

Unauthorized reproduction is prohibited
Speech Overview
The 2021 World Artificial Intelligence Conference was held from July 8 to 10, 2021, at the Shanghai Expo Center and the Shanghai Expo Exhibition Hall simultaneously. Since its inception in 2018, the World Artificial Intelligence Conference has successfully held three sessions. The 2021 World Artificial Intelligence Conference was jointly hosted by the National Development and Reform Commission, the Ministry of Industry and Information Technology, the Ministry of Science and Technology, the National Internet Information Office, the Chinese Academy of Sciences, the Chinese Academy of Engineering, the China Association for Science and Technology, and the Shanghai Municipal Government.
As one of the organizers of this World Artificial Intelligence Conference, Shuke Technology held a sub-forum on the afternoon of July 9 with the theme of “Data Intelligence, Linking the Future”, where Xu Jin, a partner at Huanshuo, discussed how to use quantitative models and deep learning to make money in the stock market.

*Image from Shuke Technology
Xu Jin mentioned that, unlike traditional stock pricing, quantitative analysis uses input information, including market data, financial data of listed companies, and alternative data such as news sentiment and industrial chains, to train models and utilize deep learning for stock pricing.
In Xu Jin’s view, this process requires handling many key details, the devil is in the details! Taking the time series prediction model as an example, it includes data cleaning, planning processing, preventing overfitting, avoiding future functions, etc. A large number of details determine whether quantitative analysis can be profitable; it is not something that can be easily achieved. “Only when you have a thorough understanding of the market and the data can you achieve relatively good results and make a lot of money,” Xu Jin said.
Xu Jin mentioned that quantitative analysis enhances its deep learning capabilities through model training, increased computing power, and improved cluster usage efficiency, to a certain extent, “shearing” the market. However, from another perspective, quantitative analysis has a significant positive impact on the market. First, it provides liquidity to the market, stabilizing market fluctuations; second, it enhances market efficiency, making company pricing more reasonable; third, it competes with top hedge funds globally, improving the competitiveness of domestic financial transactions.
The WeChat public account for quantitative investment and machine learning, as a supporting media unit for this forum, participated in the reporting work throughout the forum. Below is the summary of Mr. Xu Jin’s speech content at this forum:
How to Use Deep Learning for Stock Pricing
The data required for this model is all publicly available, and the computing power needed is not very large; one or two gaming cards are sufficient. Of course, it cannot support particularly large amounts of capital.
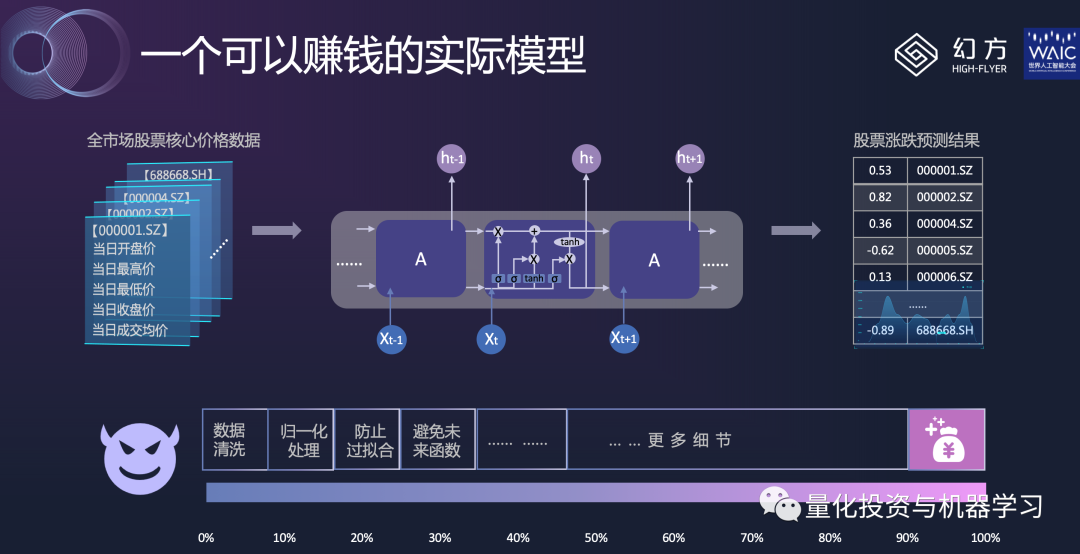
*Image from Huanshuo
First, the input for this model is the price data of all stocks in the market, this model only uses price data (the opening, high, low, close of the day + average price).
The middle image shows a very simple time series prediction model—LSTM. If you truly dedicate yourself to using this model, you can ultimately make money. However, the premise of making money is still: the devil is in the details! This means that even if you do all the above, you still need to handle very critical details, and these details are actually the core issue that determines how much money you can earn.
Take data cleaning as an example, why do we need to clean the data? The data above does not seem very complicated; it is just the high, low, close, and average transaction price of the day. However, there are many hidden issues, such as some stocks being newly listed. Moreover, how do we handle stocks that are limit-up or limit-down? Some stocks have abnormal fluctuations and are even suspected of manipulation by the Securities Regulatory Commission; how should these be handled? For financial time series data, the noise is very high, and the signal-to-noise ratio is very low. If we preprocess some data, it will greatly help your model training. If you do nothing and directly feed the data into the LSTM model, you will hardly get good results, because LSTM is not a miracle worker!
There are many such details, and only when you have a thorough understanding of the market and the data can you achieve better results and make more money.
Our Actual Working Model
This is a practical model that can make money; we are also using it, but this model cannot solve all problems. Next, let me introduce our actual working model.
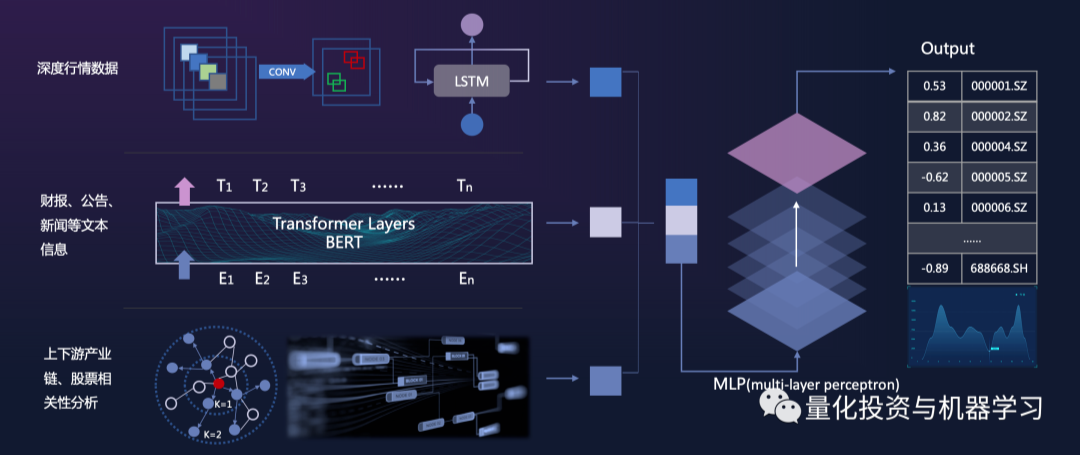
*Image from Huanshuo
The first row is market data, but we have done a lot of processing. Next, we have data from financial reports, announcements, news text information, and analysis of upstream and downstream industrial chains and stock correlations. Only by inputting all these into a multi-layer perceptron model (MLP) can we obtain a complex model that supports large-scale capital management and trading. Because time series models are very resource-intensive and the data volume is very large, the entire process takes a long time!
We used the DGX-A100 server released last July to run this model, which took about 120 days to complete, which is basically meaningless~
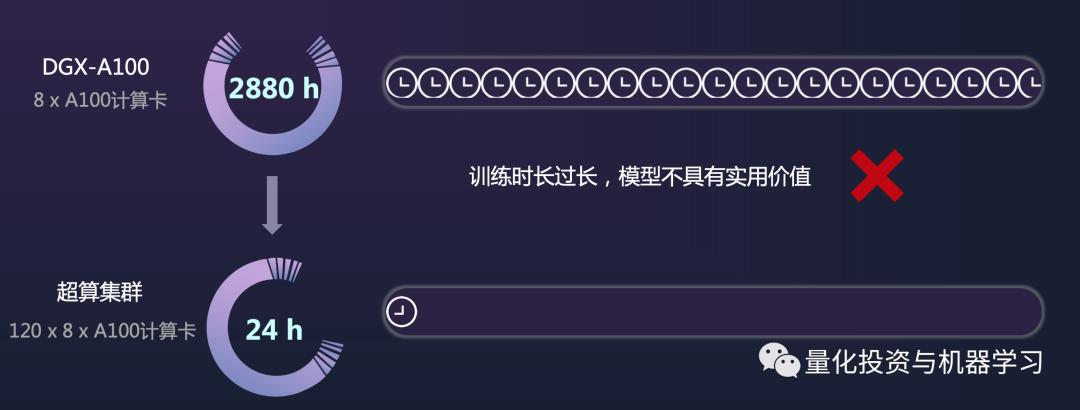
*Image from Huanshuo
So how do we solve this problem?
Stacking Machines, Stacking Computing Power
Of course, it is not just about stacking simply; it’s not just about buying! So how does Huanshuo do it?
Huanshuo Firefly Supercomputer
*Video from Huanshuo Firefly Construction Process
A supercomputer is quite different from an ordinary data center, as its computing power per unit area is particularly high, and it has to solve many complex problems; it is not just about renting a few IDC data centers and putting machines in them to solve the problem.
Currently, the hardware facilities of the Firefly supercomputer are:
-
625 computing nodes, 5000 A100 cards -
200000GB of video memory, 414208GB of memory -
780 PFlop/s machine learning computing power -
28PB SSD storage server -
Deeply optimized BeeGFS file system -
2.0TIB/s read performance
Utilizing the world’s most expensive and fastest 800-port switch (water-cooled switch), with IB interconnection for each node and 200 Gbps transmission bandwidth.
Computing Power Comparison
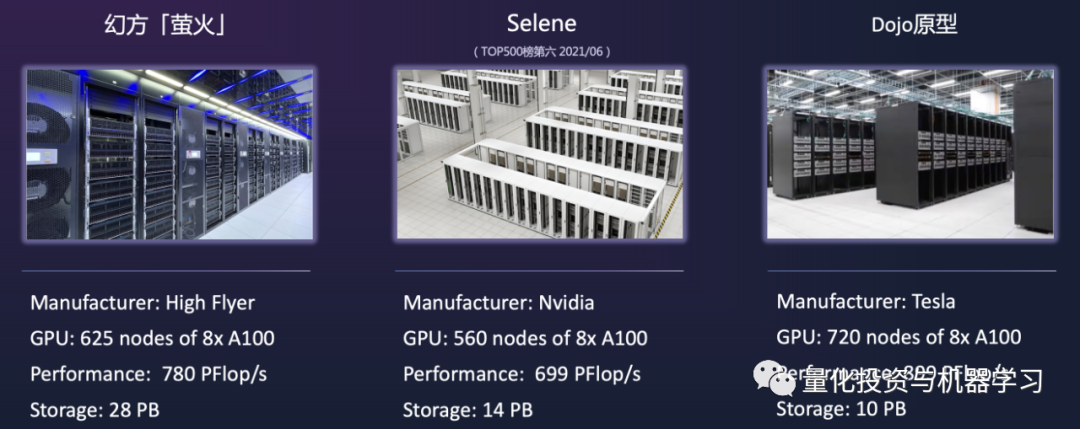
*Image from Huanshuo, all performance statistics are based on theoretical computing power values in TensorFloat-32 format; Nvidia and Tesla supercomputer performance data come from public materials
On the right side of the image is Tesla’s Dojo prototype, on the left is Firefly, and in the middle is Nvidia’s Selene supercomputer, which ranked 6th in the world in the latest ranking this year.
Since Firefly has already been put into use, Firefly has been ahead of Tesla’s supercomputer by at least half a year in this event. The A100 computing card was only released in July last year, Huanshuo was one of the first in the Asia-Pacific region to obtain this card, as it was quite difficult to purchase at that time.
Comparison of Read Speeds and IO500
While continuing to build Firefly in the first half of this year, we encountered many problems; there were too many miners, and we couldn’t buy enough CPUs and hard drives, etc.
Distributed storage is very challenging, the key is its read speed. The right image shows the current global IO500 storage read speed leaderboard, with the fastest read speed being from the Pengcheng Laboratory in China. The left image shows Huanshuo’s results, where a peak can be seen in the graph because Huanshuo conducts stress tests every day at 6 AM, achieving a read speed of 2800GIB/s; during actual training, it has achieved 1800GIB/s. Huanshuo’s current speed is only second to Pengcheng Laboratory, and Huanshuo announced it will participate in the ranking evaluation in the second half of the year.
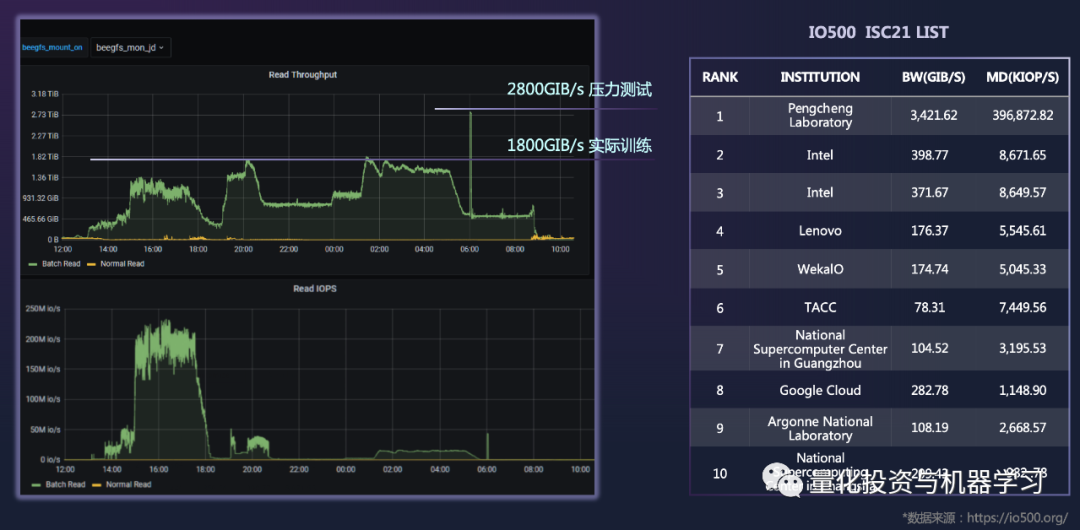
*Image from Huanshuo
In addition, Huanshuo has done a lot regarding how to schedule clusters and improve cluster usage efficiency. For example, we have updated many libraries tailored for computing cards, which may be released externally in the future.
Achievements
Based on this, Huanshuo’s AUM has grown from 5 billion in May 2015 to nearly 100 billion today. At the same time, Huanshuo has also established its own AI Lab, which is not only used for its trading but also hopes to utilize all computing power clusters and resources for some basic scientific research in the future, collaborating with universities and laboratories, etc.
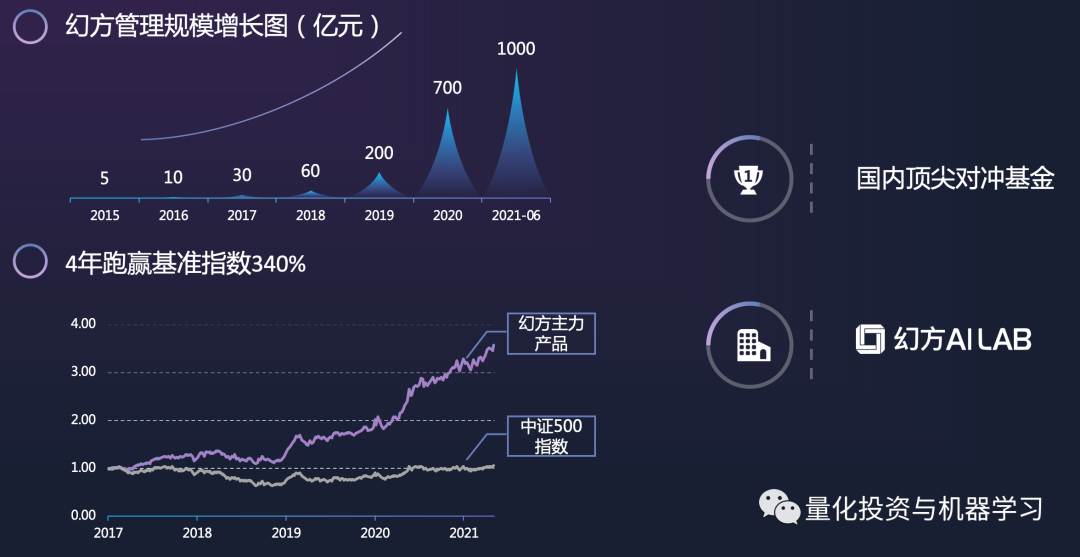 *Image from Huanshuo
*Image from Huanshuo
The Significance of Quantitative Investment for Financial Markets
-
Provides liquidity to the market, stabilizing market fluctuations
-
Enhances market efficiency, making company pricing more reasonable
-
Competes with top hedge funds globally
The WeChat public account for quantitative investment and machine learning is a mainstream self-media in the industry, vertical to quantitative investment, hedge funds, Fintech, artificial intelligence, big data, and other fields. The public account has more than 200,000+ followers, and has been selected as “Best Author of the Year” by Tencent Cloud + Community for two consecutive years.