

1. The Principle of One-Hot Encoding
Feature Digitization: Converts categorical variables (also known as discrete features, unordered features) into a format suitable for machine learning algorithms.

Feature Digitization
Creates a new binary feature for each possible value of each categorical feature (i.e., “one-hot” feature), where only one feature is activated (marked as 1) at any given time, and all other features are marked as 0.
-
Step 1: Identify Animal Categories First, identify the animal categories that need to be classified. In this example, we have four types of animals: cat, dog, turtle, and fish.
-
Step 2: Create Binary Feature Vectors Create a binary feature vector for each animal category. The length of the vector equals the number of animal categories, which in this case is 4. For each animal, only the corresponding feature position is 1, and all other positions are 0.
-
Step 3: Apply One-Hot Encoding to Animals Based on each animal’s category, convert it to the corresponding one-hot encoding representation. In this example, the encoding for a cat is [1, 0, 0, 0], for a dog it is [0, 1, 0, 0], for a turtle it is [0, 0, 1, 0], and for a fish it is [0, 0, 0, 1].
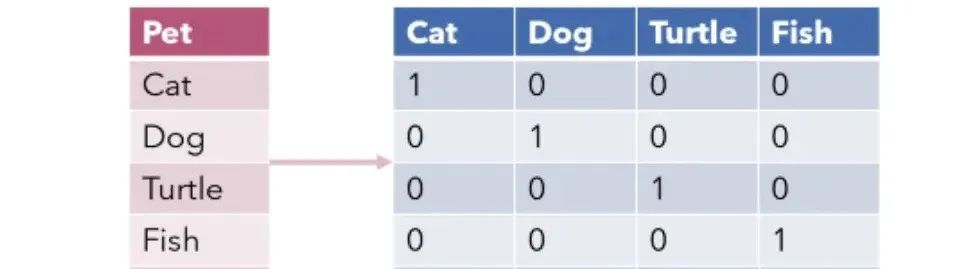
Applying One-Hot Encoding to Animals
One-Hot Encoding: Using N-bit state registers to encode N states, where each state is represented by its independent register bit, and at any moment only one bit is valid (i.e., set to 1).
One-Hot Encoding
Advantages:
-
Solves the problem of processing categorical data: One-hot encoding transforms discrete categorical features into a binary format that machine learning algorithms can easily handle, enhancing the algorithm’s ability to work with discrete features.
-
Avoids introducing numerical bias: By mapping each category to an independent binary vector, one-hot encoding eliminates any erroneous numerical relationships that may exist between categories, thereby preventing the algorithm from making inaccurate predictions based on these relationships.
Disadvantages:
-
Increased dimensionality: When the number of categories is large, one-hot encoding can significantly increase the dimensionality of the feature space, potentially leading to computational complexity and overfitting issues.
-
Risk of information loss: One-hot encoding may not fully capture the potential relationships or ordinal information between categories, leading to the loss of useful information in some cases.
2. Classification of One-Hot Encoding
Based on Categorical Values One-Hot Encoding: One-hot encoding is an effective preprocessing method for data with clearly defined categorical values, ensuring that the model correctly understands non-numeric categorical features and avoids misinterpretation of numerical relationships.
Based on Categorical Values One-Hot Encoding
-
For data with clearly defined categorical values:
One-hot encoding is particularly suitable for processing data with clear, finite, and usually non-numeric categorical values. For example, in the gender feature, we have two categorical values: “male” and “female,” which have no numerical size or order relationship. Similarly, in the color feature, “red,” “green,” and “blue” are also purely categorical labels without any implicit numerical meaning.
-
Each unique categorical value is converted to a binary vector:
-
In one-hot encoding, each unique categorical value is assigned a unique binary vector, also known as a “one-hot” vector, where only one position’s element is 1 (indicating the presence of that category), and all other position’s elements are 0. For example, if there are three color categories, then “red” might be encoded as [1, 0, 0], “green” as [0, 1, 0], and “blue” as [0, 0, 1].
-
Avoiding Misinterpretation of Numerical Relationships
One important reason for using one-hot encoding is that it prevents machine learning models from incorrectly interpreting any numerical relationships that may exist between categorical values. If the original categorical labels (e.g., integers or strings) are used directly, some models (especially those based on numerical calculations, such as linear regression) may try to establish numerical connections between these labels. By converting to one-hot encoding, each category is completely independent, and the model is not influenced by this potential misguidance.
Ordinal-Based One-Hot Encoding: Applying one-hot encoding to ordinal data may lose important ordinal information; therefore, it is necessary to carefully consider the risk of information loss and choose more appropriate encoding strategies based on model needs and scenarios.
One-Hot Encoding vs. Label Encoding
-
Information Loss:
-
One-hot encoding converts each ordinal category into independent binary vectors, leading to the loss of ordinal information in the original data.
-
For models or analyses that rely on the ordinal relationships between categories, this loss of information may affect the accuracy and interpretability of the results.
-
Model Applicability:
-
Some machine learning models (like decision trees and random forests) can implicitly handle ordinal relationships and may perform well even with one-hot encoding.
-
However, other models (like linear regression or neural networks) may require additional feature engineering to capture the lost ordinal information.
-
Alternatives:
-
When dealing with ordinal data, other encoding schemes can be considered, such as label encoding (mapping each ordinal to an integer), which preserves ordinal information but may introduce unnecessary numerical relationships.
-
Another approach is to create additional features to represent the relative relationships between categories, such as through comparisons or calculating distances between different categories.
3. Applications of One-Hot Encoding
Feature Engineering and One-Hot Encoding: One-hot encoding is an important step in processing categorical features in feature engineering, but its impact on feature dimensionality, sparsity, information representation, and model selection needs to be weighed.
Feature Engineering and One-Hot Encoding
-
Processing Categorical Features
-
Problem: Many machine learning algorithms cannot directly process categorical data because they require numerical inputs.
-
Role of One-Hot Encoding: Converts categorical variables into binary vectors, allowing algorithms to handle these variables. Each categorical value is mapped to a unique binary vector, where only one element is 1 (indicating the presence of that category), and all other elements are 0.
-
Feature Expansion
-
Impact: One-hot encoding increases the number of features in the dataset. For example, a categorical feature with n different values will be transformed into n new binary features.
-
Considerations: The increase in the number of features may affect the complexity of the model and training time. When the number of features increases significantly, feature selection or dimensionality reduction techniques may need to be considered.
-
Sparsity Introduction
-
Result: One-hot encoding typically produces a sparse feature matrix, where most elements are 0.
-
Impact: Sparsity may be an advantage for some algorithms (like linear models, tree models) as they can effectively handle sparse inputs. However, for other algorithms (like neural networks), sparse inputs may require special handling or optimization.
-
Information Representation
-
Advantages: One-hot encoding clearly represents the differences between categorical features without introducing any numerical bias.
-
Limitations: One-hot encoding does not retain any numerical or ordinal relationships between categories. If there is a natural order between categories (such as ratings: low, medium, high), one-hot encoding may lose this information.
-
Model Applicability
-
Selection Reason: One-hot encoding is chosen because many machine learning algorithms (like logistic regression, support vector machines, decision trees) perform better when handling numerical inputs.
-
Notes: Not all algorithms need or benefit from one-hot encoding. For instance, some tree-based algorithms (like random forests) can directly handle categorical features without one-hot encoding.
Data Preprocessing and One-Hot Encoding: One-hot encoding is a commonly used technique in data preprocessing, primarily for handling categorical data.
Data Preprocessing and One-Hot Encoding
-
Processing Categorical Data:
-
In datasets, it is common to encounter cases that contain categorical (or nominal) features, where the values are non-numeric, such as gender (male, female), color (red, green, blue), etc.
-
One-hot encoding is an effective method for converting these categorical features into a numerical format that machine learning models can understand.
-
Avoiding the Introduction of Ordinal Relationships:
-
If categorical feature labels (e.g., 1, 2, 3) are used directly as numerical inputs, the model may incorrectly interpret a numerical relationship between these labels (e.g., thinking 2 is twice 1, or 3 is greater than 2).
-
One-hot encoding eliminates this ordinal relationship by assigning each category an independent binary vector, ensuring that the model does not make predictions based on erroneous numerical assumptions.
-
Combining with Other Preprocessing Techniques:
-
One-hot encoding is often used in conjunction with other data preprocessing techniques, such as handling missing values, feature scaling, and feature selection.
-
Before applying one-hot encoding, it may be necessary to first handle missing values, as one-hot encoding is typically not suitable for categorical features with missing values. Additionally, after applying one-hot encoding, feature selection may also be needed to reduce dimensionality and redundancy.