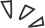Big Data Digest authorized reprint from Xi Xiaoyao Technology
Author | Xie Nian Nian
In interpersonal communication, especially when using a language as profound as Chinese, people often do not answer questions directly but instead adopt implicit, obscure, or indirect expressions.
Humans can make accurate judgments about some implied meanings based on past experiences or their understanding of the speaker. For example, we have experienced countless dialogue scenarios in our childhood:
“Mom, where is my book?”
“It’s in my hand, come and get it!”
Or:
“Mom, can I have braised pork today?”
“Do I look like braised pork?”
Faced with a response that seems to answer yet says nothing, we can quickly get the feeling that mom does not want to deal with us. Can LLMs understand the speaker’s true meaning when faced with similar conversational implicature?
Recently, Shanghai Jiao Tong University extracted the first Chinese multi-turn dialogue dataset targeting conversational implicature from the classic sitcom “Wulin Waizhuan,” selecting 200 carefully designed questions that fit conversational implicature and tested eight LLMs on multiple-choice tasks and metaphor explanation tasks. The results show that the task of conversational implicature remains challenging for LLMs.
Paper Title:Do Large Language Models Understand Conversational Implicature – A case study with a Chinese sitcom
Paper Link:https://arxiv.org/pdf/2404.19509
Dataset Construction
This paper selected the widely popular Chinese sitcom “Wulin Waizhuan” as the data source. The show not only contains a wealth of meaningful dialogues but also features beautifully written dialogue based on naturally occurring scenarios, making it highly suitable for evaluating language models’ abilities to understand and infer the deeper meanings of Chinese conversations.
Dataset Construction Principles
The Cooperative Principle is an important theory in linguistics proposed by American language philosopher Grice during his 1967 lecture “Logic and Conversation” at Oxford University. The Cooperative Principle includes four categories, each comprising a maxim and some sub-maxims, specifically:
-
Quality Maxim: a) Do not say what you believe to be false; b) Do not say that for which you lack adequate evidence; -
Quantity Maxim: a) Make your contribution as informative as is required; b) Do not make your contribution more informative than is required; -
Relation Maxim: Be relevant. For example, when asked, “Is John in the office?” Sam replies, “Today is Saturday, you know.” This violates the relation maxim because the answer is not directly related to the question, implying: “John never works on weekends, so he is not in the office.” -
Manner Maxim: Be perspicuous. a) Avoid obscurity; b) Avoid ambiguity; c) Be brief (avoid unnecessary prolixity); d) Be orderly.
However, in actual verbal communication, people do not always adhere to the “Cooperative Principle”; out of necessity, they may deliberately violate it. Grice referred to the implied meaning arising from this apparent violation of the “Cooperative Principle” as “conversational implicature.” This explains how listeners understand the speaker’s implied meaning through the surface meaning of their words, often resulting in humor.
This paper selects dialogues for creating a multi-turn dialogue Chinese dataset targeting conversational implicature based on these principles.
Identification and Classification of Implicature
Three authors selected dialogues containing conversational implicature from the script of “Wulin Waizhuan” by determining whether they violated conversational principles. To facilitate more detailed classification, they used sub-maxims as standards to evaluate whether target sentences satisfied each requirement. If a sentence violated a sub-maxim, it was considered a violation of that maxim. Dialogues may belong to multiple categories based on the violated sub-maxims. An example data entry, including dialogue, four explanations, and categories, is shown below:
Next, four explanations for the dialogue were constructed:
-
Pragmatic interpretation, which is the correct answer; -
Literal interpretation; -
Two contextually related distractors;
Based on the above explanations, multiple-choice questions were constructed, and a distinguished linguist was hired to answer and discuss incorrect answers and reasoning processes. This validation process ensures that the provided pragmatic understanding is closely aligned with common sense intuition and can be inferred from limited context. Necessary information such as character relationships, personalities, social backgrounds, and multimodal information was added at the beginning of the dialogue.
Human Scoring
To compare with human performance, 10 native speakers were invited to randomly answer 32 questions extracted from the dataset, achieving an average accuracy of 93.1%. The number of each type of question (i.e., cases where the dialogue violated Grice’s maxims) was the same in the questionnaire.
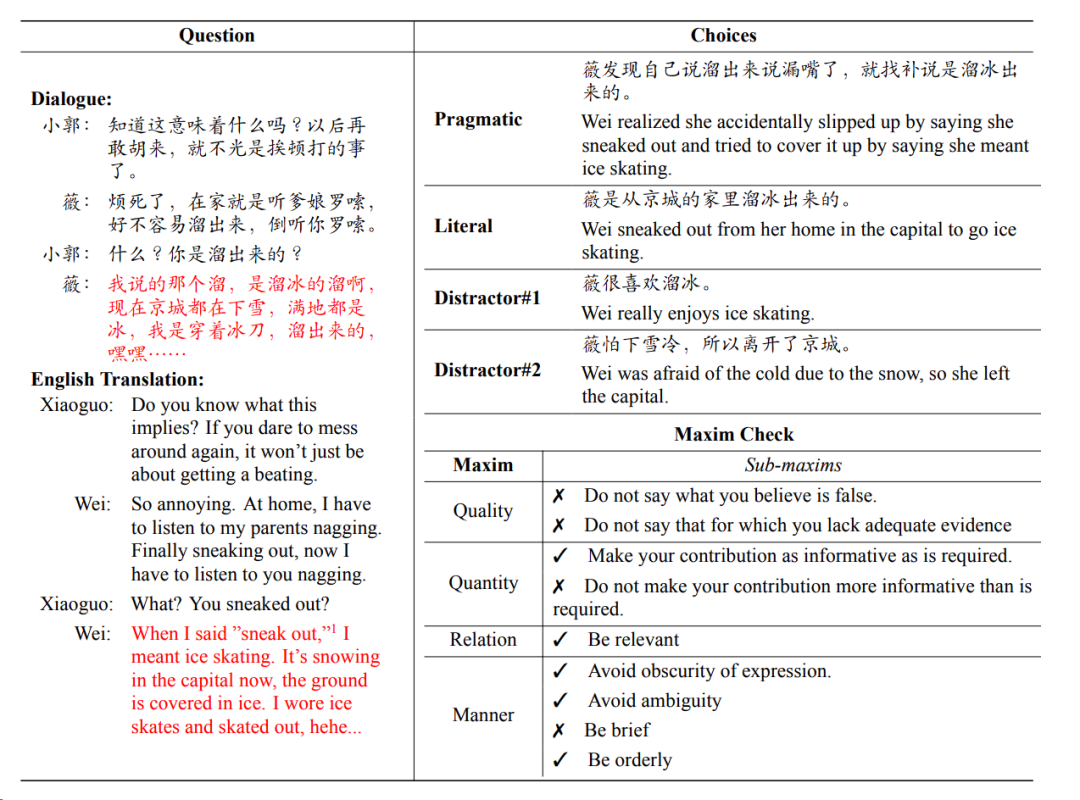
The final SwordsmanImp corpus contains 200 carefully selected questions, categorized according to the Cooperative Principle, as shown in the table below. Each entry includes multi-turn dialogue and four explanations of target sentences as choices.
Experiment 1: LLM Multiple-Choice Task
Experiment Setup
In this experiment, the model will see the dialogue and four manually created explanations. The task is to select the correct explanation for statements containing implicature.
The authors tested eight models, including both open-source and closed-source models, using zero-shot prompts to simulate real-life scenarios where humans encounter these implied meanings.
For open-source models, the established practice for LLM evaluation was followed, calculating the logits obtained after generating the tokens “A,” “B,” “C,” and “D,” selecting the one with the highest logit value as the model’s prediction; for closed-source models, they generated answers, which were then manually checked to determine which explanation was chosen.
Experiment Results
The experiment results are shown in the table below. GPT-4 achieved an accuracy of 94%, performing comparably to humans, demonstrating strong capability. Following closely was CausalLM (14B), with an accuracy of 78.5%, also showing impressive performance.
However, other models faced significant difficulties, with accuracy generally ranging from 20% to 60%. Notably, Textdavinci-002’s accuracy even failed to reach random levels (25%), indicating a substantial room for improvement in understanding implied meanings.
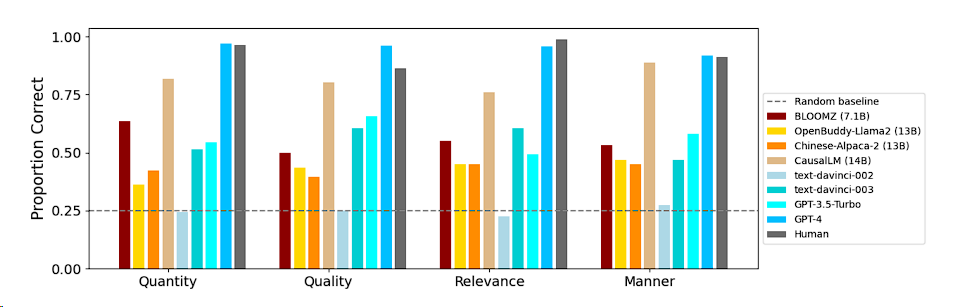
The table below details the performance of different models in violating different conversational maxims:
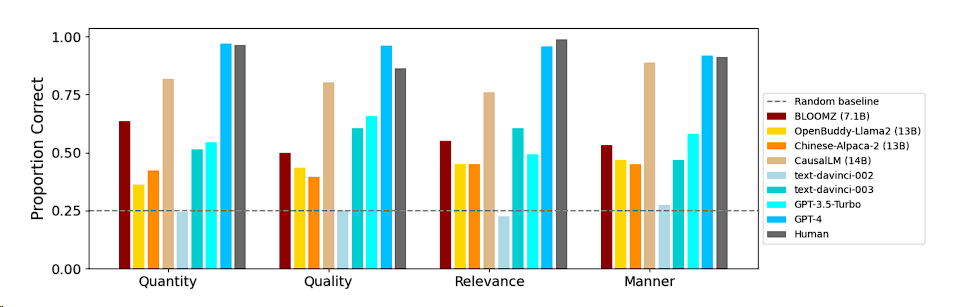
Overall, the models showed varied performance across different maxims, with no single model exhibiting consistent strengths or weaknesses across all maxims. Human responses also reflected this diversity.
Among open-source models, CausalLM (14B) had an accuracy close to human levels, performing the best among all open-source models, demonstrating its strong dialogue understanding capability.
GPT-4 stood out among all models, achieving over 90% accuracy across all categories of questions, further proving its leading position in the NLP field.
The diagram below shows the distribution of model selection in explanations. Red represents the model selecting the correct answer, i.e., the pragmatic explanation; yellow represents the selection of the literal meaning; while green represents the selection of two distractors.
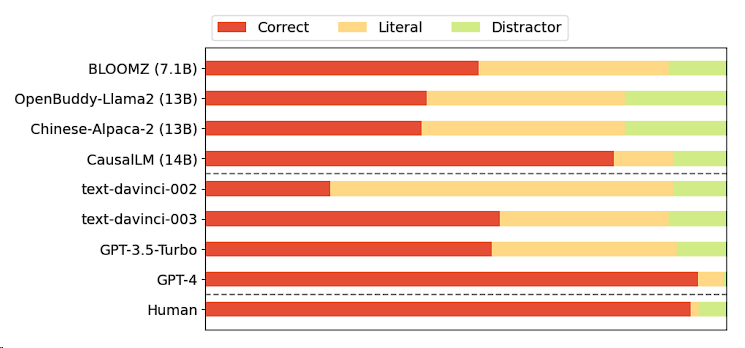
It can be seen that the two 13B models frequently chose distractors, which may suggest they are more easily influenced by irrelevant information in the context.
Additionally, as GPT models continue to evolve, they are gradually better at distinguishing between literal and implied meanings. Notably, GPT-4 shows a significant reduction in the proportion of literal understanding in explanation selections, further validating the model’s progress in understanding complex language phenomena.
Experiment 2: Evaluating the Quality of LLM-Generated Explanations
The authors designed open-ended questions requiring the model to generate explanations for implicature, which were then manually evaluated by native Chinese speakers based on the reasonability, logic, and fluency of the generated explanations. The results are shown in the table below:
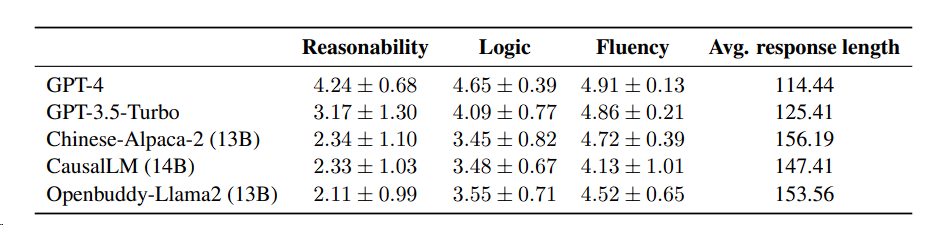
GPT-4 ranked first in all three dimensions, with the smallest variance in scores, demonstrating stable and excellent performance. GPT-3.5-Turbo also scored high, but with a larger standard deviation, reflecting some instability in its performance. The scores of the other three models were relatively close, with statistical tests showing no significant differences between them.
However, it is worth noting that CausalLM (14B) scored lower than GPT-3.5-Turbo, which is inconsistent with the observations in Experiment 1. This finding reveals that a model performing excellently in multiple-choice tasks may not necessarily excel in other tasks, such as providing coherent explanations of implied meanings. This further illustrates the performance differences that models may exhibit when handling different tasks.
The diagram below presents a typical dialogue example generated by a model.

By analyzing the implied meaning in Xiangyu’s dialogue, we can understand that she is actually warning Shitou not to drink anymore, while also conveying sarcasm and dissatisfaction towards him.
In the example, GPT-4 provided a concise explanation similar to the reference explanation, but it incorrectly interpreted the sarcastic tone as a questioning of Shitou’s drinking capacity.
CausalLM (14B) offered a correct explanation overall, but the quality of the answer was affected by poor fluency, resulting in English words and meaningless character sequences like “NST”. Notably, the expression “forgot his place” actually contains the correct meaning and can be seen as a switch of language codes rather than meaningless output.
Openbuddy-Llama2 (13B) provided a lengthy response that was unrelated to the question.
Analysis: How Well Do LLMs Understand Chinese Implicature?
The results of Experiment 1 indicate that GPT-4 demonstrated performance comparable to humans in the benchmark tests set in this paper, while other models lagged at least 15 points behind, including GPT-3.5-turbo.
This suggests that while theoretically advanced LLMs have the capability to learn and understand Chinese implicature, for most LLMs, it remains a challenging task.
The results of Experiment 2 reveal that a model (like CausalLM-14B) that performs excellently in multiple-choice questions may fail in free-text generation tasks when required to explain implicature independently. This finding highlights that relying solely on multiple-choice questions is insufficient for comprehensively assessing a language model’s linguistic abilities. Future designs could employ more complex methods to better quantify models’ free-form explanations of conversational implicature.
Conclusion
This paper constructed SwordsmanImp, the first fine-grained Chinese dataset for evaluating LLMs’ understanding of conversational implicature, and conducted assessments of LLMs’ understanding of Chinese conversational implicature through multiple-choice and free-generation explanation tasks. GPT-4 remains the strongest among all comparison models, even achieving human-level performance in multiple-choice question answering.