Original Content, First Release, No Reprints
In the previous articles “Understanding Neural Networks: CNN” and “Building CNN Networks with Fashion-MNIST Dataset (Including Code)”, we provided a detailed introduction to the architecture and specific implementation of CNN networks, among which the most classic CNN networks include LeNet-5, AlexNet, GoogLeNet, ResNet, etc. Today, I will explain another type of deep learning neural network: RNN.
01

Significance and Application Areas of RNN
If you are familiar with the BP algorithm or the CNN network we discussed earlier, you will find that their outputs only consider the influence of the previous input and do not take into account the influence of other inputs at different times. For example, recognizing simple images like cats, dogs, or handwritten digits shows good performance. However, for tasks related to time, such as predicting the next moment in a video or predicting the content of documents based on context, these algorithms do not perform well. Therefore, RNN was born.
RNN is an abbreviation for two types of neural network models: Recursive Neural Network and Recurrent Neural Network. Although these two neural networks are intricately connected, this article mainly discusses the second type of neural network model—Recurrent Neural Network.
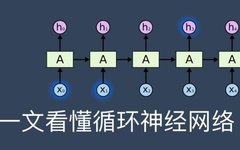
A Recurrent Neural Network is a type of neural network that takes sequence data as input and outputs sequence data, recursively processing in the direction of the sequence while all nodes (recurrent units) are connected in a chain.
It not only considers the input from the previous moment but also gives the network a kind of “memory” functionality for previous content. Specifically, the network remembers previous information and applies it to the current output calculation, meaning that the nodes between hidden layers are no longer unconnected but connected, and the inputs to the hidden layer include not only the outputs from the input layer but also the outputs from the previous hidden layer.
RNN is currently widely used in various fields and has mostly been integrated into our daily lives, mainly including:
① Natural Language Processing (NLP): covering video processing, text generation, and image processing;
② Speech Recognition, Machine Translation;
③ Text Analysis: calculating article similarity, recommending similar public accounts, etc.;
④ Video and Image Analysis: product recommendations, video recommendations, etc.

02

Principles and Architecture of RNN
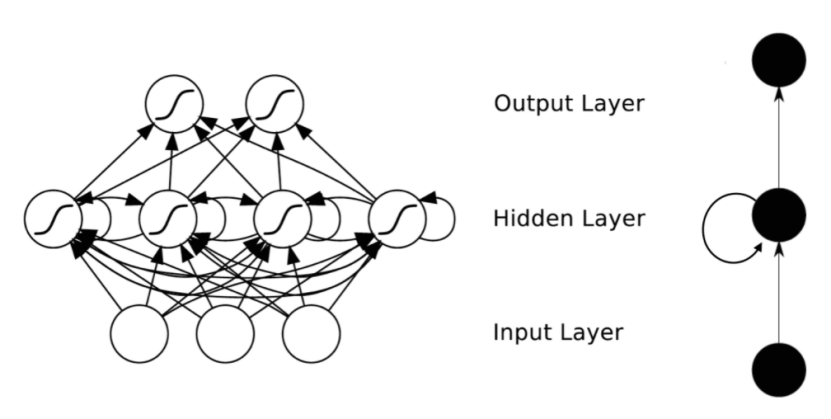
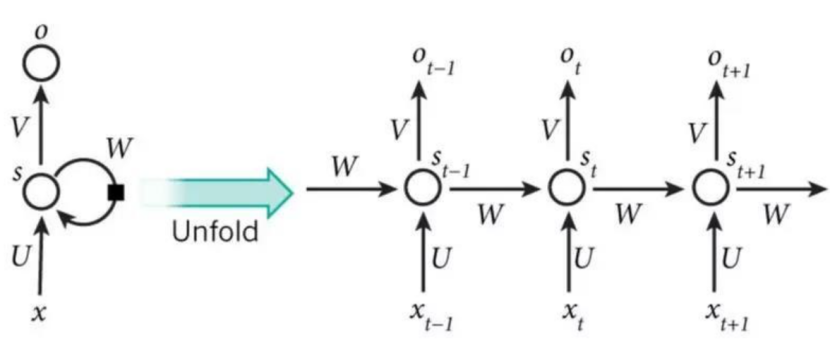
As shown in the figure above, the hierarchical structure of RNN is relatively simple compared to CNN, consisting mainly of an input layer, a hidden layer, and an output layer. You will notice an arrow in the Hidden Layer indicating the cyclical update of data, which is the method to achieve temporal memory functionality.
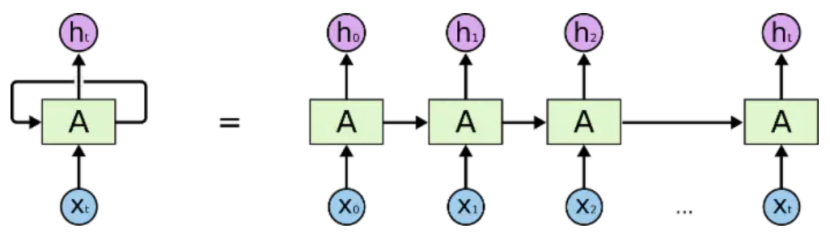
From the figure above, a typical RNN network contains an input xt, an output ht, and a neural network unit A. Unlike ordinary neural networks, the neural network unit A in RNN is not only connected to the input and output but also has a loop with itself. This network structure reveals the essence of RNN: the network state information from the previous moment will affect the network state at the next moment.
The equivalent RNN network on the right side of the equation has the initial input as x0 and the output as h0, representing that at time 0, the input to the RNN network is x0, and the output is h0, with the state of the network neuron at time 0 stored in A. When the next moment, time 1, arrives, the state of the network neuron is determined not only by the input x1 at time 1 but also by the state of the neuron at time 0. This continues until the end of the time series at time t.
Thus, we can understand the hidden state as: ht=f(current input + past memory summary)
Additionally, unlike CNN, the parameters of the entire neural network in RNN are shared states, which greatly reduces the number of parameters that need to be trained and estimated.
03

Parameter Updates in RNN
In general, RNNs propagate weights bidirectionally, meaning they have both forward and backward propagation, continuously updating parameters W, V, U.
The state of neuron A at time t is determined solely by the state of the neuron at time t-1 and the hyperbolic tangent function value of the input at time t. This value not only serves as the output of the network at that moment but also is passed as the state of the network to the next moment, a process called RNN’s forward propagation. The analytical form of the hyperbolic tangent function is as follows:
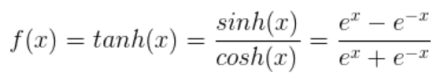
For backward propagation, since each output value generates an error value Et, the total error can be expressed as:
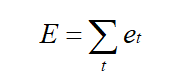
Moreover, each step’s output not only depends on the current network but also requires the states of several previous steps, thus this modified BP algorithm is called Backpropagation Through Time (BPTT), which means that the error value from the output end is transmitted backward, and parameters are updated using gradient descent, requiring the gradient of the parameters:
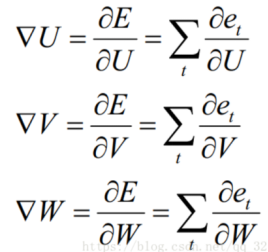
04

Problems and Improvements of RNN
Compared to shallow neural networks or CNNs, RNN solves the previous problem of information retention, but RNN has the problem of long-term dependencies. For instance, when analyzing a movie, some plot inferences require reliance on details from a long time ago. As the time interval increases, RNN loses the ability to learn connections that are so far apart. Additionally, RNN faces issues like gradient vanishing and gradient explosion.
To address these issues, a series of improved algorithms have emerged, mainly including LSTM (Long Short Term Memory) and GRU networks.
LSTM can retain important information and discard unimportant content through a “gate” structure, outputting a probability value between 0 and 1 through a Sigmoid layer, describing how much of each part can pass through; GRU, proposed in 2014, is an improved algorithm of LSTM that merges the forget gate and input gate into a single update gate while also combining the cell state and hidden state, making the model structure simpler compared to LSTM.
