Machine Heart reports
Do language models plan for future tokens? This paper gives you the answer.
“Don’t let Yann LeCun see this.”
Yann LeCun said it was too late; he has already seen it. Today, we introduce the paper that “LeCun insists on seeing,” which explores the question: Is the Transformer a forward-thinking language model? When it reasons at a certain position, does it consider future positions in advance?
This research concludes that while Transformers have the capability to do so, they do not do it in practice.
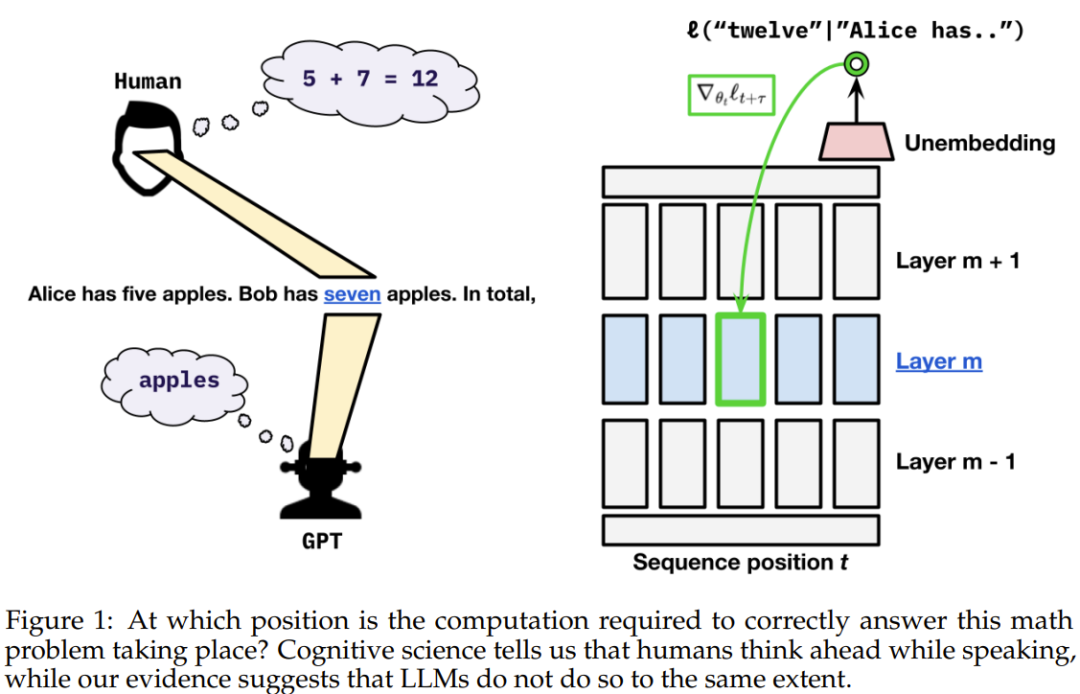
We all know that humans think before they speak. Decades of linguistic research show that when humans use language, they internally predict upcoming language inputs, words, or sentences.
Unlike humans, current language models allocate a fixed amount of computation for each token when they “speak.” So we can’t help but ask: Do language models think ahead like humans?
Recent studies have shown that by probing the hidden states of language models, it is possible to predict more tokens after the next token. Interestingly, by using linear probes on the model’s hidden states, it is possible to predict the model’s outputs on future tokens to a certain extent, and perturbing the hidden states can lead to predictable modifications of future outputs.
These findings suggest that the model activations at a given time step can predict future outputs to some extent.
However, we are still unclear about the reason: Is this merely a coincidental property of the data, or does the model deliberately prepare information for future time steps (which would affect the model’s performance at the current position)?
To answer this question, three researchers from the University of Colorado Boulder and Cornell University recently published a paper titled “Do Language Models Plan for Future Tokens?”

Paper Title: Do Language Models Plan for Future Tokens?
Paper Link: https://arxiv.org/pdf/2404.00859.pdf
Research Overview
They observed that the gradients during training optimize weights for the loss at the current token position and also optimize for the tokens that follow in the sequence. They further asked: How do the current transformer weights allocate resources between the current token and future tokens?
They considered two possibilities: the pre-caching hypothesis and the breadcrumbs hypothesis.

The pre-caching hypothesis suggests that the transformer computes features unrelated to the reasoning task at the current time step t that may be useful for future time steps t + τ, while the breadcrumbs hypothesis suggests that the features most relevant to time step t are equivalent to the features that will be most useful at time step t + τ.
To evaluate which hypothesis is correct, the team proposed a myopic training scheme that does not propagate the gradient of the loss at the current position to the hidden states of previous positions.
For the mathematical definitions and theoretical descriptions of the above hypotheses and schemes, please refer to the original paper.
Experimental Results
To understand whether language models can directly implement pre-caching, they designed a synthetic scenario where the task could only be completed through explicit pre-caching. They configured a task where the model must pre-compute information for the next token; otherwise, it cannot accurately compute the correct answer in a single forward pass.

The synthetic dataset defined by the team.
In this synthetic scenario, the team found compelling evidence that transformers can learn to pre-cache. When transformer-based sequence models must pre-compute information to minimize loss, they do so.
Subsequently, they explored whether natural language models (pre-trained variants of GPT-2) exhibit the breadcrumbs hypothesis or the pre-caching hypothesis. Their experiments with the myopic training scheme indicated that pre-caching occurred much less frequently in this setting, thus favoring the breadcrumbs hypothesis.
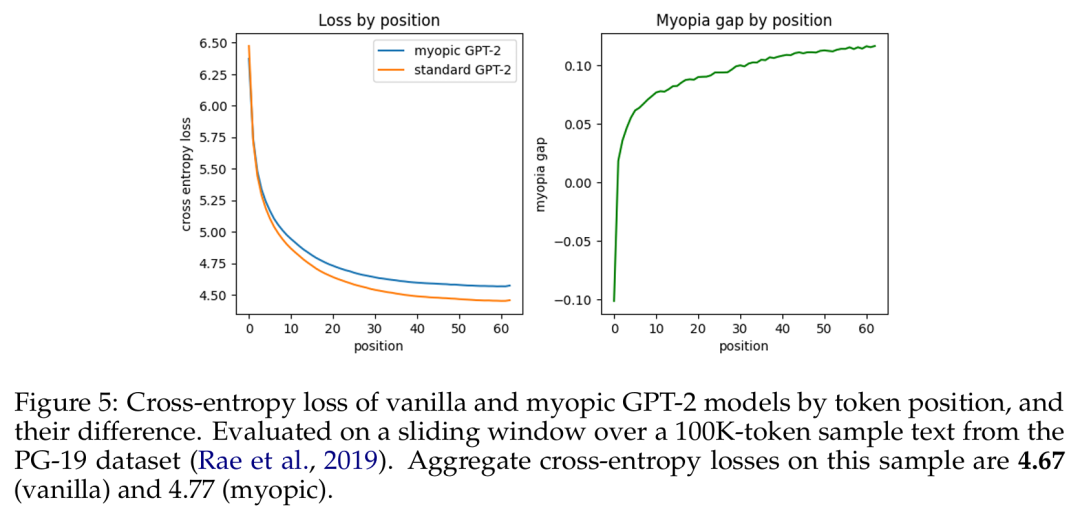
Cross-entropy loss and differences between the original GPT-2 model and the myopic GPT-2 model based on token positions.
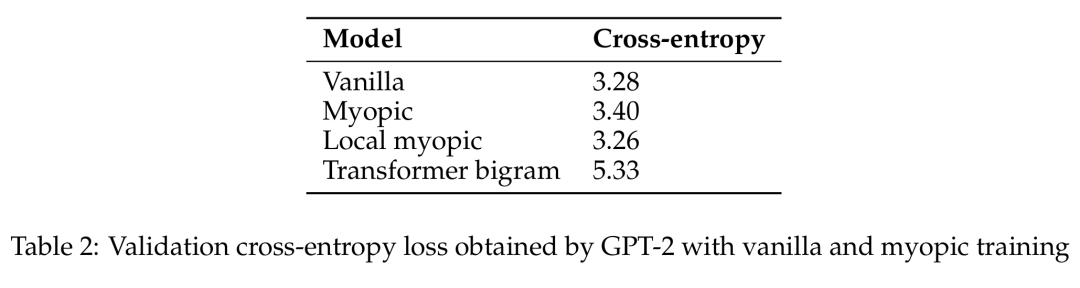
Validation cross-entropy loss obtained by GPT-2 through original and myopic training.
Thus, the team claims: On real language data, language models do not significantly prepare information for the future. Instead, they compute features useful for predicting the next token — which also turns out to be useful for future steps.
The team stated: “In language data, we observe no significant trade-off between greedily optimizing for the next token loss and ensuring future prediction performance.”
Therefore, we can probably see that whether the Transformer can think ahead seems to be fundamentally a data issue.
It can be imagined that perhaps in the future we can enable language models to possess the ability to think ahead like humans through appropriate data organization methods.

© THE END
For reprints, please contact this public account for authorization.
For submissions or inquiries: [email protected]