
MLNLP ( Machine Learning Algorithms and Natural Language Processing ) community is a well-known natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and corporate researchers.
The vision of the community is to promote communication between the academic and industrial fields of natural language processing and machine learning, as well as among enthusiasts, especially for beginners.
Reprinted from | PaperWeekly
©Author | serendipity
Institution | Tongji University
Research Direction | Pedestrian Search, 3D Human Pose Estimation
1
Introduction
1
Introduction
Perhaps by design, this bug currently exists in the code of many people. Even Tesla’s AI director Karpathy has fallen into this trap and tweeted about it.
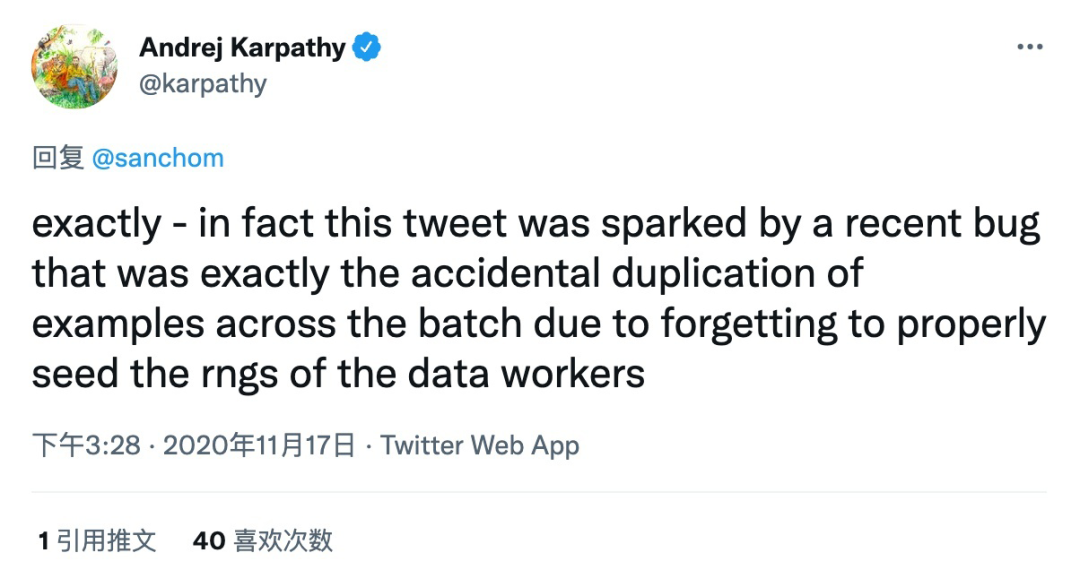
In fact, this tweet was triggered by a recent bug caused by forgetting to correctly set the random seed for DataLoader workers, which accidentally repeated batch data throughout the training process.
2
The Hidden Bug of PyTorch DataLoader
2
The Hidden Bug of PyTorch DataLoader
<span>torch.utils.data.Dataset</span> and override its <span>__getitem__</span> method. To apply data augmentation, such as random cropping and image flipping, this <span>__getitem__</span> method typically uses NumPy to generate random numbers. The dataset is then passed to <span>DataLoader</span> to create batches. Data preprocessing can be a bottleneck in network training, so sometimes parallel data loading is required, which can be achieved by setting the num_workers parameter of the <span>DataLoader</span>.import numpy as np
from torch.utils.data import Dataset, DataLoader
class RandomDataset(Dataset):
def __getitem__(self, index):
return np.random.randint(0, 1000, 3)
def __len__(self):
return 8
dataset = RandomDataset()
dataloader = DataLoader(dataset, batch_size=2, num_workers=2)
for batch in dataloader:
print(batch)
tensor([[116, 760, 679], # First batch, returned by process 0
[754, 897, 764]])
tensor([[116, 760, 679], # Second batch, returned by process 1
[754, 897, 764]])
tensor([[866, 919, 441], # Third batch, returned by process 0
[ 20, 727, 680]])
tensor([[866, 919, 441], # Fourth batch, returned by process 1
[ 20, 727, 680]])
3
Cause of the Problem
3
Cause of the Problem
4
Solution
4
Solution
Note: The spawn method builds a subprocess from scratch and does not inherit the random state from the parent process. torch.multiprocessing uses fork by default on Unix systems, while on MacOS and Windows, it defaults to spawn . Therefore, this problem only occurs on Unix. Of course, you can also force the use of fork to create subprocesses on MacOS and Windows.
<span>DataLoader</span> has an optional parameter in its constructor called <span>worker_init_fn</span>. Before loading data, this function is called for each subprocess. We can set the NumPy seed in worker_init_fn, for example:def worker_init_fn(worker_id):
# np.random.get_state(): gets the current Numpy random state, which is the main process's random state
# worker_id is the id of the subprocess, if num_workers=2, the ids of the two subprocesses are 0 and 1
# Adding worker_id ensures that the random number seeds of each subprocess are different
np.random.seed(np.random.get_state()[1][0] + worker_id)
dataset = RandomDataset()
dataloader = DataLoader(dataset, batch_size=2, num_workers=2, worker_init_fn=worker_init_fn)
for batch in dataloader:
print(batch)
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[180, 413, 50],
[894, 318, 729]])
tensor([[530, 594, 116],
[636, 468, 264]])
for epoch in range(3):
print(f"epoch: {epoch}")
for batch in dataloader:
print(batch)
print("-"*25)
epoch: 0
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------
epoch: 1
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------
epoch: 2
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------
<span>np.random.get_state()[1][0] + epoch + worker_id</span><span>.</span><span>worker_init_fn</span><span> . However, </span><code><span>torch.initial_seed()</span><span> <span>can meet our needs.</span></span>def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2**32
np.random.seed(worker_seed)
<span>worker_init_fn</span><span> to the above </span><code><span>seed_worker</span><span> function. For those interested in understanding the underlying principles, please see the next section, which will involve understanding the source code of DataLoader.</span>
5
Why Does torch.initial_seed() Work?
5
Why Does torch.initial_seed() Work?
<span>DataLoader(dataset, num_workers=2)</span><span> in the main process. </span><span>Queue1 = [0, 2], Queue2 = [1, 3]</span><span> means the first subprocess should be responsible for fetching the 0th and 2nd data, while the second process is responsible for the 1st and 3rd data. When the user wants to fetch the </span><span> </span><code><span>index</span><span> data, the main process first checks which subprocess is idle. If the second subprocess is idle, it puts the </span><code><span>index</span><span> into Queue2. It then creates a result_queue <span>[8] </span> to store the data read by the subprocess, formatted as </span><span> </span><code><span>(index, dataset[index])</span><span>.</span><span>base_seed</span><span> b) Use </span><code><span>fork</span><span> to create 2 subprocesses <span>[10]</span>. In each subprocess, </span><strong><span>set the random seeds for </span><span> <code>torch and random to base_seed + worker_id. Then keep querying whether there is data in their respective queues. If there is, they fetch the <span>index</span><span> from </span> <span>dataset</span><span> to get the </span> <code><span>dataset[index]</span><span> and save the result to </span><span>result_queue</span><span>.</span><span>torch.initial_seed()</span><span>, the returned value is the current random seed of </span><span>torch</span><span>, which is </span><span>base_seed + worker_id</span><span>. Because at the beginning of each epoch, the main process regenerates a new </span><span>base_seed</span><span>, <strong>therefore </strong></span><span><strong> base_seed </strong></span><span><strong> is a random number that changes with the epoch count</strong>. Additionally, </span><code><span>torch.initial_seed()</span><span> returns a </span><span>long int</span><span> type, while NumPy only accepts </span><code><span>uint</span><span> type (</span><code><span>[0, 2**32 - 1]</span>), so it needs to be taken modulo 2**32.<span>torch</span><span> or </span><span>random</span><span> to generate random numbers instead of </span><span>numpy</span><span>, we do not have to worry about encountering this problem because PyTorch has already set the random numbers for </span><span>torch</span><span> and </span><span>random</span><span> to </span><span>base_seed + worker_id</span><span>.</span>-
PyTorch version < 1.9 -
Using NumPy’s random number in the <span>__getitem__</span><span> method of the Dataset</span>
6
Appendix
6
Appendix
-
pytorch-image-models [11] def seed_worker(worker_id): worker_info = torch.utils.data.get_worker_info() # worker_info.seed == torch.initial_seed() np.random.seed(worker_info.seed % 2**32) -
@晚星 [12] def seed_worker(worker_id): seed = np.random.default_rng().integers(low=0, high=2**32, size=1) np.random.seed(seed) -
@ggggnui [13] class WorkerInit: def __init__(self, global_step): self.global_step = global_step def worker_init_fn(self, worker_id): np.random.seed(self.global_step + worker_id) def update_global_step(self, global_step): self.global_step = global_step worker_init = WorkerInit(0) dataloader = DataLoader(dataset, batch_size=2, num_workers=2, worker_init_fn=worker_init.worker_init_fn) for epoch in range(3): for batch in dataloader: print(batch) # Note that len(dataloader) must be >=num_workers, otherwise it will still repeat worker_init.update_global_step((epoch + 1) * len(dataloader))

Scan the QR code to add assistant WeChat
About Us
