Hello everyone~
Today, let’s talk about the Transformer ~
First, I’ll describe it in very simple terms to ensure that beginners can understand.
Transformer is a “super brain” that can process sequential data such as sentences, lyrics, and articles. It excels at these tasks because it can remember and understand how each word in a sentence is related. It’s like when you’re chatting with a friend; you need to remember everything your friend says and understand the meaning of each sentence within the context of the entire conversation.
1. Understanding Word Relationships
Suppose we have a sentence: “The cat is sitting on the blanket.” The Transformer needs to know the relationship between “cat” and “blanket”, such as the fact that the “cat” is “sitting on” the “blanket”, not the other way around. This process is like a super intelligent assistant constantly observing and understanding the relationships between words.
2. Scoring Words
To understand the relationships between words, the Transformer scores each word’s position. These scores indicate how important a word is in the sentence. For example, in the sentence “The cat is sitting on the blanket”, the importance of “cat” to “sitting” might be very high because it is the subject of the action. The Transformer uses this scoring method to determine which words have the greatest impact on the overall meaning of the sentence.
3. Multiple Assistants Working Together
The Transformer is not just one “assistant”; it has a group of “assistants”, each focusing on different aspects of the information. For example, one “assistant” might focus on the relationship between “cat” and “blanket”, while another might focus on the verb “sitting”. This group of “assistants” works together to better understand the overall meaning of the sentence.
4. Combining the Work of Each Assistant
Once each “assistant” has completed its task, the Transformer combines this information to form a complete understanding of the entire sentence. It’s like when you and a few friends discuss a movie plot; everyone shares their opinions, and together you reach a conclusion.
5. Processing More Sentences
The Transformer can process not just one sentence but many sentences, continually learning from them. This enables it to perform various tasks, such as translating sentences, generating new sentences, and even answering questions.
Finally, imagine you are a detective investigating a case. You have some clues (words): “cat”, “sitting”, “blanket”, “on”. Each clue seems ordinary, but you need to figure out how these clues are related.
-
You might want to know where the “cat” is. You find that the clue “blanket” seems to have some relation to the “cat”. -
You also notice that the clue “sitting” seems to indicate an action. -
Finally, you conclude: Oh, the “cat” is “sitting on” the “blanket”.
This is what the Transformer does. It understands the context based on the clues.
In summary, Transformer is a deep learning model used for processing sequential data, initially developed for natural language processing (NLP). In short, it is a tool that can “understand” language or sequential data and perform tasks such as translation, text generation, and question answering. Compared to traditional models (like RNN and LSTM), the Transformer is more efficient because it can process data in parallel and performs better at capturing long-distance dependencies.
Basic Principles
The core concept of Transformer is the Self-Attention Mechanism, which allows the model to “focus” on different parts of the input sequence while processing each input. This mechanism enables the model to understand the relationships between each word or symbol and others, rather than processing inputs linearly one by one.
The Transformer consists of two main parts:
-
Encoder: Converts the input sequence into a hidden representation (vector representation). -
Decoder: Generates the output sequence from the hidden representation.
Encoder and Decoder are both composed of multiple layers, with each layer including a self-attention mechanism and a Feed-Forward Neural Network (FFN).
Core Formulas
To better understand the internal working mechanisms of the Transformer, we need to delve into several key formulas:
3.1 Self-Attention Mechanism
For the input sequence, each element is first projected into three different vectors:
-
Query Vector (Query) -
Key Vector (Key) -
Value Vector (Value)
The calculation formulas for these vectors are as follows:
Where is the learnable weight matrix.
The core formula of Self-Attention calculates the similarity between each query vector and all key vectors:
Here, is a scaling factor used to avoid excessively large similarity values. The function transforms the similarity into weights, which are then multiplied by to obtain the weighted value vectors.
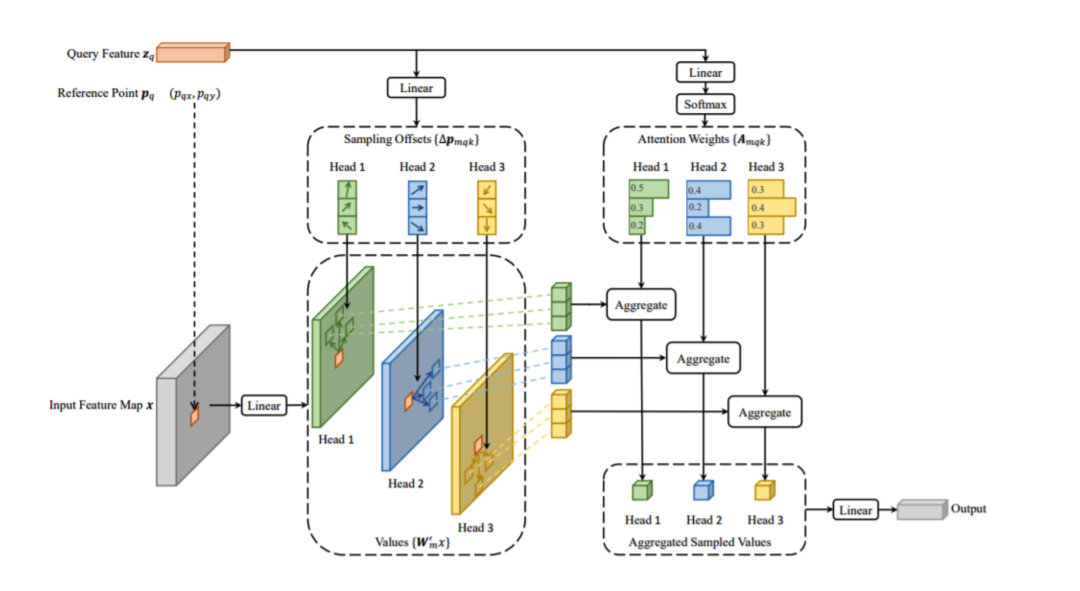
3.2 Multi-Head Attention Mechanism
To allow the model to capture features from different subspaces, the Multi-Head Attention Mechanism applies the above attention mechanism across multiple heads:
Where each is an independent self-attention mechanism:
3.3 Feed-Forward Network
Each encoder and decoder layer also includes a feed-forward neural network:
This is a two-layer fully connected network, where is the ReLU activation function.
Example Code
Using PyTorch to implement a small Transformer model and train it on a simple dataset.
import torch
import torch.nn as nn
import torch.optim as optim
# Define self-attention mechanism
class SelfAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(SelfAttention, self).__init__()
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.query = nn.Linear(d_model, d_model)
self.key = nn.Linear(d_model, d_model)
self.value = nn.Linear(d_model, d_model)
self.fc_out = nn.Linear(d_model, d_model)
def forward(self, x):
N, seq_length, d_model = x.shape
Q = self.query(x)
K = self.key(x)
V = self.value(x)
Q = Q.reshape(N, seq_length, self.num_heads, self.d_k)
K = K.reshape(N, seq_length, self.num_heads, self.d_k)
V = V.reshape(N, seq_length, self.num_heads, self.d_k)
energy = torch.einsum("nqhd,nkhd->nhqk", [Q, K])
attention = torch.softmax(energy / (self.d_k ** 0.5), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, V])
out = out.reshape(N, seq_length, d_model)
return self.fc_out(out)
# Define Transformer encoder layer
class TransformerBlock(nn.Module):
def __init__(self, d_model, num_heads, dropout):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.ff = nn.Sequential(
nn.Linear(d_model, d_model * 4),
nn.ReLU(),
nn.Linear(d_model * 4, d_model)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
attn_output = self.attention(x)
x = self.norm1(attn_output + x)
ff_output = self.ff(x)
x = self.norm2(ff_output + x)
return self.dropout(x)
# Define Transformer encoder
class TransformerEncoder(nn.Module):
def __init__(self, input_dim, d_model, num_layers, num_heads, dropout):
super(TransformerEncoder, self).__init__()
self.layers = nn.ModuleList([
TransformerBlock(d_model, num_heads, dropout)
for _ in range(num_layers)])
self.embed = nn.Linear(input_dim, d_model)
def forward(self, x):
x = self.embed(x)
for layer in self.layers:
x = layer(x)
return x
# Example dataset
data = torch.rand(10, 5, 8) # (batch_size, seq_length, input_dim)
# Model instance
model = TransformerEncoder(input_dim=8, d_model=32, num_layers=2, num_heads=4, dropout=0.1)
# Forward pass
output = model(data)
print(output.shape)
In the above code:
-
SelfAttention defines the self-attention mechanism. -
TransformerBlock includes the self-attention mechanism and feed-forward neural network. -
TransformerEncoder is a stack of multiple Transformer layers used to process input data.
Next, I will show you how to generate diagrams for the following parts of the Transformer:
-
Self-Attention Mechanism -
Multi-Head Attention -
Transformer Encoder Layer -
Transformer Encoder
We will demonstrate how to calculate Query, Key, Value, and the self-attention weights.
Self-Attention Mechanism
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Sample data
d_model = 8
seq_length = 5
num_heads = 2
# Simulate Query, Key, Value
np.random.seed(42)
Q = np.random.rand(seq_length, d_model)
K = np.random.rand(seq_length, d_model)
V = np.random.rand(seq_length, d_model)
# Calculate energy values
energy = np.dot(Q, K.T)
# Calculate attention weights
attention_weights = np.exp(energy) / np.sum(np.exp(energy), axis=1, keepdims=True)
# Plot attention weight map
plt.figure(figsize=(10, 8))
sns.heatmap(attention_weights, annot=True, cmap="viridis", xticklabels=range(seq_length), yticklabels=range(seq_length))
plt.title("Self-Attention Weights")
plt.xlabel("Key Positions")
plt.ylabel("Query Positions")
plt.show()
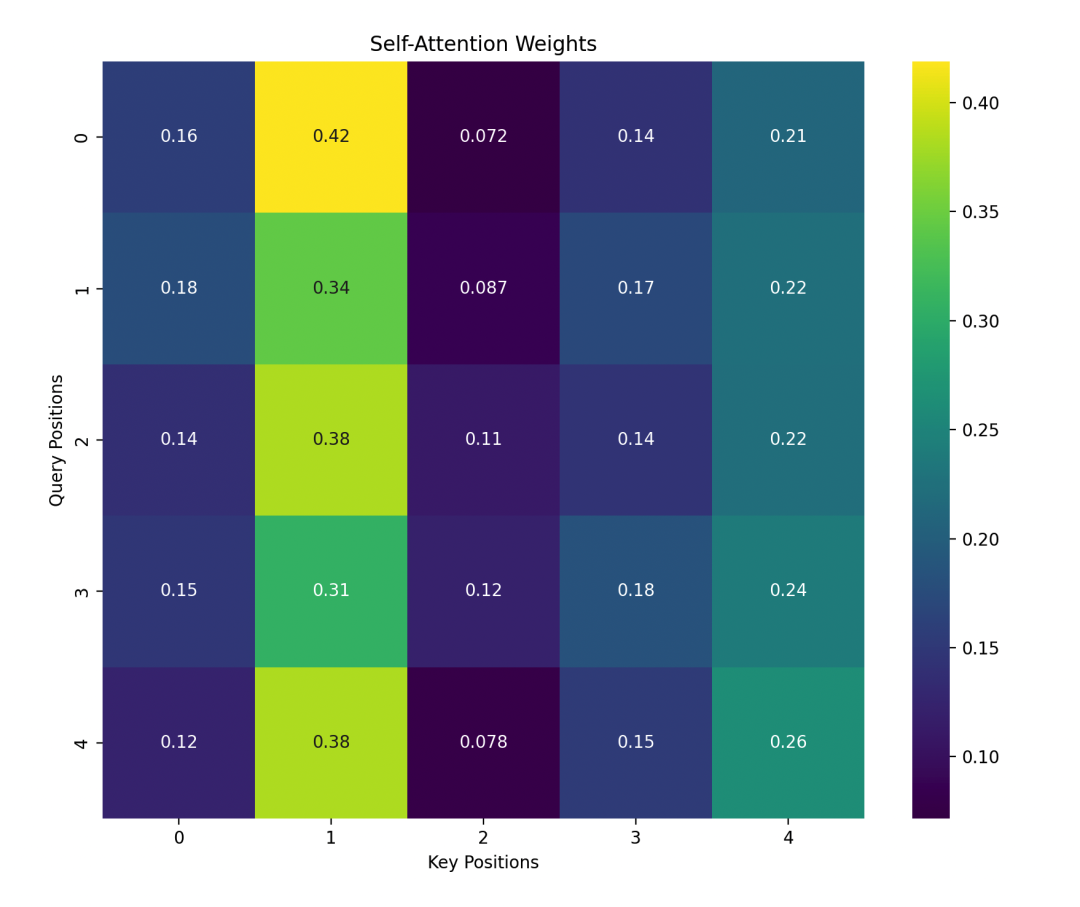
This heatmap shows the similarity between Query and Key and the attention weights transformed through softmax.
Multi-Head Attention Mechanism Diagram
# Sample multi-head data
num_heads = 4
d_k = d_model // num_heads
# Simulate multi-head Query, Key, Value
Q_heads = np.random.rand(seq_length, num_heads, d_k)
K_heads = np.random.rand(seq_length, num_heads, d_k)
V_heads = np.random.rand(seq_length, num_heads, d_k)
attention_heads = []
for i in range(num_heads):
energy_head = np.dot(Q_heads[:, i, :], K_heads[:, i, :].T)
attention_head = np.exp(energy_head) / np.sum(np.exp(energy_head), axis=1, keepdims=True)
attention_heads.append(attention_head)
# Plot attention weights for each head
fig, axes = plt.subplots(1, num_heads, figsize=(20, 5))
for i, attention_head in enumerate(attention_heads):
sns.heatmap(attention_head, annot=True, cmap="viridis", ax=axes[i], xticklabels=range(seq_length), yticklabels=range(seq_length))
axes[i].set_title(f"Head {i + 1}")
plt.suptitle("Multi-Head Attention Weights")
plt.show()
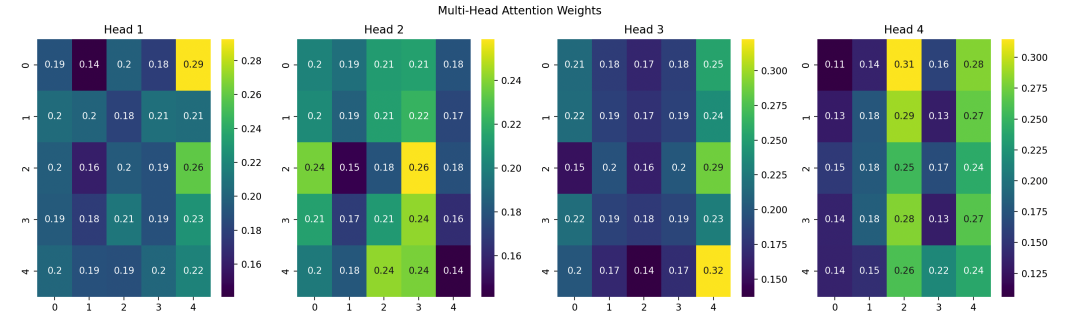
Each subplot shows the attention weights of different heads, illustrating how the model computes attention across different subspaces.
Transformer Encoder Layer
Demonstrates the data processing through self-attention mechanism and feed-forward neural network.
# Simulated data
x = np.random.rand(seq_length, d_model)
# Simulated self-attention output
attn_output = np.random.rand(seq_length, d_model)
# Simulated feed-forward network output
ff_output = np.random.rand(seq_length, d_model)
# Plot Transformer Block processing
plt.figure(figsize=(12, 6))
plt.subplot(1, 3, 1)
sns.heatmap(x, annot=True, cmap="Blues")
plt.title("Input Sequence")
plt.subplot(1, 3, 2)
sns.heatmap(attn_output, annot=True, cmap="Greens")
plt.title("Self-Attention Output")
plt.subplot(1, 3, 3)
sns.heatmap(ff_output, annot=True, cmap="Reds")
plt.title("Feed-Forward Output")
plt.suptitle("Transformer Block Processing")
plt.show()
On the left is the input sequence, in the middle is the output after processing through the self-attention mechanism, and on the right is the output after processing through the feed-forward neural network.
Transformer Encoder Diagram
Illustrates the entire encoder process, including the embedding layer and multiple encoder layers.
# Simulated input data
x = np.random.rand(seq_length, d_model)
num_layers = 3
# Simulated outputs from each layer
layer_outputs = [np.random.rand(seq_length, d_model) for _ in range(num_layers)]
# Plot the entire Transformer Encoder process
fig, axes = plt.subplots(1, num_layers + 1, figsize=(18, 6))
sns.heatmap(x, annot=True, cmap="Blues", ax=axes[0])
axes[0].set_title("Input Sequence")
for i, layer_output in enumerate(layer_outputs):
sns.heatmap(layer_output, annot=True, cmap="Purples", ax=axes[i + 1])
axes[i + 1].set_title(f"Layer {i + 1} Output")
plt.suptitle("Transformer Encoder Layers")
plt.show()
The first subplot is the input sequence, and the subsequent subplots show the outputs after passing through each encoder layer.
Conclusion
The core of the Transformer model lies in its self-attention mechanism and multi-head attention mechanism, which allow the model to effectively understand and process complex relationships in sequential data. Although its formulas and implementation details may seem complex, the Transformer provides a powerful and flexible framework for handling various natural language processing tasks.