1 Algorithm Introduction
The Transformer is a model that uses the attention mechanism to improve the training speed of the model. The Transformer can be said to be a deep learning model that is completely based on the self-attention mechanism, as it is suitable for parallel computation, and its inherent model complexity results in higher accuracy and performance compared to the previously popular RNN (Recurrent Neural Network).
So what is a Transformer? You can simply understand it as a black box. When we perform text translation tasks, we input a Chinese text, and after passing through this black box, we get the translated English output.

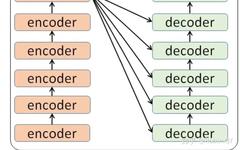
When a user inputs a text, the text data first goes through a module called Encoders, which encodes the text. Then, the encoded data is passed to a module called Decoders for decoding, resulting in the translated text. Correspondingly, we refer to Encoders as the encoder and Decoders as the decoder. The encoding module contains many small encoders; typically, there are 6 small encoders in the Encoders, and similarly, there are 6 small decoders in the Decoders.
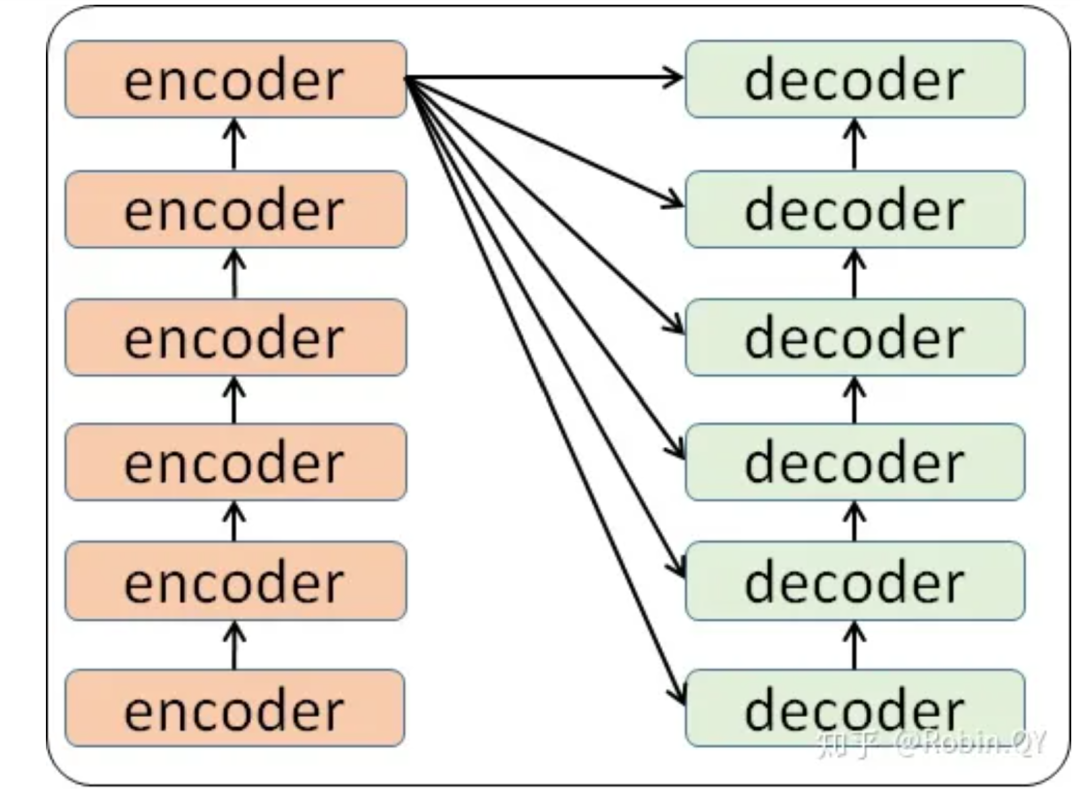
We see that in the encoding part, the input of each small encoder is the output of the previous small encoder, while the input of each small decoder includes not only the output of its previous decoder but also the output of the entire encoding part. The structure of each small encoder is a self-attention mechanism plus a feed-forward neural network.
2 Algorithm Principles
The core part of the Transformer consists of a stack of encoder layers and decoder layers. To avoid confusion, we will refer to an individual layer as an encoder or decoder and use encoder stack or decoder stack to represent a set of encoders and a set of decoders, respectively.
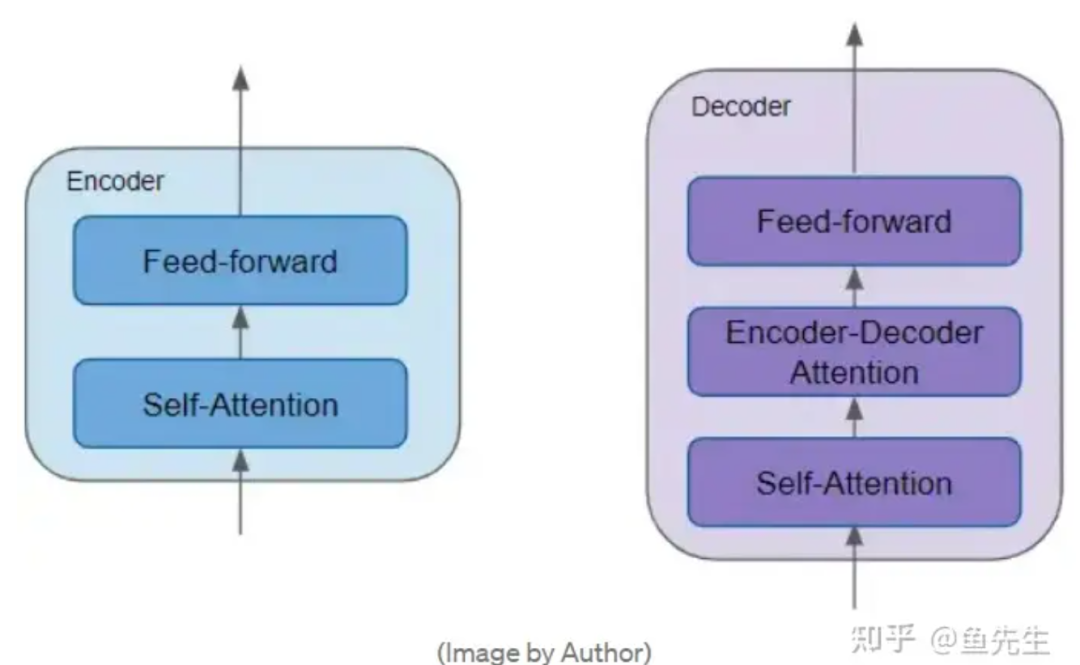
Before the encoder stack and decoder stack, there are corresponding embedding layers; after the decoder stack, there is an output layer to generate the final output. The structure of each encoder in the encoder stack is the same. The same goes for the decoders. Their respective structures are as follows:
-
Encoders generally have two sub-layers: including a self-attention layer for calculating the relationships between different words in the sequence; and a feed-forward layer.
-
Decoders generally have three sub-layers: including a self-attention layer, a feed-forward layer, and an encoder-decoder attention layer.
-
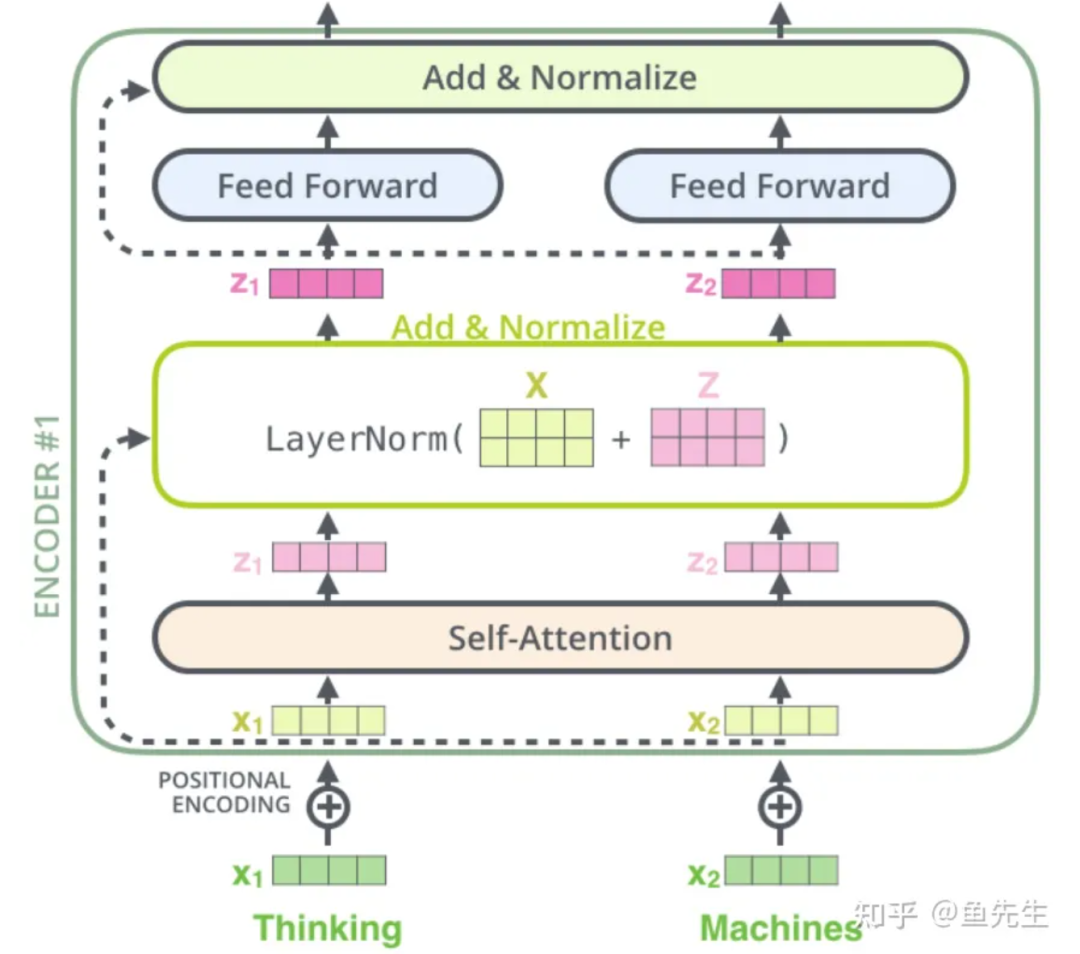
Each encoder and decoder has a unique set of weights for that layer. It is important to note that the self-attention layer and feed-forward layer of the encoder both have residual connections and normalization layers. There are many variants of the Transformer, some of which do not even have a decoder structure and rely solely on the encoder.
3 Algorithm Applications
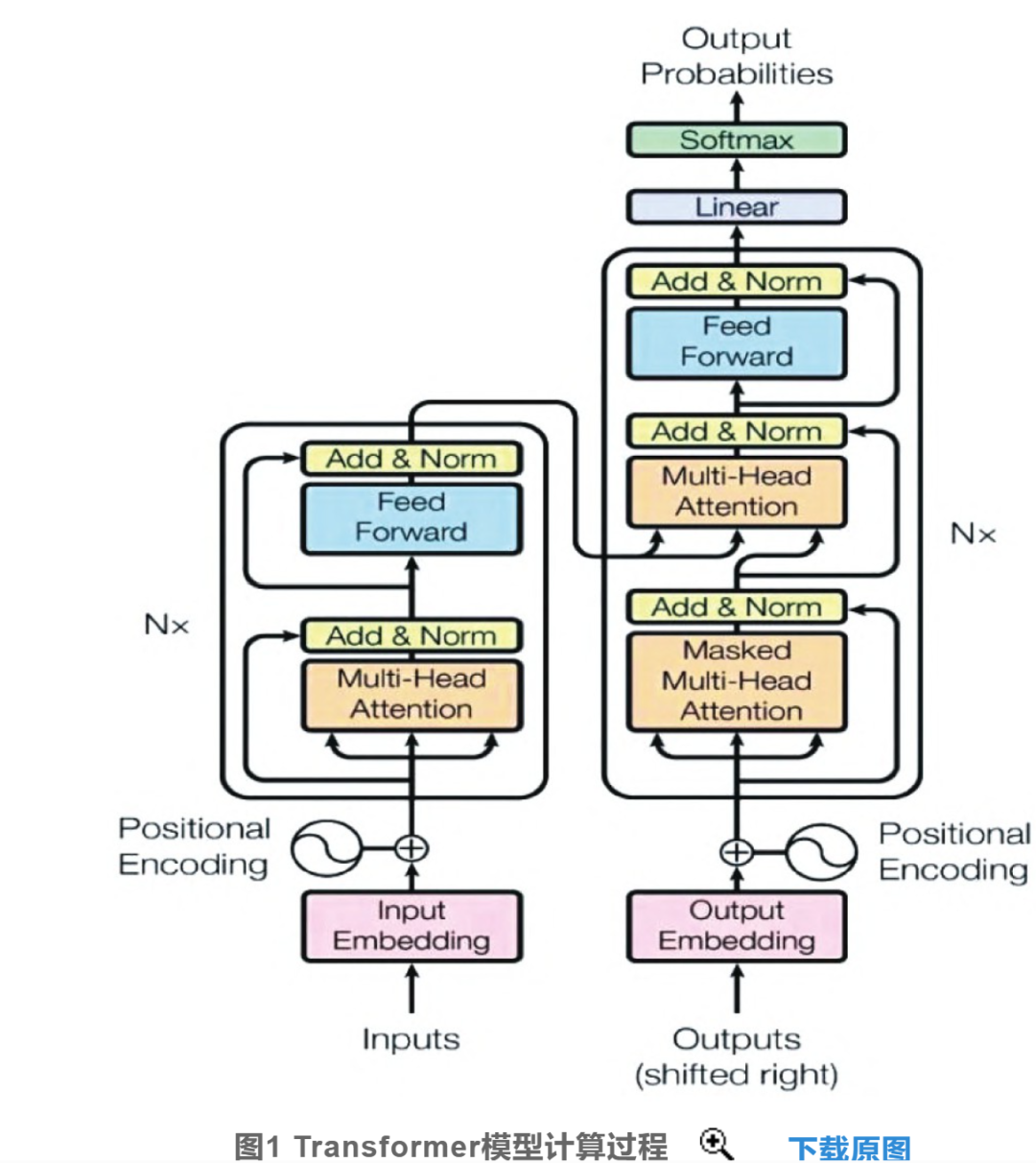
In the field of natural language processing in artificial intelligence, including machine translation, intelligent question answering, search engines, and a series of applications similar to traditional Chinese medicine prescription prediction, models based on the Transformer have become the current “gold standard” in the computer industry and are widely used in related fields. For example, in the research on the construction of an artificial intelligence lung cancer syndrome prediction system, the Google-based machine translation Transformer model was used, where the input was replaced with symptoms, and the output was replaced with drugs and syndromes. The model computation and operation process is shown in Figure 1. First, the symptoms and drugs are embedded, embedding all symptoms and drugs into 512-dimensional vectors; the 512-dimensional vectors are divided into 8 subspaces, and training is performed within each subspace before merging them all together.
The training set: validation set: test set ratio is set at 7:2:1 for cross-validation, with an average result of P:69.3%, R:66.9%, F1:68.0%. A total of 800 patients were sampled as the test set for validation, and the overall situation was similar to the average situation.
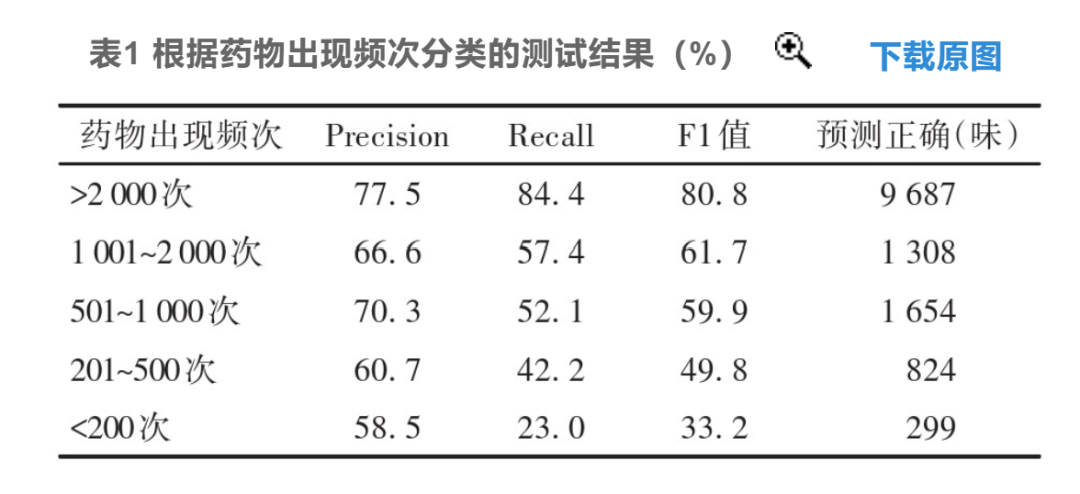
4 Conclusion
In the existing research combining traditional Chinese medicine and artificial intelligence, the main form is data mining of high-quality traditional Chinese medicine cases to build traditional Chinese medicine diagnosis and treatment decision support systems. The traditional Chinese medicine diagnosis and treatment decision support systems, such as the intelligent prescription system, require the machine to learn or deep learn based on a large number of medical cases, predicting prescriptions based on input symptoms while summarizing experiences based on the translation rules of symptoms corresponding to prescriptions and syndrome differentiation.
The Attention-based Transformer model not only outperforms previous deep learning models in performance but also excels in interpretability compared to deep learning models, making it more suitable for deep learning on the characteristics of traditional Chinese medicine data. The intelligent prescription system established by this method can collect, analyze, and inherit expert experience, further promoting its application in clinical practice and education, thereby facilitating the inheritance and development of traditional Chinese medicine.
References:
[1] “How to Understand Transformer in the Simplest and Most Popular Way? – Zhihu”. Accessed on April 11, 2024. https://www.zhihu.com/question/445556653.
[2] Zhihu Column. “Understanding Transformer in Ten Minutes”. Accessed on April 10, 2024. https://zhuanlan.zhihu.com/p/82312421.
[3] Yang Yun, Pei Chaohan, Cui Ji, et al. Construction of an Artificial Intelligence Lung Cancer Syndrome Prediction System Based on the Transformer Model [J]. Beijing Traditional Chinese Medicine, 2024, 43(02):208-211. DOI:10.16025/j.1674-1307.2024.02.023.
Recommended Reading:
The Era of Large Language Models: Efficiency and Accuracy Achieved, Opportunities and Challenges Coexist
New Paradigm of Large Language Models RAG, How Much Do You Know About This Cost-Reducing and Efficiency-Increasing Method?
Ontology – An Efficient Knowledge Modeling Tool

Ancient and Modern Medical Case Cloud Platform
Providing Retrieval Services for Over 500,000 Ancient and Modern Medical Cases
Supports Manual, Voice, OCR, and Batch Structured Entry of Medical Cases
Designed with Nine Analysis Modules, Close to Clinical Needs
Supports Collaborative Analysis of Massive Medical Cases and Personal Cases
EDC Traditional Chinese Medicine Research Case Collection System
Supports Multi-Center, Central Randomization, Data Entry,
SDV, Audit Trails, SMS Reminders, Data Statistics
Analysis, Patient Diary Cards, Mobile Entry, and Other Functions
Supports Custom Form Design
Users can log in at: https://www.yiankb.com/edc
Institute of Chinese Medical Sciences, Chinese Academy of Traditional Chinese Medicine
Smart R&D Center for Traditional Chinese Medicine Health
Big Data R&D Department
Phone: 010-64089619
13522583261
QQ: 2778196938
https://www.yiankb.com