of this article. A forthcoming article will introduce the problems encountered during the implementation of DTR and the solutions & benchmark, stay tuned.
5. Recommended Reading
Model Deployment Series | How to Solve the Oscillation Problem Encountered During AI Model QAT Quantization?
Super-resolution Model | One Line of Code to Achieve Pain-free Upscaling, Single Image Super-resolution Also Requires Dropout

25FPS! First Release on the Internet | NVIDIA Releases BEVFusion Deployment Source Code for Real-time Operation on Edge Devices!!!
