
Click the above “Beginner Learning Vision“, choose to add “Star” or “Top“
Important content delivered first
In recent years, the Attention mechanism has made significant breakthroughs in fields such as image processing and natural language processing, proving beneficial for enhancing model performance. The Attention mechanism itself aligns with the perception mechanisms of the human brain and eyes. In this article, we will primarily discuss the principles, applications, and model developments of the Attention mechanism in the field of computer vision.
1.1 What is the Attention Mechanism
The Attention mechanism refers to a mechanism that focuses on local information, such as a specific region in an image. As tasks change, the areas of attention often change.

When faced with an image like the one above, if you only look at it as a whole, you only see many heads of people. However, if you zoom in and look closely, you will find that they are all brilliant scientists.
In the image, all information other than the faces is actually useless and cannot accomplish any task. The Attention mechanism aims to find the most useful information, and the simplest scenario can be imagined as detecting faces in a photo.
1.2 Salient Object Detection Based on Attention
One task that arose alongside the Attention mechanism is salient object detection. Its input is an image, and the output is a probability map. The larger the probability, the more likely it represents an important target in the image, which is the focus of human attention. A typical saliency map is shown below:

The right image is the saliency map of the left image, with the highest probability at the head position, and the legs and tail also having relatively high probabilities. This is the truly useful information in the image.
Salient object detection requires a dataset, and such datasets are collected by tracking the eye movements of multiple subjects over a certain period to average their attention directions. The typical steps are as follows:
(1) Have the subjects observe the image.
(2) Use an eye tracker to record the position of their attention.
(3) Apply Gaussian filtering to aggregate the attention positions of all subjects.
(4) Record the results as probabilities ranging from 0 to 1.
Thus, we can obtain a diagram like the one below, where the second row shows the eye-tracking results, and the third row is the saliency probability map.

The above discussion pertains to spatial Attention mechanisms, focusing on different spatial locations. However, in CNN architectures, there are also different feature channels, thus similar principles apply to different feature channels, which we will discuss next.
The essence of the Attention mechanism is to locate the information of interest and suppress useless information, with the results typically presented as probability maps or probability feature vectors. From a theoretical standpoint, it can be mainly divided into spatial attention models, channel attention models, and mixed spatial and channel attention models, without distinguishing between soft and hard attention.
2.1 Spatial Attention Model
Not all regions in an image contribute equally to a task; only the task-relevant regions require attention, such as the main subject in a classification task. The spatial attention model seeks to identify the most important parts of the network for processing.
Here, we introduce two representative models. The first is the STN network (Spatial Transformer Network[1]) proposed by Google DeepMind. It learns the deformation of the input to perform preprocessing operations suitable for the task, making it a spatial-based Attention model. The network structure is as follows:
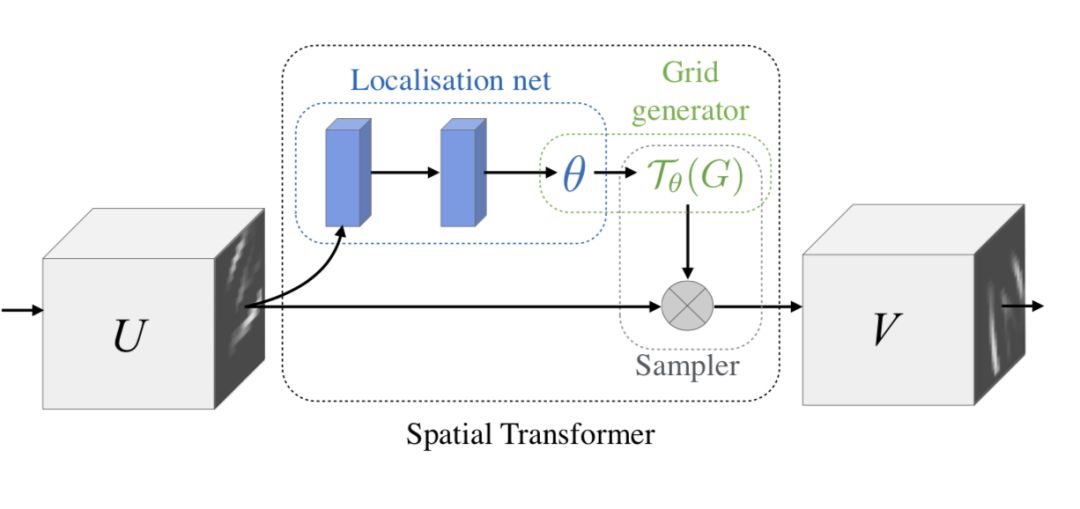
Here, the Localization Net is used to generate affine transformation coefficients, where the input is an image of size C×H×W, and the output is a spatial transformation coefficient that varies based on the type of transformation to be learned. If it is an affine transformation, it will be a 6-dimensional vector.
The effect that such a network aims to achieve is shown in the figure below:
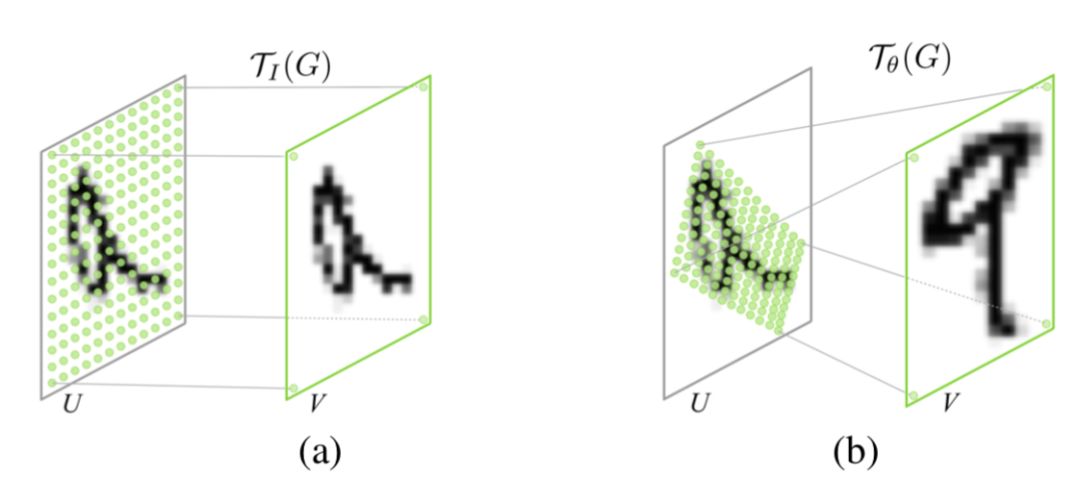
That is, it locates the target position and performs operations such as rotation, making the input samples easier to learn. This is a one-step adjustment solution, although there are many iterative adjustment solutions. If interested, you can read more in the knowledge-sharing community.
Compared to Spatial Transformer Networks, which complete localization and affine transformation adjustments in one step, Dynamic Capacity Networks[2] utilize two sub-networks: a low-performance sub-network (coarse model) and a high-performance sub-network (fine model). The low-performance sub-network (coarse model) processes the entire image to locate the regions of interest, as shown in the operations in the image. The high-performance sub-network (fine model) performs refined processing on the regions of interest, as seen in the operations in the image. Utilizing both together can achieve lower computational costs and higher accuracy.
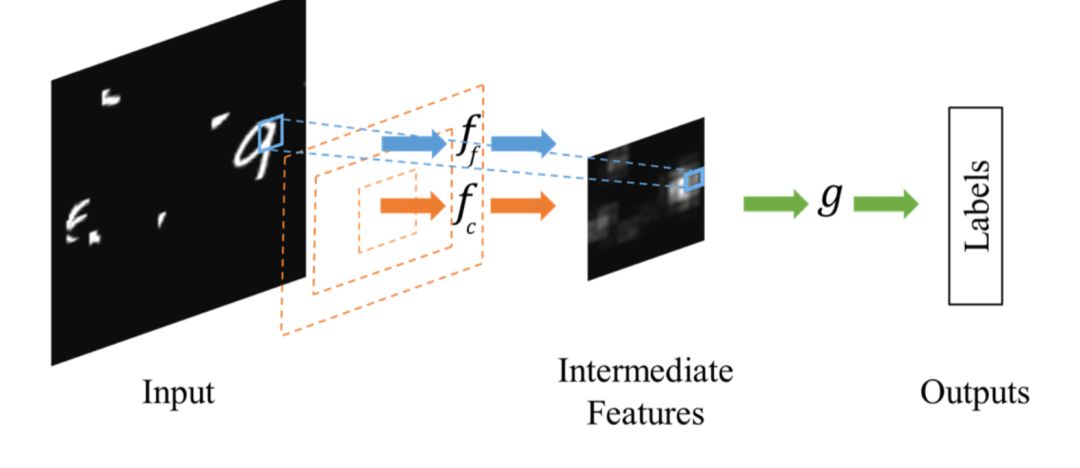
In most cases, the regions of interest are just a small part of the image, making the essence of spatial attention to locate the target and apply some transformations or obtain weights.
2.2 Channel Attention Mechanism
For a 2D image input to a CNN, one dimension is the image’s spatial scale (length and width), while the other dimension is the channel. Therefore, channel-based Attention is also a commonly used mechanism.
SENet (Squeeze and Excitation Net)[3] is the champion network of the 2017 ImageNet classification competition. Essentially, it is a channel-based Attention model that models the importance of each feature channel and enhances or suppresses different channels for various tasks. The principle diagram is as follows.
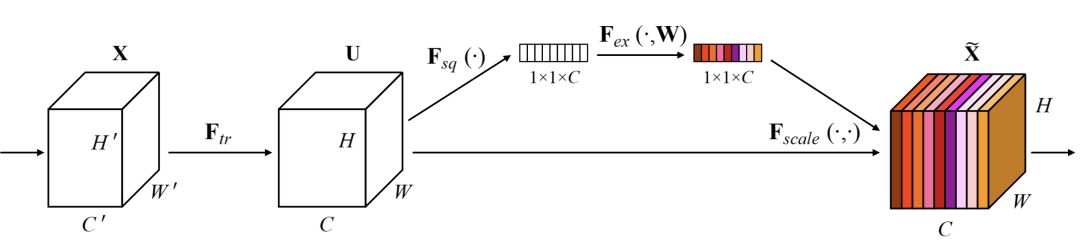
After the normal convolution operation, a bypass branch is split off. First, a Squeeze operation (denoted as Fsqr(·) in the diagram) is performed, where the spatial dimensions are compressed into a single value, equivalent to a pooling operation with a global receptive field, while the number of feature channels remains unchanged.
Then, an Excitation operation (denoted as Fex(·) in the diagram) generates weights for each feature channel using parameters w, which are learned to explicitly model the relationships between feature channels. In the paper, a two-layer bottleneck structure (first reducing dimensions and then increasing them) is used with a fully connected layer + Sigmoid function to achieve this.
Once the weights for each feature channel are obtained, they are applied to the original feature channels based on specific tasks, allowing for the learning of different channel importances.
The mechanism has been applied to several benchmark models, achieving significant performance improvements with minimal additional computational cost. As a universal design concept, it can be used in any existing network, making it highly practical. Subsequently, methods like SKNet[4] combined this channel weighting idea with the multi-branch network structure in Inception, also achieving performance improvements.
The essence of the channel attention mechanism lies in modeling the importance of each feature, allowing for feature allocation based on input for different tasks, which is simple yet effective.
2.3 Fusion of Spatial and Channel Attention Mechanisms
The aforementioned Dynamic Capacity Network focuses on spatial Attention, while SENet focuses on channel Attention. Naturally, spatial Attention and channel Attention mechanisms can also be used simultaneously.
CBAM (Convolutional Block Attention Module)[5] is a representative network in this regard, structured as follows:
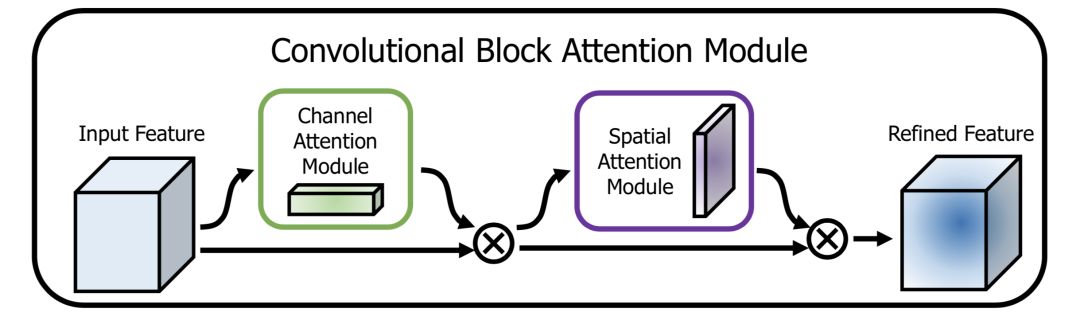
The channel direction Attention models the importance of features, structured as follows:
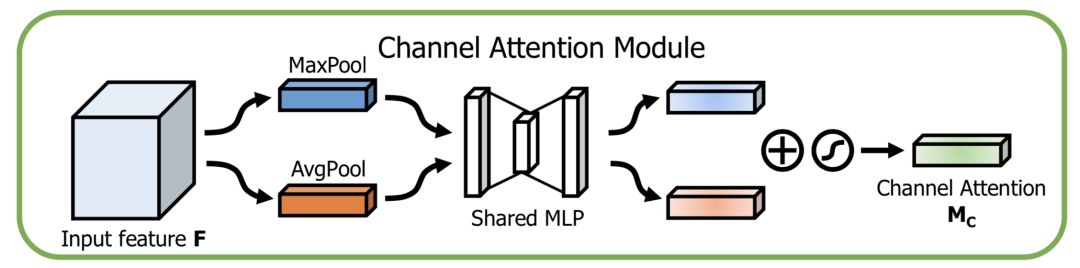
It simultaneously uses max pooling and average pooling algorithms, and then passes through several MLP layers to obtain transformation results, which are finally applied to both channels, using the sigmoid function to obtain the channel’s attention results.
The spatial direction Attention models the importance of spatial locations, structured as follows:
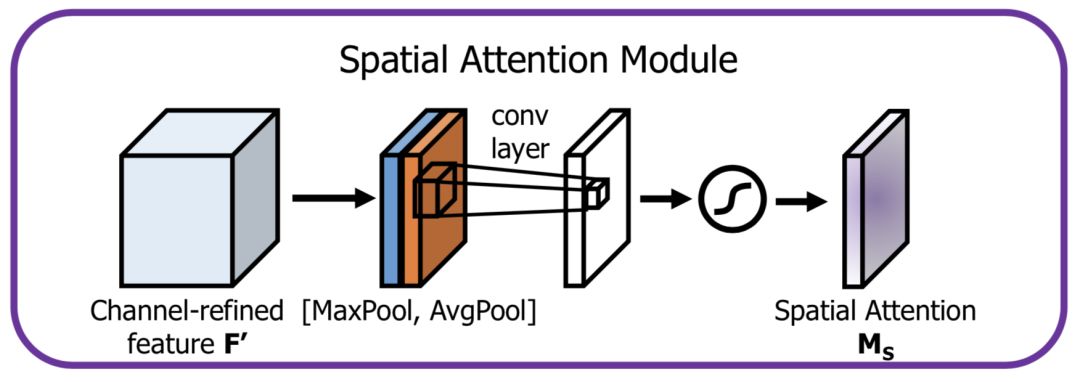
First, the channels themselves are reduced in dimensions, obtaining both max pooling and average pooling results, which are then concatenated into a feature map, followed by a convolution layer for learning.
These two mechanisms learn the importance of channels and spatial locations, and can easily be embedded into any known framework.
In addition, there are many other studies related to Attention mechanisms, such as residual attention mechanisms, multi-scale attention mechanisms, recursive attention mechanisms, etc.
From a theoretical standpoint, the Attention mechanism can enhance model performance across all computer vision tasks, but two types of scenarios benefit particularly strongly.
3.1 Fine-Grained Classification
For foundational content regarding fine-grained classification, you can refer to previous articles from the public account.
[Image Classification] What is fine-grained image classification, what methods exist, and how has it developed?
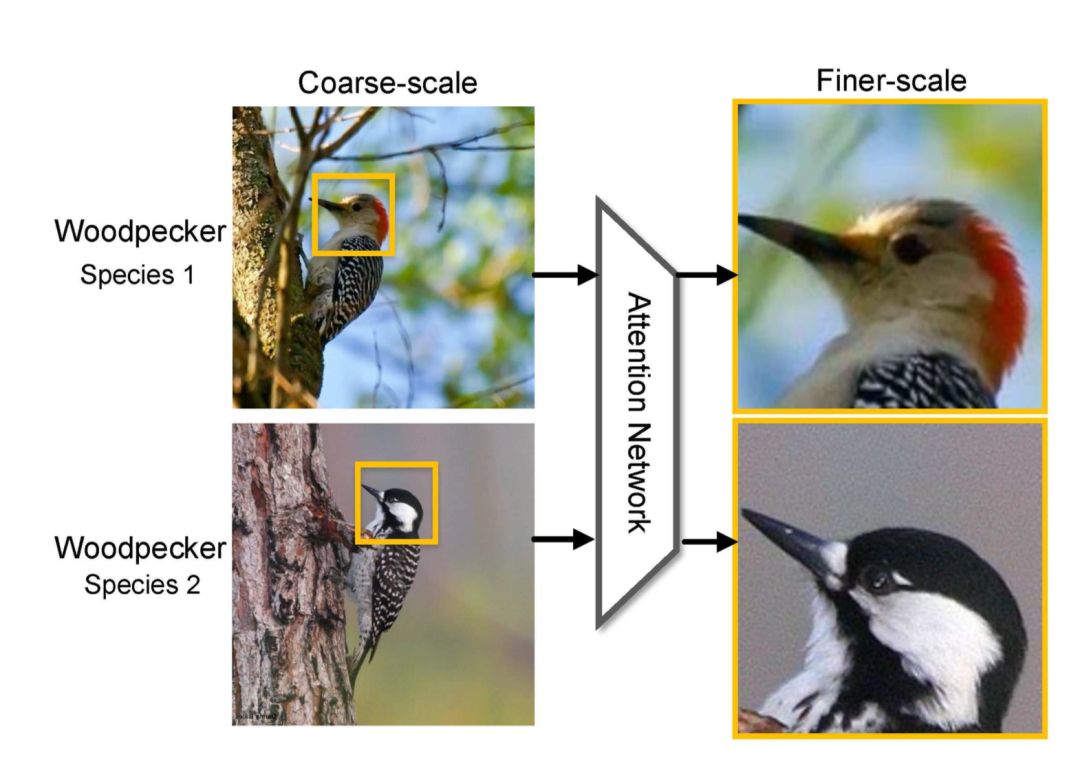
We know that the real challenge in fine-grained classification tasks lies in locating the truly useful local areas, such as the head of the bird in the diagram above. The Attention mechanism happens to be very suitable in principle, as evidenced by articles [1],[6] that utilize the Attention mechanism, showing significant improvements in model performance.
3.2 Salient Object Detection/Thumbnail Generation/Automatic Composition
Returning to the beginning, yes, the essence of Attention is the localization of important/salient areas, making it very useful in the field of object detection.


The images above show several results of salient object detection. It can be seen that for images with salient objects, the probability maps are very focused on the main targets. Adding Attention mechanism modules in the network can further enhance the model’s performance in such tasks.
References
[1] Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Advances in neural information processing systems. 2015: 2017-2025.
[2] Almahairi A, Ballas N, Cooijmans T, et al. Dynamic capacity networks[C]//International Conference on Machine Learning. 2016: 2549-2558.
[3] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[4] Li X, Wang W, Hu X, et al. Selective Kernel Networks[J]. 2019.
[5] Woo S, Park J, Lee J Y, et al. CBAM: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 3-19.
[6] Fu J, Zheng H, Mei T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4438-4446.
Discussion Group
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will gradually be subdivided). Please scan the WeChat ID below to join the group, and note: “nickname + school/company + research direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format for notes, otherwise, you will not be approved. Once added successfully, you will be invited to related WeChat groups based on your research direction. Please do not send advertisements in the group, or you will be removed, thank you for your understanding~

