
This article is excerpted from the latest publication by the People’s Posts and Telecommunications Press, the AI Bible “Deep Learning[1]“. The English version of “Deep Learning[2]” was published by the MIT Press in December 2016 and quickly became popular worldwide. A major feature of “Deep Learning[3]” is that it introduces the essence of deep learning algorithms, providing the logic behind the algorithms without delving into specific code implementations, making it accessible even to those who do not write code.
Co-authored by three leading and authoritative experts in the field of deep learning—Ian Goodfellow, Yoshua Bengio, and Aaron Courville—this “Bible” of artificial intelligence has long held the top spot on Amazon’s AI book list in the United States. The Chinese version of “Deep Learning[4]” has added fuel to the heated wave of artificial intelligence in China.
Introduction
As far back as ancient Greece, inventors dreamed of creating machines that could think independently. Mythical figures like Pygmalion, Daedalus, and Hephaestus can be seen as legendary inventors, while Galatea, Talos, and Pandora can be viewed as artificial life (Ovid and Martin, 2004; Sparkes, 1996; Tandy, 1997).
When humans first conceived of programmable computers, they were already pondering whether computers could become intelligent (even though it would be over a hundred years before the first computer was built) (Lovelace, 1842). Today, artificial intelligence (AI) has become a field with numerous practical applications and active research topics, and it is thriving. We expect intelligent software to automatically handle routine labor, understand speech or images, assist in medical diagnoses, and support fundamental scientific research.
In the early days of artificial intelligence, problems that were very difficult for human intelligence but relatively simple for computers were quickly solved, such as those that could be described by a series of formal mathematical rules. The real challenge for artificial intelligence lies in solving tasks that are easy for humans to perform but difficult to formalize, such as recognizing what people say or identifying faces in images. For these problems, we humans can often solve them intuitively with ease.
This book discusses a solution to these more intuitive problems. The solution allows computers to learn from experience and understand the world based on a hierarchical system of concepts, where each concept is defined by its relationship to certain relatively simple concepts. Allowing computers to acquire knowledge from experience avoids the need for humans to formally specify all the knowledge the computer requires. The hierarchical concepts enable computers to build simpler concepts to learn complex ones. If we were to draw a diagram representing how these concepts are built upon each other, we would obtain a “deep” diagram (with many layers). For this reason, we refer to this approach as AI Deep Learning.
Many early successes in AI occurred in relatively simple and formal environments and did not require computers to possess extensive knowledge about the world. For example, IBM’s Deep Blue chess system defeated world champion Garry Kasparov in 1997 (Hsu, 2002). Clearly, chess is a very simple domain, as it consists of only 64 squares and allows 32 pieces to move in strictly limited ways. Designing a successful chess strategy is a tremendous achievement, but describing the pieces and their allowed moves to a computer is not the challenging part of this task. Chess can be entirely described by a very short, fully formalized list of rules, which can be easily prepared in advance by programmers.
Ironically, abstract and formal tasks are among the most challenging cognitive tasks for humans, yet they are among the easiest for computers. Computers have long been able to defeat the best human chess players, but only recently have they reached human average levels in tasks such as object recognition or speech recognition. A person’s daily life requires a vast amount of knowledge about the world. Much of this knowledge is subjective and intuitive, making it difficult to express clearly in a formal way. Computers need to acquire the same knowledge to exhibit intelligence. A key challenge in artificial intelligence is how to convey this non-formalized knowledge to computers.
Some AI projects have attempted to hard-code knowledge about the world using formal languages. Computers can use logical reasoning rules to automatically understand statements in these formal languages. This is known as the well-known AI knowledge base approach. However, these projects ultimately did not achieve significant success. The most famous project is Cyc (Lenat and Guha, 1989). Cyc includes an inference engine and a database of statements described in the CycL language. These statements are input by human supervisors, which is a cumbersome process. People have managed to design sufficiently complex formal rules to precisely describe the world. For example, Cyc cannot understand a story about a person named Fred shaving in the morning (Linde, 1992). Its inference engine detected inconsistencies in the story: it knows that a human body does not contain electrical components, but since Fred is holding an electric razor, it concludes that the entity—“Fred While Shaving” contains electrical components. Therefore, it raises the question—whether Fred is still a person while shaving.
The difficulties faced by hard-coded knowledge systems indicate that AI systems need to possess the ability to acquire knowledge independently, that is, the ability to extract patterns from raw data. This ability is known as machine learning. The introduction of machine learning enables computers to solve problems involving real-world knowledge and make seemingly subjective decisions. For instance, a simple machine learning algorithm called logistic regression can decide whether to recommend a cesarean section (Mor-Yosef et al., 1990). Similarly, another simple machine learning algorithm called naive Bayes can distinguish between spam emails and legitimate emails.
The performance of these simple machine learning algorithms largely depends on the representation of the given data. For example, when logistic regression is used to determine whether a mother is suitable for a cesarean section, the AI system does not directly examine the patient. Instead, the doctor needs to provide the system with several relevant pieces of information, such as whether there is a uterine scar. Each piece of information representing the patient is called a feature. Logistic regression learns how these features of the patient are associated with various outcomes. However, it has no influence over how that feature is defined. If the patient’s MRI (magnetic resonance imaging) scan is used as input for logistic regression instead of the doctor’s formal report, it will be unable to make useful predictions. The correlation between a single pixel in an MRI scan and complications during childbirth is negligible.
Throughout computer science and daily life, reliance on representation is a common phenomenon. In computer science, if a data set is cleverly structured and intelligently indexed, operations like search can be processed exponentially faster. People can easily perform arithmetic operations under the representation of Arabic numerals, but operations under Roman numerals are more time-consuming. Therefore, it is not surprising that the choice of representation has a significant impact on the performance of machine learning algorithms. Figure 1.1 illustrates a simple visual example.
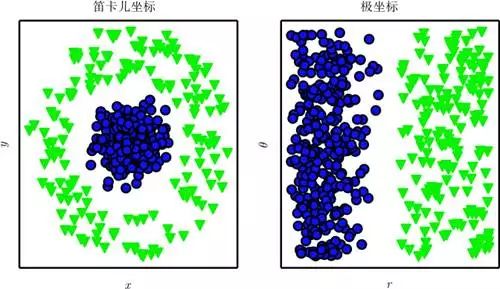
Figure 1.1 Examples of different representations: Suppose we want to draw a line in a scatter plot to separate two categories of data. In the left image, we use Cartesian coordinates to represent the data, making this task impossible. In the right image, we use polar coordinates to represent the data, allowing this task to be easily solved with a vertical line (this figure was created in collaboration with David Warde-Farley).
Many AI tasks can be solved by first extracting a suitable set of features and then providing these features to simple machine learning algorithms. For instance, in the task of identifying a speaker by voice, a useful feature is an estimate of the size of their vocal tract. This feature provides strong clues for determining whether the speaker is male, female, or a child.
However, for many tasks, it is challenging to know which features should be extracted. For example, suppose we want to write a program to detect cars in photos. We know that cars have wheels, so we might think of using the presence or absence of wheels as a feature. Unfortunately, we find it difficult to accurately describe what wheels look like based on pixel values. Although wheels have simple geometric shapes, their images may vary due to the scene, such as shadows falling on the wheels, shiny metal parts illuminated by the sun, the car’s fender, or foreground objects partially obscuring the wheels.
One way to tackle this problem is to use machine learning to discover the representation itself, rather than merely mapping the representation to the output.
This approach is known as representation learning. The learned representations often perform better than manually designed representations. Moreover, they require minimal human intervention, allowing AI systems to quickly adapt to new tasks. Representation learning algorithms can discover a good set of features for simple tasks in just a few minutes, while for complex tasks, it may take several hours to months. Manually designing features for a complex task requires a significant amount of human labor, time, and effort, potentially taking decades of research from entire communities of researchers.
A typical example of representation learning algorithms is autoencoders. An autoencoder consists of an encoder function and a decoder function. The encoder function transforms the input data into a different representation, while the decoder function converts this new representation back to its original form. We expect that as the input data passes through the encoder and decoder, as much information as possible is retained, while hoping that the new representation possesses various desirable properties, which is also the training goal of the autoencoder. To achieve different properties, we can design different forms of autoencoders.
When designing features or algorithms for learning features, our goal is often to separate the factors of variation that explain the observed data. In this context, the term “factors” refers to different sources of influence; factors are typically not multiplicative combinations. These factors are often unobservable quantities. Instead, they may represent unobservable objects in the real world or unobservable forces that influence observable quantities. They may also exist in human thought as concepts that provide useful simplified explanations or inferences about the observed data. They can be seen as concepts or abstractions of the data that help us understand its richness and diversity. When analyzing speech recordings, factors of variation include the speaker’s age, gender, accent, and the words they are saying. When analyzing images of cars, factors of variation include the car’s position, color, angle of the sun, and brightness.
In many real-world AI applications, difficulties mainly arise from multiple factors of variation simultaneously influencing every piece of data we can observe. For instance, in an image containing a red car, a single pixel may appear very close to black at night. The shape of the car’s outline depends on the perspective. Most applications require us to disentangle the factors of variation and ignore the factors we are not concerned with.
Clearly, extracting such high-level, abstract features from raw data is very challenging. Many factors of variation, such as speech accents, can only be identified through complex, near-human-level understanding of the data. This is almost as difficult as obtaining a representation of the original problem, thus at first glance, representation learning does not seem to help us.
Deep learning addresses the core issue of representation learning by expressing complex representations through other simpler representations.
Deep learning enables computers to build complex concepts from simpler ones. Figure 1.2 illustrates how deep learning systems represent the concept of a person in an image by combining simpler concepts (such as edges and contours, which in turn are defined by lines). A typical example of deep learning models is the feedforward deep network or multilayer perceptron (MLP). A multilayer perceptron is simply a mathematical function that maps a set of input values to output values. This function is composed of many simpler functions. We can think of each application of different mathematical functions as providing a new representation for the input.
The idea of learning the correct representation of data is one perspective for understanding deep learning. Another perspective is that deep learning prompts computers to learn a multi-step computational program. Each layer of representation can be considered as the state of the computer’s memory after executing another set of instructions in parallel. Deeper networks can sequentially execute more instructions. Sequential instructions provide tremendous capability because later instructions can refer to the results of earlier instructions. From this perspective, not all information in the activation function of a given layer contains the factors of variation that explain the input. The representation also stores state information to help the program understand the input. Here, the state information is similar to counters or pointers in traditional computer programs. It is independent of the specific input content but helps the model organize its processing.
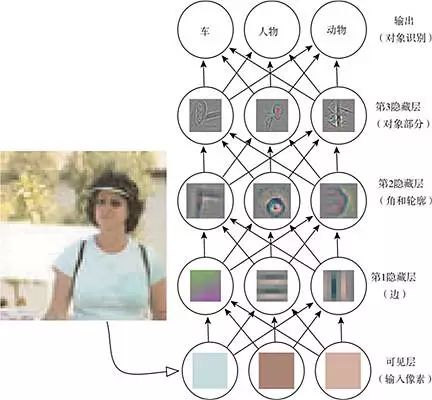
Figure 1.2 Schematic diagram of deep learning models. Computers find it difficult to understand the meaning of raw sensory input data, such as images represented as a set of pixel values. The function that maps a set of pixels to object identities is very complex. If processed directly, learning or evaluating this mapping seems impossible. Deep learning breaks down the required complex mapping into a series of nested simple mappings (each described by different layers of the model) to solve this problem. The input is presented at the visible layer, named so because it contains the variables we can observe. Then there is a series of hidden layers that extract increasingly abstract features from the image. Since their values are not given in the data, these layers are referred to as “hidden layers”; the model must determine which concepts are beneficial for explaining the relationships in the observed data. The image here visualizes the features represented by each hidden unit. Given a pixel, the first layer can easily identify edges by comparing the brightness of adjacent pixels. With the edges described by the first hidden layer, the second hidden layer can easily search for sets of edges that can be recognized as corners and extended contours. Given the image descriptions of corners and contours from the second hidden layer, the third hidden layer can find specific sets of contours and corners to detect parts of specific objects. Finally, based on the parts of objects included in the image description, the objects present in the image can be identified (this figure is cited with permission from Zeiler and Fergus (2014)).
Currently, there are mainly two ways to measure the depth of a model. One way is based on evaluating the number of sequential instructions required to execute the architecture. Suppose we represent the model as a flowchart that computes the corresponding output after a given input; we can consider the longest path in this flowchart as the depth of the model. Just as two equivalent programs written in different languages will have different lengths, the same function can be drawn as flowcharts of different depths, depending on the functions we can use as a step. Figure 1.3 illustrates how the choice of language gives the same architecture two different measures.
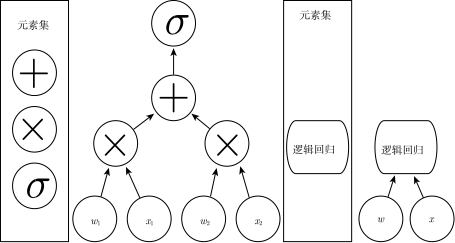
Figure 1.3 A schematic diagram of the computational graph that maps input to output, where each node performs an operation. The depth is the length of the longest path from input to output, but it depends on the definition of the possible computational steps. The computations shown in these graphs are the output of the logistic regression model,
σ(wTx), whereσis the logistic sigmoid function. If addition, multiplication, and logistic sigmoid are used as elements of the computer language, then the depth of this model is 3; if logistic regression is viewed as an element itself, then the depth of this model is 1.
Another method used in deep probabilistic models is not to view the depth of the computational graph as the model depth, but to view the depth of the graph that describes how concepts relate to each other as the model depth. In this case, the depth of the computational flowchart for each concept representation may be deeper than the graph for the concepts themselves. This is because the system’s understanding of simpler concepts can be further refined after being given information about more complex concepts. For example, when an AI system observes an image of a face with one eye in shadow, it may initially see only one eye. However, when it detects the presence of a face, it can infer that the second eye may also be present. In this case, the graph of concepts only includes two layers (one layer about eyes and another about faces), but if we refine the estimates of each concept, additional n computations may be required, making the computational graph contain 2n layers.
Since it is not always clear which depth of the computational graph and the depth of the probabilistic model graph is the most meaningful, and since different people choose different minimal sets of elements to build their respective graphs, just as there is no single correct value for the length of a computer program, there is also no single correct value for the depth of the architecture. Furthermore, there is no consensus on how deep a model must be to be referred to as “deep.” However, it is undeniable that compared to traditional machine learning, deep learning research involves more combinations of learned functions or learned concepts.
In summary, the theme of this book—deep learning—is one of the pathways to artificial intelligence. Specifically, it is a type of machine learning, a technique that allows computer systems to improve from experience and data. We firmly believe that machine learning can build AI systems that operate in complex real-world environments and is the only practical method. Deep learning is a specific type of machine learning that possesses powerful capabilities and flexibility, representing the vast world as a nested hierarchical system of concepts (where complex concepts are defined by the relationships between simpler concepts, general abstractions are generalized into higher-level abstract representations). Figure 1.4 illustrates the relationships between these different AI disciplines. Figure 1.5 shows the high-level principles of how each discipline works.
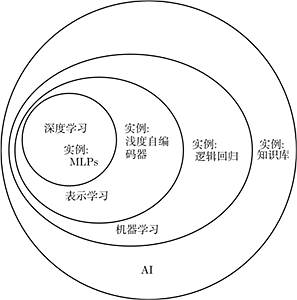
Figure 1.4 A Venn diagram showing that deep learning is both a type of representation learning and a type of machine learning, applicable to many (but not all) AI methods. Each part of the Venn diagram includes an example of an AI technology.
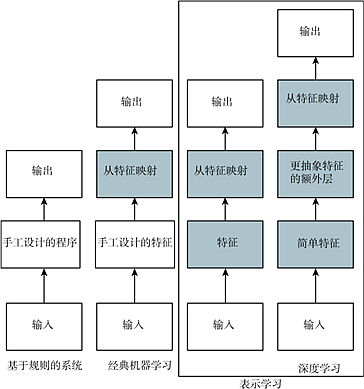
Figure 1.5 A flowchart showing how different parts of AI systems relate to each other across different AI disciplines. The shaded boxes represent components that can learn from data.
The Historical Trends of Deep Learning
The easiest way to understand deep learning is through historical context. Here, we will only point out a few key trends in deep learning without providing a detailed history:
-
Deep learning has a long and rich history, but as many different philosophical viewpoints have gradually faded, the corresponding names have also become obscure.
-
As the amount of available training data continues to increase, deep learning becomes more useful.
-
Over time, the computer software and hardware infrastructure for deep learning has improved, and the scale of deep learning models has grown accordingly.
-
Over time, deep learning has tackled increasingly complex applications and continuously improved accuracy.
The Many Names and Fate Changes of Neural Networks
We expect that many readers of this book have heard of deep learning, this exciting new technology, and may be surprised by a book mentioning the “history” of an emerging field. In fact, the history of deep learning can be traced back to the 1940s. Deep learning appears to be an entirely new field, simply because it was relatively obscure until the current popular years, and also because it has been given many different names (most of which are no longer in use) before recently becoming widely known as “deep learning.” This field has undergone many name changes, reflecting the influence of different researchers and perspectives.
To comprehensively recount the history of deep learning is beyond the scope of this book. However, some basic background is useful for understanding deep learning. It is generally believed that deep learning has undergone three waves of development: from the 1940s to the 1960s, the early forms of deep learning appeared in cybernetics; from the 1980s to the 1990s, deep learning manifested as connectionism; and it was not until 2006 that it truly revived under the name of deep learning. Figure 1.7 provides a quantitative display.
Some of the earliest learning algorithms we know today aimed to simulate computational models of biological learning, that is, models of how the brain learns or why it can learn. As a result, deep learning faded under the name of artificial neural networks (ANN). At that time, deep learning models were considered systems inspired by biological brains (whether human brains or those of other animals). Although some neural networks in machine learning are sometimes used to understand brain functions (Hinton and Shallice, 1991), they were generally not designed to be true models of biological function. The neural perspective of deep learning is inspired by two main ideas: one idea is that the brain serves as an example proving that intelligent behavior is possible, thus conceptually, the direct path to establishing intelligence is to reverse-engineer the computational principles behind the brain and replicate its functions; another view is that understanding the principles behind the brain and human intelligence is also very interesting, so machine learning models, in addition to solving engineering applications, would also be useful if they can further our understanding of these fundamental scientific questions.
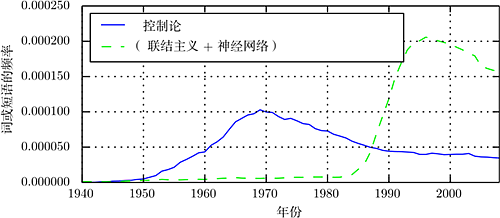
Figure 1.7 The historical waves of artificial neural network research, measured by the frequency of the phrases “cybernetics,” “connectionism,” or “neural networks” in Google Books (the figure shows the first two waves, with the third wave appearing only recently). The first wave began in the 1940s to the 1960s with cybernetics, alongside the development of biological learning theories (McCulloch and Pitts, 1943; Hebb, 1949) and the implementation of the first models (such as the perceptron (Rosenblatt, 1958)), which could train individual neurons. The second wave began during the connectionist approach from 1980 to 1995, which could train neural networks with one or two hidden layers using backpropagation (Rumelhart et al., 1986a). The current third wave, which is deep learning, began around 2006 (Hinton et al., 2006a; Bengio et al., 2007a; Ranzato et al., 2007a) and emerged in book form in 2016. Additionally, the first two waves similarly appeared in the book much later than their corresponding scientific activities.
Modern terminology of “deep learning” transcends the neuroscientific perspective of current machine learning models. It appeals to the more general principle of learning multi-level combinations, which can also be applied to machine learning frameworks that are not inspired by neuroscience.
The earliest predecessors of modern deep learning stemmed from simple linear models from a neuroscientific perspective. These models were designed to use a set of n inputs x1,··· ,xn and relate them to an output y. These models aimed to learn a set of weights w1,··· ,wn and compute their output f(x,w) = x1w1 + ··· + xnwn. As shown in Figure 1.7, the first wave of neural network research is called cybernetics.
The McCulloch-Pitts neuron (McCulloch and Pitts, 1943) is an early model of brain function. This linear model identifies two different categories of input by examining the sign of the function f(x,w). Clearly, the weights of the model need to be correctly set for the model’s output to correspond to the expected categories. These weights can be set by an operator. In the 1950s, the perceptron (Rosenblatt, 1956, 1958) became the first model capable of learning weights based on input samples from each category. Around the same time, the adaptive linear element (ADALINE) simply returned the value of the function f(x) itself to predict a real number (Widrow and Hoff, 1960), and it could also learn to predict these numbers from data.
These simple learning algorithms significantly influenced the modern landscape of machine learning. The training algorithm used to adjust the weights of ADALINE is a special case known as stochastic gradient descent. The slightly improved stochastic gradient descent algorithm remains the main training algorithm in today’s deep learning.
The models based on the functions f(x,w) used in perceptrons and ADALINE are called linear models. Although in many cases, these models are trained in ways different from the original models, they remain the most widely used machine learning models today.
Linear models have many limitations. The most notable is that they cannot learn the XOR (exclusive or) function, i.e., f([0,1],w) = 1 and f([1,0],w) = 1, but f([1,1],w) = 0 and f([0,0],w) = 0. Observers noting this flaw in linear models generally developed a resistance to biologically inspired learning (Minsky and Papert, 1969). This led to the first major decline of the neural network craze.
Now, neuroscience is seen as an important source of inspiration for deep learning research, but it is no longer the main guiding force in the field.
Today, the role of neuroscience in deep learning research has been diminished, primarily because we simply do not have enough information about the brain to guide its use. To gain a deep understanding of the algorithms actually used by the brain, we need the capacity to simultaneously monitor (at least) thousands of interconnected neurons’ activities. We cannot do this, so we have not even understood the simplest and most well-studied parts of the brain (Olshausen and Field, 2005).
Neuroscience has given us reasons to believe that a single deep learning algorithm can solve many different tasks. Neurologists found that if the brain of a ferret is rewired to transmit visual signals to the auditory region, they can learn to “see” using the brain’s auditory processing area (Von Melchner et al., 2000). This suggests that the brains of most mammals can solve most different tasks using a single algorithm. Prior to this hypothesis, machine learning research was relatively fragmented, with researchers studying natural language processing, computer vision, motion planning, and speech recognition in different communities. Today, these application communities remain independent, but it is common for deep learning research groups to study many or even all of these application areas simultaneously.
We can glean some rough guidelines from neuroscience. The basic idea that intelligence can emerge from the interactions between computational units is inspired by the brain. The new cognitive model (Fukushima, 1980) was inspired by the structure of the mammalian visual system, introducing a powerful model architecture for processing images that later became the foundation for modern convolutional networks (LeCun et al., 1998c) (see Section 9.10). Most neural networks today are based on a neural unit model called rectified linear unit. The original cognitive model (Fukushima, 1975) was inspired by our knowledge of brain function and introduced a more complex version. The simplified modern version has absorbed ideas from different perspectives, with Nair and Hinton (2010b) and Glorot et al. (2011a) citing neuroscience as an influence, while Jarrett et al. (2009a) cite more engineering-oriented influences. While neuroscience is an important source of inspiration, it should not be viewed as rigid guidance. We know that real neurons compute functions very different from modern rectified linear units, but systems that are closer to real neural networks have not led to improvements in machine learning performance. Furthermore, while neuroscience has successfully inspired some neural network architectures, we do not yet have enough understanding of biological learning to provide much guidance for the learning algorithms used to train these architectures.
The media often emphasize the similarities between deep learning and the brain. Indeed, deep learning researchers are more likely than researchers in other machine learning fields (such as kernel methods or Bayesian statistics) to cite the brain as an influence, but one should not assume that deep learning is attempting to simulate the brain. Modern deep learning draws inspiration from many fields, particularly foundational elements of applied mathematics such as linear algebra, probability theory, information theory, and numerical optimization. While some deep learning researchers cite neuroscience as an important source of inspiration, others are completely uninterested in neuroscience.
It is worth noting that attempts to understand how the brain works at the algorithmic level do exist and are developing well. This effort is primarily known as “computational neuroscience” and is an independent field from deep learning. It is common for researchers to move back and forth between the two fields. The deep learning field primarily focuses on how to build computer systems that successfully solve tasks requiring intelligence, while the computational neuroscience field mainly focuses on building accurate models of how the brain actually works.
In the 1980s, the second wave of neural network research largely accompanied a trend known as connectionism or parallel distributed processing (Rumelhart et al., 1986d; McClelland et al., 1995). Connectionism emerged in the context of cognitive science. Cognitive science is an interdisciplinary approach to understanding thought, integrating multiple different levels of analysis. In the early 1980s, most cognitive scientists studied symbolic reasoning models. Although this was popular, symbolic models struggled to explain how the brain actually uses neurons to perform reasoning functions.
Connectionists began to study cognitive models based on the actual neural systems (Touretzky and Minton, 1985), many of which revived ideas traceable to psychologist Donald Hebb’s work in the 1940s (Hebb, 1949).
The central idea of connectionism is that intelligence can be achieved when a network connects a large number of simple computational units. This insight also applies to the neurons in biological neural systems, as they play a similar role to hidden units in computational models.
Several key concepts formed during the connectionist period of the 1980s remain very important in today’s deep learning.
One of these concepts is distributed representation (Hinton et al., 1986). The idea is that each input to the system should be represented by multiple features, and each feature should participate in the representation of multiple possible inputs. For example, suppose we have a visual system capable of recognizing red, green, or blue cars, trucks, and birds; one way to represent these inputs is to activate individual neurons or hidden units for each of the 9 possible combinations: red truck, red car, red bird, green truck, etc. This requires 9 different neurons, and each neuron must independently learn the concepts of color and object identity. One way to improve this situation is to use distributed representation, which describes color with 3 neurons and object identity with 3 neurons. This only requires 6 neurons instead of 9, and the neuron representing red can learn red from images of cars, trucks, and birds, rather than just from images of one specific category.
The concept of distributed representation is central to this book, and we will describe it in more detail in Chapter 15.
Another important achievement of the connectionist wave is the successful use of backpropagation in training deep neural networks with internal representations and the popularization of the backpropagation algorithm (Rumelhart et al., 1986c; LeCun, 1987). Although this algorithm fell out of favor for some time, it remains the dominant method for training deep models as of the writing of this book.
In the 1990s, researchers made significant progress in using neural networks for sequence modeling. Hochreiter (1991b) and Bengio et al. (1994b) pointed out some fundamental mathematical challenges in modeling long sequences, which will be described in Section 10.7. Hochreiter and Schmidhuber (1997) introduced long short-term memory (LSTM) networks to address these challenges. Today, LSTMs are widely used in many sequence modeling tasks, including many natural language processing tasks by Google.
The second wave of neural network research continued until the mid-1990s. Startups based on neural networks and other AI technologies began seeking investment, with ambitious but unrealistic approaches. When AI research failed to meet these unreasonable expectations, investors became disappointed. Meanwhile, other fields of machine learning made progress. For example, kernel methods (Boser et al., 1992; Cortes and Vapnik, 1995; Schölkopf et al., 1999) and graphical models (Jordan, 1998) achieved good results on many important tasks. These two factors led to the second decline of the neural network craze, which lasted until 2007.
During this period, neural networks continued to achieve impressive performances on certain tasks (LeCun et al., 1998c; Bengio et al., 2001a). The Canadian Institute for Advanced Research (CIFAR) helped sustain neural network research through its Neural Computation and Adaptive Perception (NCAP) research program, which united machine learning research groups led by Geoffrey Hinton, Yoshua Bengio, and Yann LeCun at the University of Toronto, the University of Montreal, and New York University, respectively. This multidisciplinary CIFAR NCAP research program also included neuroscientists, human experts, and computer vision specialists.
At that time, it was widely believed that deep networks were difficult to train. Now we know that the algorithms that existed in the 1980s could work very well, but it was not until around 2006 that this became apparent. This was likely simply due to the high computational costs, making it difficult to conduct sufficient experiments with the hardware available at the time.
The third wave of neural network research began with breakthroughs in 2006. Geoffrey Hinton demonstrated that a neural network called “deep belief network” could be effectively trained using a strategy called “greedy layer-wise pre-training” (Hinton et al., 2006a), which we will describe in more detail in Section 15.1. Other CIFAR-affiliated research groups quickly showed that the same strategy could be used to train many other types of deep networks (Bengio and LeCun, 2007a; Ranzato et al., 2007b), systematically helping to improve generalization on test samples. This wave of neural network research popularized the term “deep learning,” emphasizing that researchers now had the capability to train previously untrainable deeper neural networks and focusing on the theoretical significance of depth (Bengio and LeCun, 2007b; Delalleau and Bengio, 2011; Pascanu et al., 2014a; Montufar et al., 2014). At this point, deep neural networks surpassed competing AI systems based on other machine learning techniques and manually designed features. As of the writing of this book, the third wave of neural network development is still ongoing, although the focus of deep learning research has undergone significant changes during this period. The third wave has begun to look at new unsupervised learning techniques and the generalization capabilities of deep models on small datasets, but currently, more interest remains in the capabilities of traditional supervised learning algorithms and deep models to fully utilize large labeled datasets.
The Increasing Amount of Data
One might wonder, since the first experiments with artificial neural networks were conducted in the 1950s, why deep learning has only recently been considered a key technology? Since the 1990s, deep learning has been successfully applied to commercial applications, but it was often regarded as an art that only experts could use rather than a technology, a view that persisted until recently. Indeed, achieving good performance from a deep learning algorithm requires some expertise. Fortunately, as the amount of training data increases, the required expertise is decreasing. Learning algorithms that achieve human-level performance on complex tasks are almost the same as the learning algorithms that struggled to solve toy problems in the 1980s, although the models trained with these algorithms have undergone transformation, simplifying the training of extremely deep architectures. The most important advancement is that we now have the resources needed to successfully train these algorithms. Figure 1.8 shows how the size of benchmark datasets has significantly increased over time.
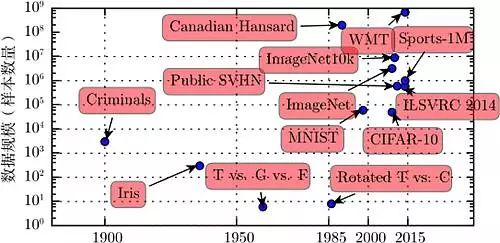
Figure 1.8 The increasing amount of data. In the early 20th century, statisticians used hundreds or thousands of manually created metrics to study datasets (Garson, 1900; Gosset, 1908; Anderson, 1935; Fisher, 1936). From the 1950s to the 1980s, pioneers of biologically inspired machine learning typically used small synthetic datasets, such as low-resolution letter bitmaps, designed to demonstrate that neural networks could learn specific functions at low computational costs (Widrow and Hoff, 1960; Rumelhart et al., 1986b). In the 1980s and 1990s, machine learning became more statistical and began to utilize larger datasets containing thousands of samples, such as the MNIST dataset of handwritten digits (as shown in Figure 1.9) (LeCun et al., 1998c). In the first decade of the 21st century, similarly sized and more complex datasets continued to emerge, such as the CIFAR-10 dataset (Krizhevsky and Hinton, 2009). At the end of this decade and in the next five years, significantly larger datasets (containing tens of thousands to millions of samples) completely changed what deep learning could achieve. These datasets include public datasets of Street View House Numbers (Netzer et al., 2011), various versions of the ImageNet dataset (Deng et al., 2009, 2010a; Russakovsky et al., 2014a), and the Sports-1M dataset (Karpathy et al., 2014). At the top of the figure, we see that datasets for translating sentences are often much larger than other datasets, such as the IBM dataset based on the Canadian Hansard (Brown et al., 1990) and the WMT 2014 English-French dataset (Schwenk, 2014).
This trend is driven by the increasing digitization of society. As our activities increasingly take place on computers, what we do is also increasingly recorded. As computers become more interconnected, these records become easier to manage centrally and easier to organize into datasets suitable for machine learning applications. As the main burden of statistical estimation (observing a small amount of data to generalize to new data) has been alleviated, the “big data” era has made machine learning easier. As of 2016, a rough rule of thumb is that supervised deep learning algorithms generally achieve acceptable performance with about 5,000 labeled samples per category, and when at least 10 million labeled samples are used for training, they will achieve or exceed human performance. Furthermore, achieving success on smaller datasets is an important research area, for which we should particularly focus on how to fully utilize large amounts of unlabeled samples through unsupervised or semi-supervised learning.

Figure 1.9 Input examples from the MNIST dataset. “NIST” stands for the National Institute of Standards and Technology, the agency that originally collected these data. “M” stands for “modified“, as the data have been preprocessed to make them easier to use with machine learning algorithms. The MNIST dataset includes scans of handwritten digits and related labels (indicating which digit from 0 to 9 is contained in each image). This simple classification problem is one of the simplest and most widely used tests in deep learning research. Although modern techniques can easily solve this problem, it remains very popular. Geoffrey Hinton describes it as “the fruit fly of machine learning,” meaning that machine learning researchers can study their algorithms under controlled laboratory conditions, just as biologists often study fruit flies.
The Increasing Scale of Models
In the 1980s, neural networks could only achieve relatively small successes, while another crucial reason for the current success of neural networks is that we now have the computational resources to run larger models. One of the main insights of connectionism is that intelligence emerges when many neurons in animals work together. Individual neurons or small sets of neurons are not particularly useful.
Biological neurons are not particularly densely connected. As shown in Figure 1.10, for decades, the number of connections per neuron in our machine learning models has been on the same order of magnitude as that in the brains of mammals.
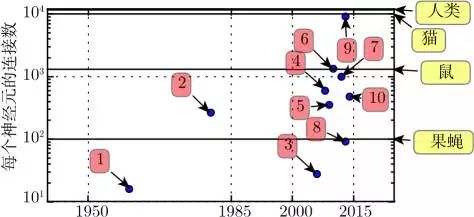
Figure 1.10 The increasing number of connections per neuron. Initially, the number of connections between neurons in artificial neural networks was limited by hardware capabilities. Now, the number of connections between neurons is mostly a design consideration. In some artificial neural networks, the number of connections per neuron is comparable to that of a cat, and for other neural networks, it is common for the number of connections per neuron to be comparable to that of smaller mammals (like mice). Even the number of connections per neuron in the human brain is not excessively high. The scale of biological neural networks is sourced from Wikipedia (2015).
1. Adaptive Linear Element (Widrow and Hoff, 1960); 2. Neural Cognitive Model (Fukushima, 1980); 3. GPU-Accelerated Convolutional Networks (Chellapilla et al., 2006); 4. Deep Boltzmann Machines (Salakhutdinov and Hinton, 2009a); 5. Unsupervised Convolutional Networks (Jarrett et al., 2009b); 6. GPU-Accelerated Multilayer Perceptrons (Ciresan et al., 2010); 7. Distributed Autoencoders (Le et al., 2012); 8. Multi-GPU Convolutional Networks (Krizhevsky et al., 2012a); 9. COTS HPC Unsupervised Convolutional Networks (Coates et al., 2013); 10. GoogLeNet (Szegedy et al., 2014a).
As shown in Figure 1.11, until recently, neural networks were astonishingly small in terms of total neuron count. Since the introduction of hidden units, the scale of artificial neural networks has approximately doubled every 2.4 years. This growth has been driven by larger memory, faster computers, and larger available datasets. Larger networks can achieve higher accuracy on more complex tasks. This trend appears likely to continue for decades. Unless there is a capability to rapidly scale new technologies, it will be at least until the 2050s that artificial neural networks will have a comparable number of neurons to the human brain. The functions represented by biological neurons may be more complex than those represented by current artificial neurons, so biological neural networks may be even larger than depicted in the figure.
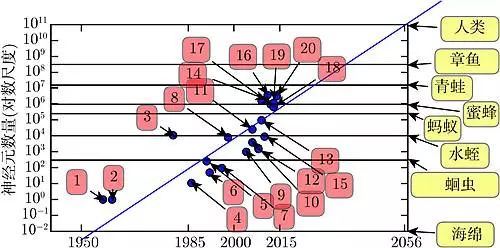
Figure 1.11 The increasing scale of neural networks. Since the introduction of hidden units, the scale of artificial neural networks has approximately doubled every 2.4 years. The scale of biological neural networks is sourced from Wikipedia (2015).
1. Perceptron (Rosenblatt, 1958, 1962); 2. Adaptive Linear Element (Widrow and Hoff, 1960); 3. Neural Cognitive Model (Fukushima, 1980); 4. Early Backpropagation Networks (Rumelhart et al., 1986b); 5. Recurrent Neural Networks for Speech Recognition (Robinson and Fallside, 1991); 6. Multilayer Perceptrons for Speech Recognition (Bengio et al., 1991); 7. Uniform Field Sigmoid Belief Networks (Saul et al., 1996); 8. LeNet5 (LeCun et al., 1998c); 9. Echo State Networks (Jaeger and Haas, 2004); 10. Deep Belief Networks (Hinton et al., 2006a); 11. GPU-Accelerated Convolutional Networks (Chellapilla et al., 2006); 12. Deep Boltzmann Machines (Salakhutdinov and Hinton, 2009a); 13. GPU-Accelerated Deep Belief Networks (Raina et al., 2009a); 14. Unsupervised Convolutional Networks (Jarrett et al., 2009b); 15. GPU-Accelerated Multilayer Perceptrons (Ciresan et al., 2010); 16. OMP-1 Networks (Coates and Ng, 2011); 17. Distributed Autoencoders (Le et al., 2012); 18. Multi-GPU Convolutional Networks (Krizhevsky et al., 2012a); 19. COTS HPC Unsupervised Convolutional Networks (Coates et al., 2013); 20. GoogLeNet (Szegedy et al., 2014a).
It is not surprising that neural networks with fewer neurons than a leech cannot solve complex artificial intelligence problems. Even today’s networks, while relatively large from a computational systems perspective, are actually smaller than the nervous systems of relatively primitive vertebrates (like frogs).
Due to faster CPUs, the emergence of general-purpose GPUs, faster network connections, and better distributed computing software infrastructure, the increasing model scale is one of the most significant trends in the history of deep learning. This trend is widely expected to continue well into the future.
The Increasing Accuracy, Complexity, and Impact on the Real World
Since the 1980s, the ability of deep learning to provide precise recognition and prediction has been improving. Moreover, deep learning has successfully been applied to an increasingly wide range of practical problems.
The earliest deep models were used to recognize single objects in cropped, compact, and very small images (Rumelhart et al., 1986d). Since then, the size of images that neural networks can handle has gradually increased. Modern object recognition networks can process rich, high-resolution photos without needing to crop around the objects being recognized (Krizhevsky et al., 2012b). Similarly, the earliest networks could only recognize two objects (or, in some cases, the presence or absence of a single class of objects), while these modern networks can typically recognize at least 1,000 different categories of objects. The largest competition in object recognition is the annual ImageNet Large Scale Visual Recognition Challenge (ILSVRC). An exciting moment in the rapid rise of deep learning was when convolutional networks first significantly won this challenge, reducing the top-5 error rate from 26.1% to 15.3% (Krizhevsky et al., 2012b), meaning that for each image, the correct class label appeared in the top 5 of the list generated by the convolutional network for all but 15.3% of the test samples. Since then, deep convolutional networks have consistently won these competitions, and as of the writing of this book, the latest results in deep learning have reduced the top-5 error rate in this competition to 3.6%, as shown in Figure 1.12.
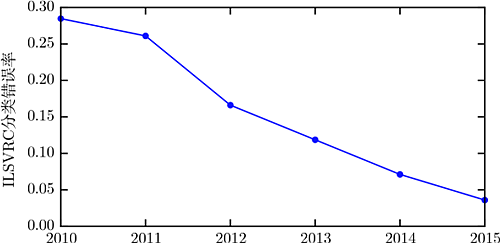
Figure 1.12 The decreasing error rates. As deep networks have achieved the scale necessary to compete in the ImageNet Large Scale Visual Recognition Challenge, they have won every year and produced increasingly lower error rates. Data sourced from Russakovsky et al. (2014b) and He et al. (2015).
Deep learning has also had a significant impact on speech recognition. After improvements in the 1990s, speech recognition stagnated until around 2000. The introduction of deep learning (Dahl et al., 2010; Deng et al., 2010b; Seide et al., 2011; Hinton et al., 2012a) caused a sharp decline in speech recognition error rates, with some even halving. We will explore this history in more detail in Section 12.3.
Deep networks have also achieved remarkable successes in pedestrian detection and image segmentation (Sermanet et al., 2013; Farabet et al., 2013; Couprie et al., 2013), and have surpassed human performance in traffic sign classification (Ciresan et al., 2012).
As the scale and accuracy of deep networks have increased, the tasks they can solve have also become increasingly complex. Goodfellow et al. (2014d) demonstrated that neural networks can learn to output entire sequences of characters describing an image rather than merely recognizing single objects. Previously, it was generally believed that this learning required labeling individual elements in the sequence (Gulcehre and Bengio, 2013). Recurrent neural networks, such as the previously mentioned LSTM sequence models, are now used to model relationships between sequences and other sequences, rather than merely fixed relationships between inputs. This sequence-to-sequence learning seems to lead to another disruptive development in applications—machine translation (Sutskever et al., 2014; Bahdanau et al., 2015).
This increasing complexity trend has pushed towards the logical conclusion of introducing neural Turing machines (Graves et al., 2014), which can learn to read from and write to storage units. Such neural networks can learn simple programs from samples of expected behavior. For example, learning to sort a series of numbers from scrambled and sorted samples. This self-programming technique is still in its infancy, but in principle, it could be applied to almost any task in the future.
Another major achievement of deep learning is its expansion into the field of reinforcement learning. In reinforcement learning, an autonomous intelligent agent must learn to perform tasks through trial and error without human operator guidance. DeepMind has shown that reinforcement learning systems based on deep learning can learn to play Atari video games and compete with humans on various tasks (Mnih et al., 2015). Deep learning has also significantly improved the performance of robotic reinforcement learning (Finn et al., 2015).
Many applications of deep learning are highly profitable. Deep learning is now used by many top tech companies, including Google, Microsoft, Facebook, IBM, Baidu, Apple, Adobe, Netflix, NVIDIA, and NEC.
Advancements in deep learning also heavily rely on the progress of software infrastructure. Software libraries such as Theano (Bergstra et al., 2010a; Bastien et al., 2012a), PyLearn2 (Goodfellow et al., 2013e), Torch (Collobert et al., 2011b), DistBelief (Dean et al., 2012), Caffe (Jia, 2013), MXNet (Chen et al., 2015), and TensorFlow (Abadi et al., 2015) have all supported important research projects or commercial products.
Deep learning has also contributed to other sciences. Modern convolutional networks used for object recognition provide neuroscientists with models to study visual processing (DiCarlo, 2013). Deep learning has also provided very useful tools for handling massive datasets and making effective predictions in scientific fields. It has been successfully used to predict how molecules interact, helping pharmaceutical companies design new drugs (Dahl et al., 2014), search for subatomic particles (Baldi et al., 2014), and automatically parse microscope images used to construct three-dimensional maps of the human brain (Knowles-Barley et al., 2014), among other applications. We look forward to deep learning appearing in an increasing number of scientific fields in the future.
In summary, deep learning is a method of machine learning. Over the past few decades, it has drawn extensively from our knowledge of the human brain, statistics, and applied mathematics. In recent years, thanks to more powerful computers, larger datasets, and techniques capable of training deeper networks, the popularity and practicality of deep learning have significantly increased. The coming years are filled with further improvements and applications to new domains. To help readers choose chapters, the following diagram provides a flowchart of the high-level organization of this book.
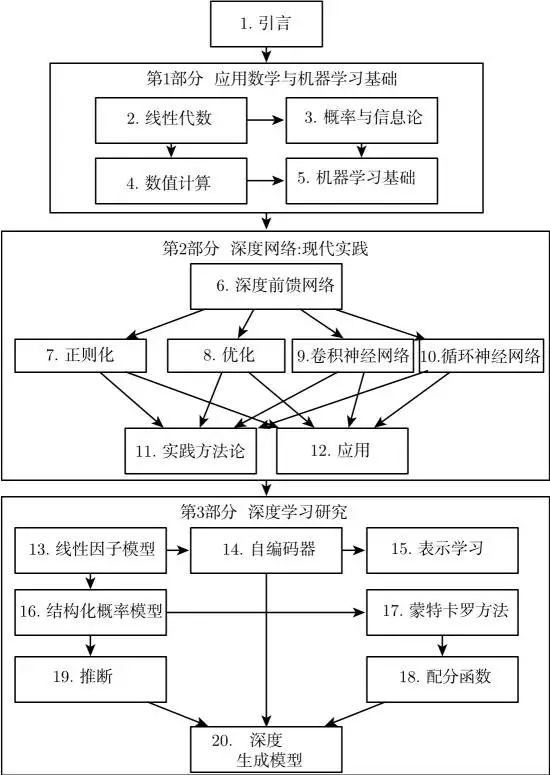
The flowchart of the high-level organization of this book. The arrows from one chapter to another indicate that the previous chapter is essential for understanding the subsequent chapter.
We assume that all readers have a background in computer science. We also assume that readers are familiar with programming and have a basic understanding of computational performance issues, complexity theory, introductory calculus, and some graph theory terminology.
The English version of “Deep Learning” has an accompanying website at www.deeplearningbook.org[5]. The site provides various supplementary materials, including exercises, lecture slides, corrections, and other resources that should be useful for readers and instructors.
Advertisement, Business Cooperation
Please add WeChat: guodongwe1991
(Note: Business Cooperation)