This article is reprinted from: Deep Learning EnthusiastsLink:https://www.zhihu.com/question/448924025/answer/1801015343Editor: Deep Learning and Computer VisionStatement: For academic sharing only, please delete if infringing
 Is CNN a Type of Local Self-Attention?
Is CNN a Type of Local Self-Attention? Author: Hohuohttps://www.zhihu.com/question/448924025/answer/1791134786(This answer refers to: Li Hongyi’s 2021 Machine Learning Course)CNN is not a type of local attention, so let’s clarify what CNN and attention are doing.
Author: Hohuohttps://www.zhihu.com/question/448924025/answer/1791134786(This answer refers to: Li Hongyi’s 2021 Machine Learning Course)CNN is not a type of local attention, so let’s clarify what CNN and attention are doing.
1: CNN can be understood as a fully connected layer with weight sharing and local ordering. Therefore, CNN has two fundamentally different characteristics from fully connected layers: weight sharing and local connections. This greatly reduces the number of parameters while ensuring that some fundamental features are not lost.
2: The steps of attention involve obtaining the attention matrix through the dot product of Q and K, representing the similarity between the two. That is, the parts where Q and K are more similar will have a larger dot product, then scaled and softmaxed to obtain the attention score, which is then multiplied by V to get the result after attention.
The essence of attention is to measure the similarity between Q and K, emphasizing the parts of Q that are similar to K.
The essential difference can also be understood as CNN extracts features, while attention emphasizes features; the two can be quite different. If we say that all models are doing something around features, it would obviously be unreasonable to say they are the same.
Update: Due to a new understanding of CNN, I am updating my previous answer, but I will not delete my earlier response. I will add further supplements and explanations regarding this aspect later, and everyone is welcome to bookmark it.
For the differences between RNN and self-attention, you can refer to my answer, which I hope will help you.https://zhuanlan.zhihu.com/p/360374591
First, to conclude, CNN can be seen as a simplified version of Self-attention, or Self-attention can be considered a generalization of CNN.

Previously, when comparing CNN and self-attention, we subconsciously thought of CNN for image processing and self-attention for NLP, which creates the illusion of a connection between the two methods. Therefore, the following discussion will focus on the differences and connections between CNN and self-attention in image processing, to better compare CNN and self-attention. The process of self-attention used for image processing:
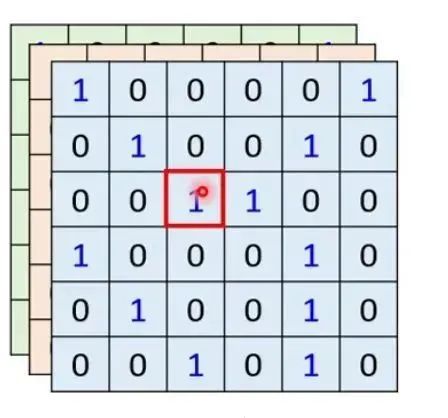 First, when processing images with self-attention, each pixel generates a Query, while other pixels generate Keys. The Query * Key is then computed, followed by softmax (as mentioned in comments, it does not necessarily have to be softmax, other activation functions like ReLU can also be used). Finally, multiply by the corresponding Value and sum it to get the output value for each pixel after softmax. Here, you will notice that when performing self-attention on an image, each pixel considers all pixels in the entire image, taking into account all information from the entire image.
First, when processing images with self-attention, each pixel generates a Query, while other pixels generate Keys. The Query * Key is then computed, followed by softmax (as mentioned in comments, it does not necessarily have to be softmax, other activation functions like ReLU can also be used). Finally, multiply by the corresponding Value and sum it to get the output value for each pixel after softmax. Here, you will notice that when performing self-attention on an image, each pixel considers all pixels in the entire image, taking into account all information from the entire image.
However, when we process images with CNN, we select different convolutional kernels to process the image. Each pixel only needs to consider the other pixels within that convolutional kernel; it only needs to consider the receptive field and does not need to consider all information in the entire image.
Thus, we can reach a general conclusion: CNN can be seen as a simplified version of self-attention, as CNN only needs to consider the information within the convolutional kernel (receptive field), while self-attention needs to consider global information.
Conversely, we can also understand that self-attention is a more complex version of CNN. CNN needs to define the receptive field and only consider information within that receptive field, the size and range of which must be set manually. In contrast, self-attention uses attention to find relevant pixels, as if the receptive field is learned automatically, determining which other pixels should be considered relevant to the central pixel.
In simple terms, CNN learns only the information within the convolutional kernel for each pixel, while Self-Attention learns information from the entire image for each pixel. (Here, we only consider a single layer of convolution; with multiple layers of convolution, CNN can actually achieve effects similar to self-attention.)
Now that we know the connection between self-attention and CNN, what conclusions can we draw?
We understand that CNN is a special case of Self-Attention, or Self-Attention is a generalization of CNN, a very flexible CNN. By putting certain constraints on Self-Attention, it can become similar to CNN. (This conclusion is derived from the paper: https://arxiv.org/abs/1911.03584)
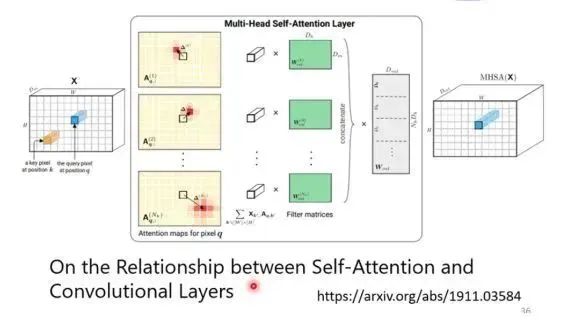 For self-attention, it is a very flexible model, so it requires more data for training. If the data is insufficient, it may lead to overfitting. However, CNN is more constrained and can train a relatively good model even with less training data.
For self-attention, it is a very flexible model, so it requires more data for training. If the data is insufficient, it may lead to overfitting. However, CNN is more constrained and can train a relatively good model even with less training data.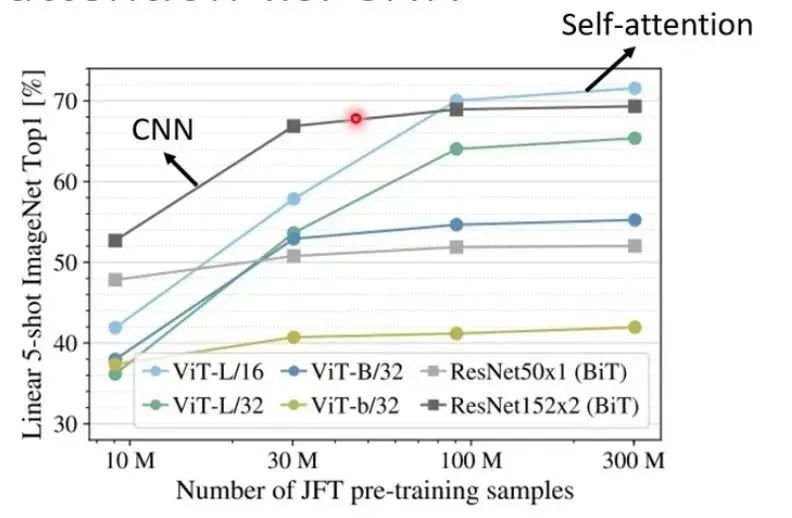 As shown in the figure, when the training data is relatively small, CNN performs better, while with a larger training data set, self-attention tends to perform better. That is, Self-Attention is more flexible and requires more training data, and when training data is small, it is prone to overfitting. CNN is less flexible, performing well with smaller training data, but cannot gain benefits from larger training data.
As shown in the figure, when the training data is relatively small, CNN performs better, while with a larger training data set, self-attention tends to perform better. That is, Self-Attention is more flexible and requires more training data, and when training data is small, it is prone to overfitting. CNN is less flexible, performing well with smaller training data, but cannot gain benefits from larger training data.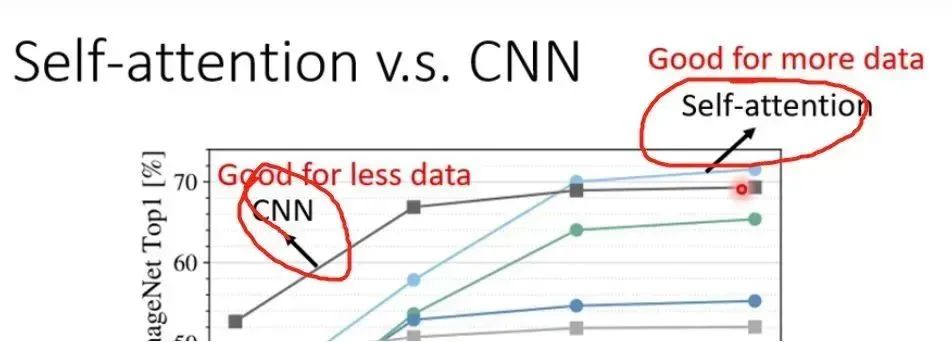 Author: Anonymous Userhttps://www.zhihu.com/question/448924025/answer/1784363556There are similarities, but also differences. CNN can be thought of as performing an inner product with a fixed static template at each position, which is a local projection, while attention computes the inner product between different positions, which can be seen as a distance metric. The weighted matrix defines a kind of distance metric. More generally, CNN is more local, while self-attention emphasizes relationships. It may be more appropriate to say that CNN is a special degenerate form of attention.Author: Lin Jianhuahttps://www.zhihu.com/question/448924025/answer/1793085963I believe that the convolutional layer of CNN and self-attention are not the same thing. Self-attention’s K and Q are generated by the data, reflecting the internal relationships of the data.
Author: Anonymous Userhttps://www.zhihu.com/question/448924025/answer/1784363556There are similarities, but also differences. CNN can be thought of as performing an inner product with a fixed static template at each position, which is a local projection, while attention computes the inner product between different positions, which can be seen as a distance metric. The weighted matrix defines a kind of distance metric. More generally, CNN is more local, while self-attention emphasizes relationships. It may be more appropriate to say that CNN is a special degenerate form of attention.Author: Lin Jianhuahttps://www.zhihu.com/question/448924025/answer/1793085963I believe that the convolutional layer of CNN and self-attention are not the same thing. Self-attention’s K and Q are generated by the data, reflecting the internal relationships of the data.
The convolutional layer of CNN can be seen as K composed of parameters and Q generated by different data, reflecting the relationship between data and parameters.
In other words, self-attention constructs a different space through parameters, allowing data to exhibit different self-correlated properties in different spaces.
Meanwhile, CNN convolutions construct certain fixed features through parameters, processing data based on their performance against these features.
Author: Alian https://www.zhihu.com/question/448924025/answer/1786277036The core of CNN lies in using local features to obtain global features. It can be said that each time it focuses on the local convolution kernel. Finally, the overall feature representation is formed through local convolutional features.
The self-attention mechanism is also important; it computes relationships within itself, allowing each word to incorporate global information, aiming to help local features represent themselves better with global information.
Thus, CNN is local to global, while the self-attention mechanism assists local with global information. If we must relate CNN to attention, I personally understand it as local attention (note that it does not include ‘self’).
Author: Aluea https://www.zhihu.com/question/448924025/answer/179309914Reversing the order, self-attention is a CNN with strong inductive bias. This is not difficult to understand; let’s look at what self-attention specifically does.
Assuming that for a layer of self-attention, there are four candidate features a, b, c, d that can be input simultaneously, and only the combinations ac and bd contribute to downstream tasks. Then self-attention will focus on these two combinations while masking the other features; for example, [a,b,c] -> [a’,0,c’] where a’ represents the output representation of a.
For a layer of CNN, it is quite straightforward: [a,b,c] -> [a’,b’,c’]. So can CNN perform the same functions as self-attention? Absolutely; by adding another layer of CNN with two filters, one filtering ac and the other filtering bd, it can be done.
Of course, CNN can also fit distributions without doing this, while self-attention must do so, which indicates a stronger inductive bias.
Regarding the importance of inductive bias, I will not elaborate further.Author: mof.iihttps://www.zhihu.com/question/448924025/answer/1797006034CNN is not a type of local self-attention, but it is possible to implement local self-attention as a layer to create a full self-attention network, as referenced in Google Brain’s Stand-Alone Self-Attention in Vision Models at NeurIPS19. The second section of the article compares the computational methods of convolutional layers and self-attention layers in detail, which is worth a look.
