Deep learning (DL) is a new research direction in the field of machine learning. By simulating the structure of the human brain’s neural network, it enables the analysis and processing of complex data, solving the difficulties traditional machine learning methods face when dealing with unstructured data. Its performance has significantly improved in areas such as image recognition, speech recognition, and natural language processing. Deep learning models include Convolutional Neural Networks (CNN), Deep Neural Networks (DNN), and Recurrent Neural Networks (RNN). In the early stages, CNN achieved remarkable success in the fields of image recognition and natural language processing. However, as task complexity increased, sequence-to-sequence models and RNNs became common methods for processing sequential data. RNNs and their variants often encounter gradient vanishing and model degradation issues when dealing with long sequences. To address these problems, the Transformer model was proposed. Subsequent large models such as GPT and BERT have demonstrated outstanding performance based on the Transformer architecture.
The transformer model based on the seq2seq architecture can accomplish typical tasks in NLP research, such as machine translation and text generation. It can also construct pre-trained language models for transfer learning across different tasks.
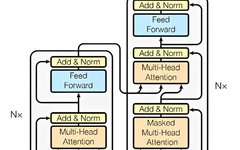
1) Source text embedding layer and its positional encoder
2) Target text embedding layer and its positional encoder
1) Linear layer: transforms the previous step’s output to the specified dimensional output, serving the purpose of dimension conversion;
2) Softmax processor: scales the numbers in the last dimension’s vector to a probability range of 0-1, ensuring their sum equals 1.
1) Composed of N stacked encoder layers;
2) Each encoder layer consists of two sub-layer connection structures;
3) The first sub-layer connection structure includes a multi-head self-attention sub-layer, a normalization layer, and a residual connection;
4) The second sub-layer connection structure includes a feedforward fully connected sub-layer, a normalization layer, and a residual connection.
1) Composed of N stacked decoder layers; each decoder layer consists of three sub-layer connection structures;
2) The first sub-layer connection structure includes a multi-head self-attention sub-layer, a normalization layer, and a residual connection;
3) The second sub-layer connection structure includes a multi-head attention sub-layer, a normalization layer, and a residual connection;
4) The third sub-layer connection structure includes a feedforward fully connected sub-layer, a normalization layer, and a residual connection.
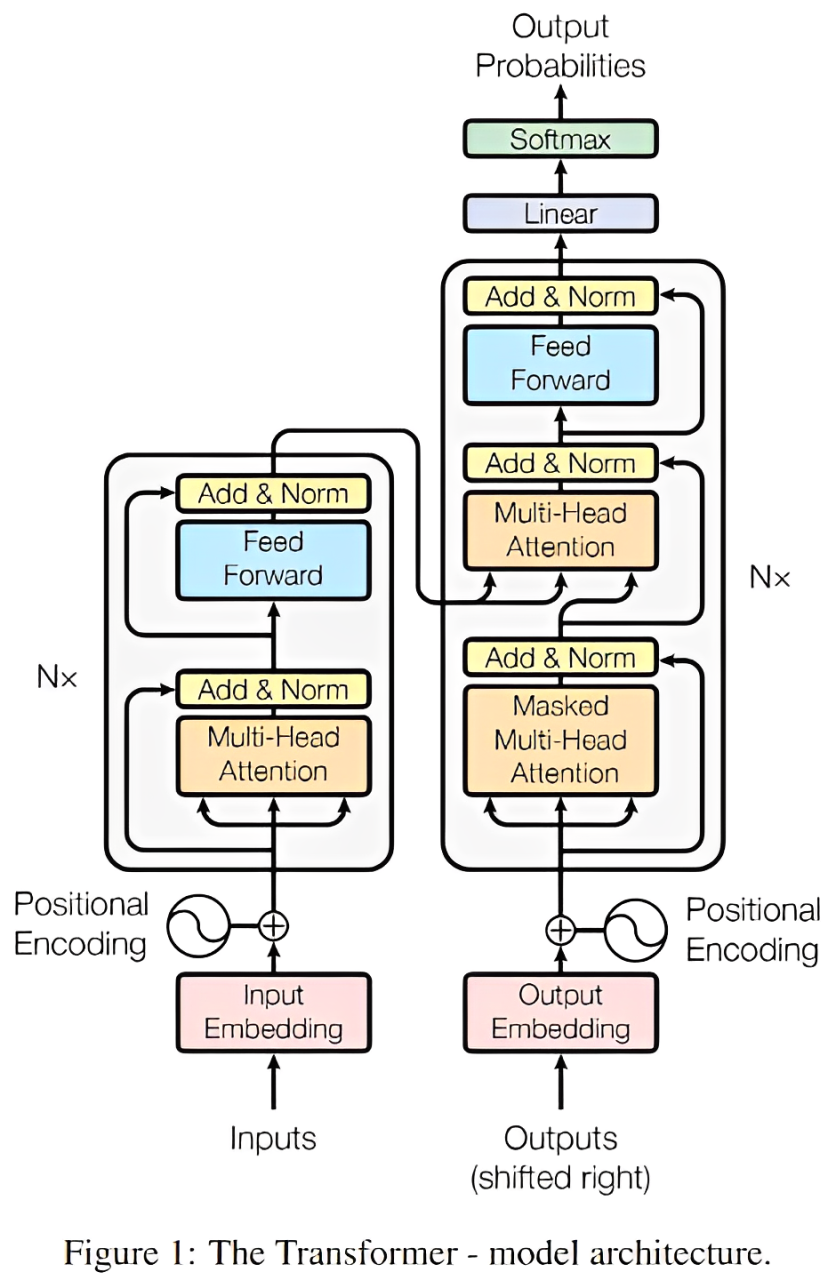
2.2 Transformer Attention Mechanism
When the embedding vectors are passed as input to the Transformer’s Attention module, the Attention module calculates the attention weights through Q, K, and V, allowing these vectors to analyze each other, enabling the embedding vectors to “communicate” and update their values based on each other’s information.
The main function of the Attention module is to determine which embedding vectors are most relevant to the current task in the given context and to update or adjust the representations of these embedding vectors accordingly.
Attention mechanism calculation formula: In the attention mechanism, Q (Query), K (Key), and V (Value) obtain corresponding vectors through mapping matrices. By calculating the dot product similarity between Q and K and normalizing it through softmax, weights are derived, which are then used to compute the weighted sum of V to obtain the output.
In specific applications, Yang Yun and others selected patients from the Shanghai Traditional Chinese Medicine Hospital’s Oncology Clinical Medical Center and the TCM Oncology Department of Shanghai University of Traditional Chinese Medicine, who were treated from October 19, 2005, to April 28, 2021. They used the Transformer model to construct and evaluate an artificial intelligence lung cancer prescription prediction system. The construction process includes: (1) Data collection, organizing patient general information and treatment records into Excel 2010 software, including gender, age, chief complaint, medical history, Western medical diagnosis (TNM staging, late-stage metastasis locations, pathological diagnosis types), past treatment history (surgery and radiotherapy/chemotherapy), symptoms, syndrome types, tongue and pulse signs, treatment methods, and Chinese medicine usage. (2) Data processing, using the Pandas library in Python (https://www.python.org) for data processing, extracting “symptoms,” and constructing a data cleaning and standardization platform based on the mapping relationship from raw symptoms to standard symptoms, replacing words that essentially refer to the same symptom or medicine with standard symptoms or standard medicines. (3) Model computation, replacing the input with symptoms and the output with medicines and syndrome types. The model computation and operation process are shown in Figure 1. First, symptoms and medicines are embedded into 512-dimensional vectors; then, the input is fed into the transformer model for training; finally, during training, the input and output can interact, but the output of medicines is predicted one by one. (4) Evaluation standards, using general evaluation standards for multi-label classification, the predicted medicine set {Pred}, the correct medicine set {True}, and the intersection of predictions and controls {Ins}={Pred}∩{True} are used to assess the accuracy of the proportion of correctly predicted medicines in the predicted prescriptions (Precision), with the formula Precision={Ins}/{Pred}; the recall rate (Recall) of correctly predicted medicines in the actual sample prescriptions is given by Recall={Ins}/{True}; the F1 value integrates precision and recall to reflect the overall performance, calculated as F1=2*Precision*Recall/(Precision+Recall). Additionally, three senior traditional Chinese medicine oncology experts were invited to score the predicted prescriptions generated by the system (0-10 points).
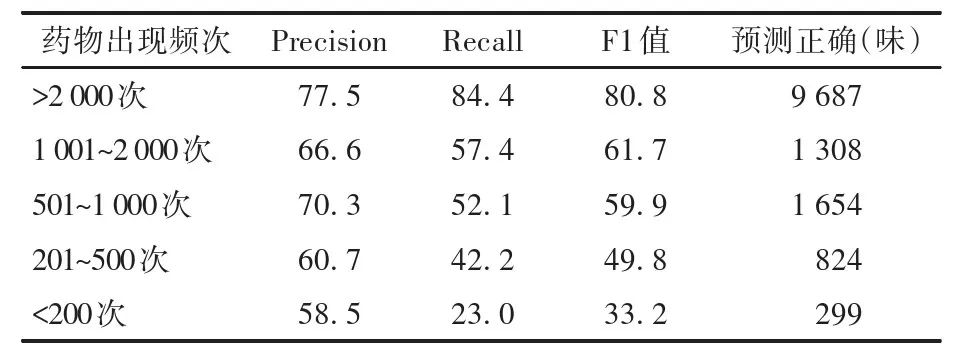
The specific results show: (1) Using a cross-validation method with a training set: validation set: test set ratio of 7:2:1, the average results were P:69.3%, R:66.9%, F1:68.0%. A sample of 800 patients was tested, showing overall results similar to the average situation (see Table 1). (2) Overall syndrome differentiation accuracy, the prescription prediction system matched the predicted syndrome types based on symptoms with the actual syndrome types of patients. (3) The three experts gave scores of 8.5, 8.6, and 8.7, with an average of 8.6.
Table 1 Test Results Classified by Frequency of Medicine Appearance (%)
4. Summary

Ancient and Modern Medical Case Cloud Platform
Providing Search Services for Over 500,000 Ancient and Modern Medical Cases
Supports Manual, Voice, OCR, and Batch Structured Input of Medical Cases
Designed with Nine Analysis Modules, Close to Clinical Practical Needs
Supports Collaborative Analysis of Massive Medical Cases and Personal Cases on the Platform
EDC Traditional Chinese Medicine Research Case Collection System
Supports Multi-Center, Online Random Grouping, Data Entry
SDV, Audit Trails, SMS Reminders, Data Statistics
Analysis and Other Functions
Supports Customized Form Design
Users can log in at: https://www.yiankb.com/edc
Free Trial!
Institute of Information Research, China Academy of Chinese Medical Sciences
Intelligent R&D Center for Traditional Chinese Medicine Health
Big Data R&D Department
Phone: 010-64089619
13522583261
QQ: 2778196938
https://www.yiankb.com