

Source: Machine Heart
This article is approximately 2774 words long and is recommended to be read in 13 minutes.
This article introduces a novel large kernel attention module proposed by researchers from Tsinghua University and Nankai University, and constructs a new neural network named VAN that outperforms SOTA visual transformers based on LKA.
 As a fundamental feature extractor, the vision backbone is a basic research topic in the field of computer vision. Thanks to its excellent feature extraction performance, CNN has become an indispensable research topic over the past decade. After AlexNet reignited deep learning a decade ago, the community has made several breakthroughs to achieve more powerful vision backbones and attention mechanisms by utilizing deeper networks, more efficient architectures, and stronger multi-scale capabilities. Due to translational invariance and shared sliding window strategies, CNN is effective for various vision tasks with arbitrary input sizes. More advanced vision backbone networks often bring significant performance improvements across various tasks, including image classification, object detection, semantic segmentation, and pose estimation.At the same time, selective attention is an important mechanism for handling complex search combinations in vision. The attention mechanism can be seen as an adaptive selection process based on input features. Since the introduction of the full attention network, self-attention models (i.e., Transformer) have rapidly become the dominant architecture in the NLP field. In recent years, Dosovitskiy et al. proposed ViT, which introduced the transformer backbone into computer vision and outperformed CNN in image classification tasks. Thanks to its powerful modeling capabilities, transformer-based vision backbones have quickly dominated the leaderboards across various tasks, including object detection and semantic segmentation.Although self-attention mechanisms were originally designed for NLP tasks, they have recently swept through the field of computer vision. However, the 2D characteristics of images pose three challenges for applying self-attention in computer vision:
As a fundamental feature extractor, the vision backbone is a basic research topic in the field of computer vision. Thanks to its excellent feature extraction performance, CNN has become an indispensable research topic over the past decade. After AlexNet reignited deep learning a decade ago, the community has made several breakthroughs to achieve more powerful vision backbones and attention mechanisms by utilizing deeper networks, more efficient architectures, and stronger multi-scale capabilities. Due to translational invariance and shared sliding window strategies, CNN is effective for various vision tasks with arbitrary input sizes. More advanced vision backbone networks often bring significant performance improvements across various tasks, including image classification, object detection, semantic segmentation, and pose estimation.At the same time, selective attention is an important mechanism for handling complex search combinations in vision. The attention mechanism can be seen as an adaptive selection process based on input features. Since the introduction of the full attention network, self-attention models (i.e., Transformer) have rapidly become the dominant architecture in the NLP field. In recent years, Dosovitskiy et al. proposed ViT, which introduced the transformer backbone into computer vision and outperformed CNN in image classification tasks. Thanks to its powerful modeling capabilities, transformer-based vision backbones have quickly dominated the leaderboards across various tasks, including object detection and semantic segmentation.Although self-attention mechanisms were originally designed for NLP tasks, they have recently swept through the field of computer vision. However, the 2D characteristics of images pose three challenges for applying self-attention in computer vision:
-
Treating images as one-dimensional sequences ignores their two-dimensional structure;
-
Quadratic complexity is too expensive for high-resolution images;
-
Only capturing spatial adaptability while ignoring channel adaptability.
Recently, the team of Hu Shimin from Tsinghua University and the team of Cheng Mingming from Nankai University proposed a novel large kernel attention (LKA) module, which achieves adaptivity and long-range correlation in self-attention while avoiding the aforementioned issues. This study also further proposed a new neural network based on LKA, named Visual Attention Network (VAN). In extensive experiments on image classification, object detection, semantic segmentation, instance segmentation, etc., the performance of VAN surpasses that of SOTA visual transformers and convolutional neural networks.

-
Paper link: https://arxiv.org/abs/2202.09741
-
Project link: https://github.com/Visual-Attention-Network
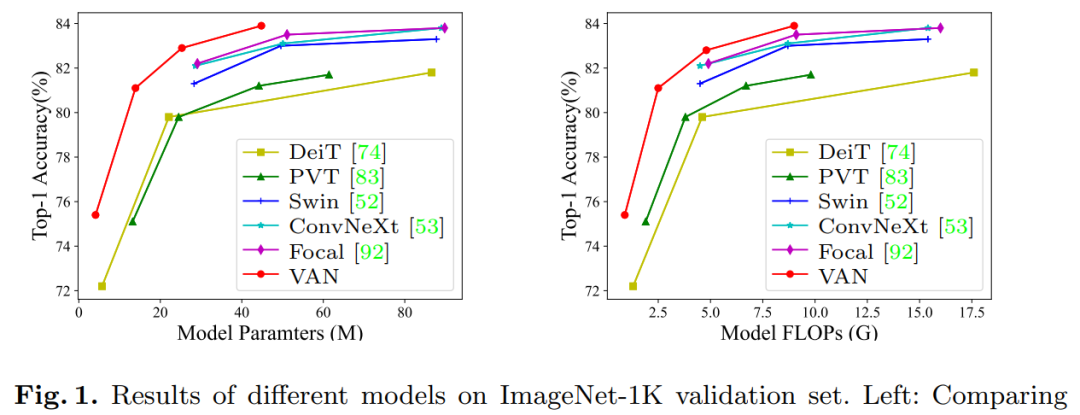
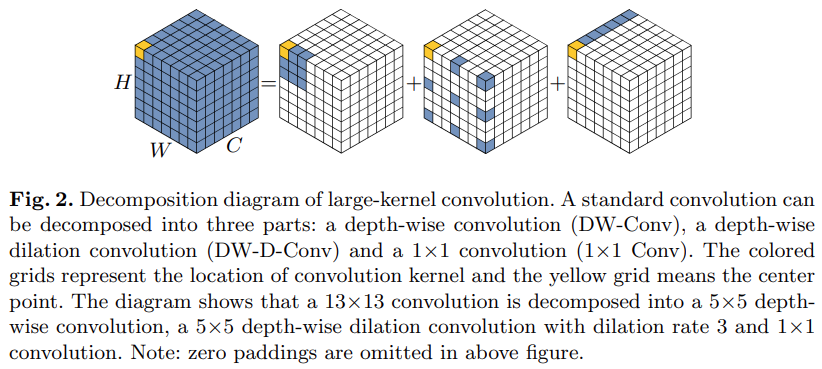
Figure 1: Comparison of Top-1 accuracy results of VAN and other models on the ImageNet-1K validation setOne of the authors, Guo Menghao, a PhD student in the Department of Computer Science at Tsinghua University, focuses on computer vision, computer graphics, and deep learning. He is also one of the developers of Jittor and has published papers at international conferences/journals such as ICLR/IPMI/CVMJ. Hu Shimin, a professor in the Department of Computer Science and Technology at Tsinghua University, mainly engages in research on computer graphics, intelligent information processing, and system software. He developed and open-sourced the first deep learning framework independently created by a Chinese university—Jittor, which is a fully dynamic compiled (Just-in-time), meta-operator fused, and unified computational graph deep learning framework. Jittor supports over 30 types of backbone networks and has open-sourced several model libraries: adversarial generative networks, image semantic segmentation, detection and instance segmentation, point cloud classification, differentiable rendering, etc.Cheng Mingming, a professor and head of the Computer Science Department at Nankai University, focuses on computer vision and computer graphics, with his papers cited over 20,000 times on Google Scholar, with a single paper cited over 4,000 times.MethodLarge Kernel AttentionThe attention mechanism can be viewed as an adaptive selection process that selects discriminative features based on input features and automatically ignores noise responses. The key step in the attention mechanism is generating an attention map that indicates the importance of different points. Therefore, it is necessary to understand the relationships between various points.Two well-known methods can establish relationships between different points. The first is to use self-attention mechanisms to capture long-range dependencies. The second is to use large kernel convolutions to establish correlations and produce attention maps; however, this approach has significant drawbacks, as large kernel convolutions incur a large amount of computational overhead and parameters.To overcome the aforementioned disadvantages and leverage the advantages of self-attention and large kernel convolutions, this study proposes to decompose the large kernel convolution operation to capture long-range relationships. As shown in Figure 2, large kernel convolutions can be divided into three parts: spatial local convolution (depth-wise convolution), spatial long-distance convolution (depth-wise dilated convolution), and channel convolution (1×1 convolution).
Hu Shimin, a professor in the Department of Computer Science and Technology at Tsinghua University, mainly engages in research on computer graphics, intelligent information processing, and system software. He developed and open-sourced the first deep learning framework independently created by a Chinese university—Jittor, which is a fully dynamic compiled (Just-in-time), meta-operator fused, and unified computational graph deep learning framework. Jittor supports over 30 types of backbone networks and has open-sourced several model libraries: adversarial generative networks, image semantic segmentation, detection and instance segmentation, point cloud classification, differentiable rendering, etc.Cheng Mingming, a professor and head of the Computer Science Department at Nankai University, focuses on computer vision and computer graphics, with his papers cited over 20,000 times on Google Scholar, with a single paper cited over 4,000 times.MethodLarge Kernel AttentionThe attention mechanism can be viewed as an adaptive selection process that selects discriminative features based on input features and automatically ignores noise responses. The key step in the attention mechanism is generating an attention map that indicates the importance of different points. Therefore, it is necessary to understand the relationships between various points.Two well-known methods can establish relationships between different points. The first is to use self-attention mechanisms to capture long-range dependencies. The second is to use large kernel convolutions to establish correlations and produce attention maps; however, this approach has significant drawbacks, as large kernel convolutions incur a large amount of computational overhead and parameters.To overcome the aforementioned disadvantages and leverage the advantages of self-attention and large kernel convolutions, this study proposes to decompose the large kernel convolution operation to capture long-range relationships. As shown in Figure 2, large kernel convolutions can be divided into three parts: spatial local convolution (depth-wise convolution), spatial long-distance convolution (depth-wise dilated convolution), and channel convolution (1×1 convolution).
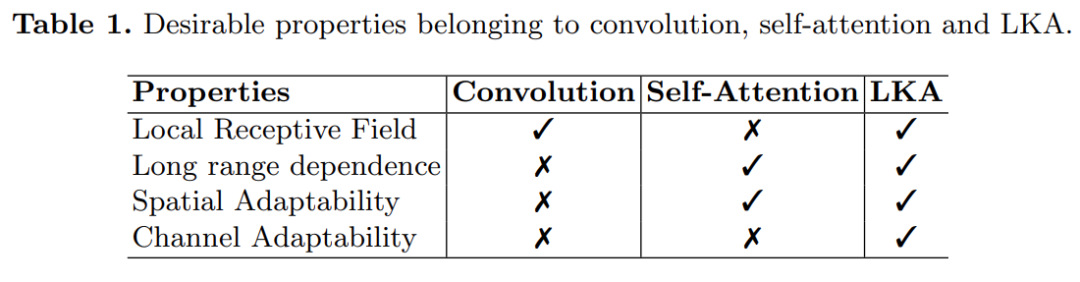
The following Table 1 shows the advantages of LKA combining convolution and self-attention.
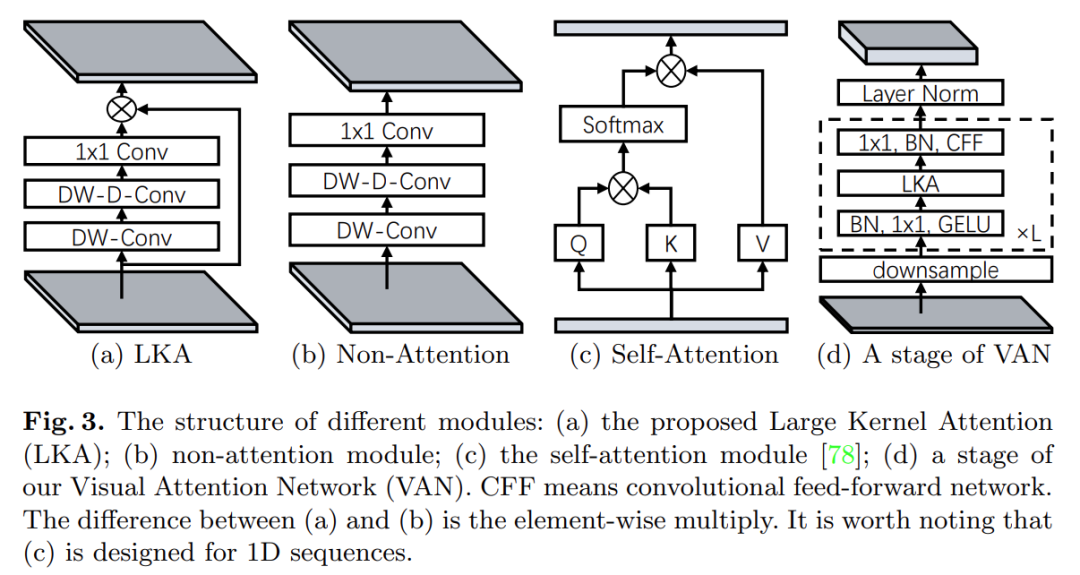
Visual Attention Network (VAN) VAN has a simple hierarchical structure consisting of four stages, gradually reducing the output spatial resolution to H/4 × W/4, H/8 × W/8, H/16 × W/16, and H /32 × W/32. Here, H and W represent the height and width of the input image. As the resolution decreases, the number of output channels also increases. The changes in output channel C_i are shown in Table 2.

As shown in Figure 3 (d), this study first downsamples the input and uses the stride number to control the downsampling rate.
ExperimentsThis study demonstrates the effectiveness of VAN through quantitative and qualitative experiments. Quantitative experiments were conducted on the ImageNet-1K image classification dataset, COCO object detection dataset, and ADE20K semantic segmentation dataset, and Grad-CAM was used to visualize class activation maps (CAM) on the ImageNet validation set.The study first used ablation experiments to demonstrate that each component of LKA is crucial. To quickly obtain experimental results, the study chose VAN-Tiny as the baseline model, with experimental results shown in Table 4.
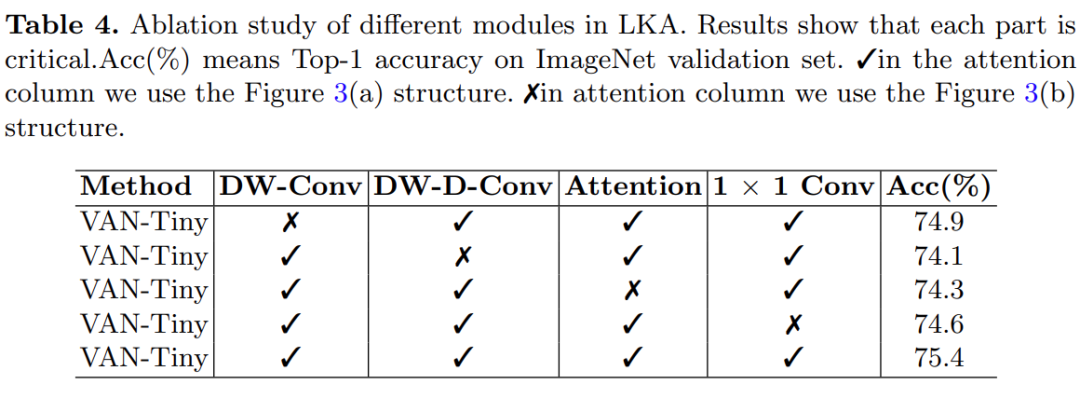
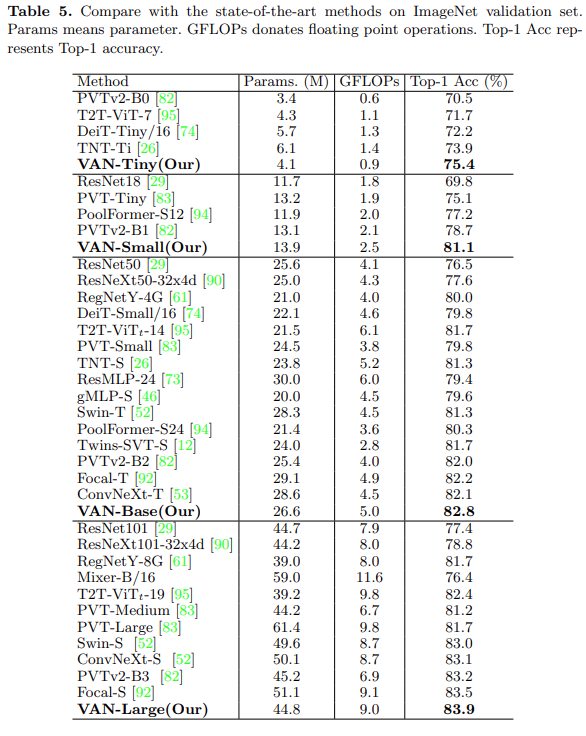
Through the above analysis, the researchers found that LKA can utilize local information and capture long-range dependencies, demonstrating adaptability in both channel and spatial dimensions. Furthermore, experimental results prove that all components of LKA contribute to completing recognition tasks. While standard convolutions can fully utilize local contextual information, they neglect long-range dependencies and adaptability. Self-attention, while capable of capturing long-range dependencies and having adaptability in the spatial dimension, neglects local information and adaptability in the channel dimension.The researchers also compared VAN with existing methods, including MLP, CNN, and ViT, with results shown in Table 5. Under similar parameters and computational costs, VAN outperformed common CNNs (ResNet, ResNeXt, ConvNeXt, etc.), ViTs (DeiT, PVT, and Swin-Transformer, etc.), and MLPs (MLP-Mixer, ResMLP, gMLP, etc.).
Visual class activation mapping (CAM) is a popular tool for visualizing discriminative regions (attention maps). This study employed Grad-CAM to visualize the attention generated by the VAN-Base model on the ImageNet validation set. The results in Figure 4 indicate that VAN-Base can clearly focus on the target object, visually demonstrating the effectiveness of VAN.

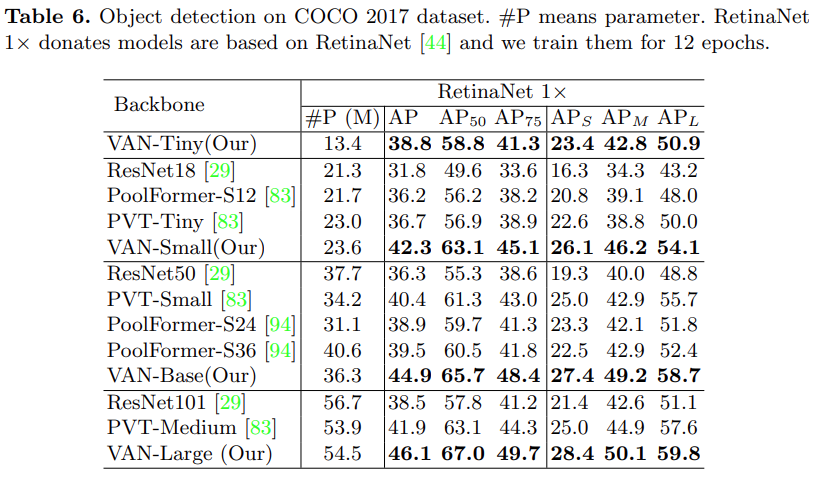
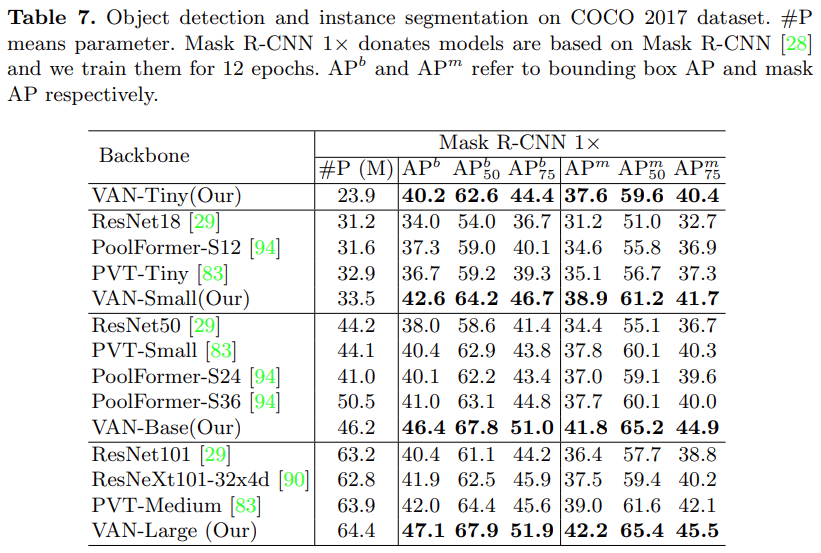
As shown in Tables 6 and 7, in object detection and instance segmentation tasks, this study found that VAN significantly surpasses CNN-based methods (ResNet) and transformer-based methods (PVT) under the RetinaNet 1x and Mask R-CNN 1x settings.
Additionally, as shown in Table 8, compared to SOTA methods such as Swin Transformer and ConvNeXt,VAN achieves superior performance..
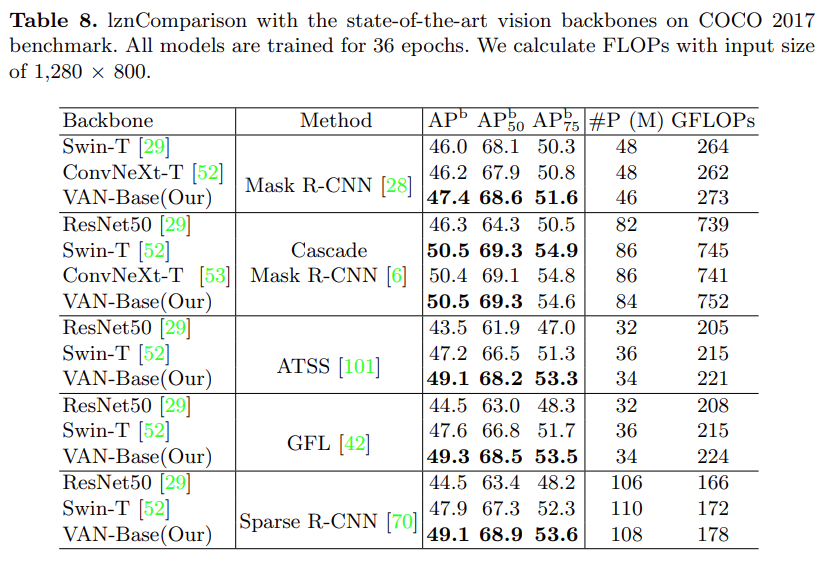
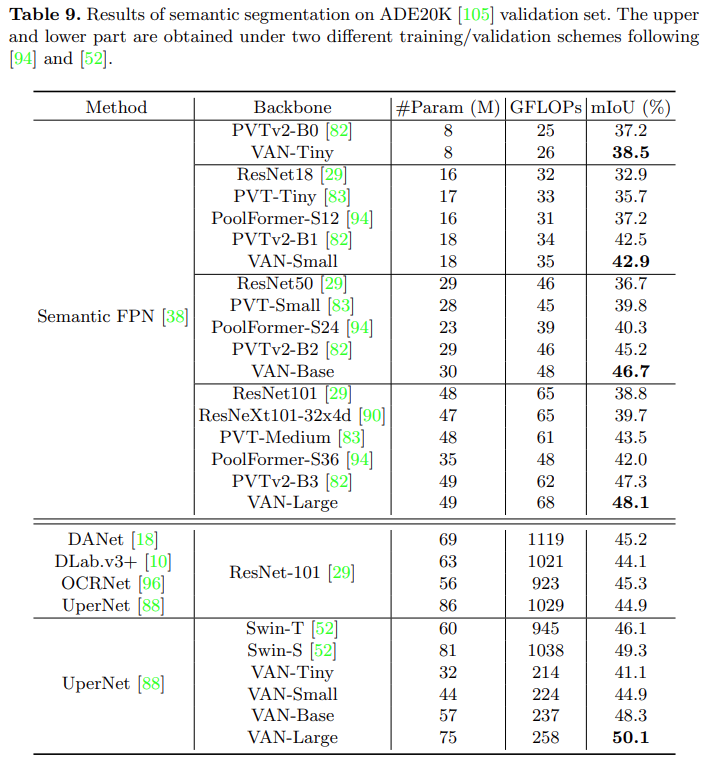
Table 9 presents the results for the semantic segmentation task, where methods based on VAN outperform CNN-based methods (ResNet, ResNeXt) and transformer-based methods (PVT, PoolFormer, PVTv2).
——END——