 Produced by Big Data Digest
As a very important application in natural language processing, the modern concept of machine translation has evolved since it was proposed in the 1940s, undergoing several generations of innovation, and has now begun to be implemented in various scenarios. In recent years, with the improvement in machine translation quality, the momentum for machine translation to replace human translation has gradually grown. So, is machine translation a threat to human translators or a useful tool? To what extent can machine translation assist ordinary users?
Produced by Big Data Digest
As a very important application in natural language processing, the modern concept of machine translation has evolved since it was proposed in the 1940s, undergoing several generations of innovation, and has now begun to be implemented in various scenarios. In recent years, with the improvement in machine translation quality, the momentum for machine translation to replace human translation has gradually grown. So, is machine translation a threat to human translators or a useful tool? To what extent can machine translation assist ordinary users?
 In the sixth issue of AI Time, researchers including Zong Chengqing from the Institute of Automation, Chinese Academy of Sciences, Li Changshuan, Vice Dean of the School of Translation, Beijing Foreign Studies University, Zhang Min, Vice Dean of the School of Computer Science, Soochow University, Zhu Jingbo, Professor at Northeastern University, and Liu Yang, Associate Professor at the Department of Computer Science and Technology, Tsinghua University, discussed issues related to machine translation.
In the sixth issue of AI Time, researchers including Zong Chengqing from the Institute of Automation, Chinese Academy of Sciences, Li Changshuan, Vice Dean of the School of Translation, Beijing Foreign Studies University, Zhang Min, Vice Dean of the School of Computer Science, Soochow University, Zhu Jingbo, Professor at Northeastern University, and Liu Yang, Associate Professor at the Department of Computer Science and Technology, Tsinghua University, discussed issues related to machine translation.
History of Machine Translation
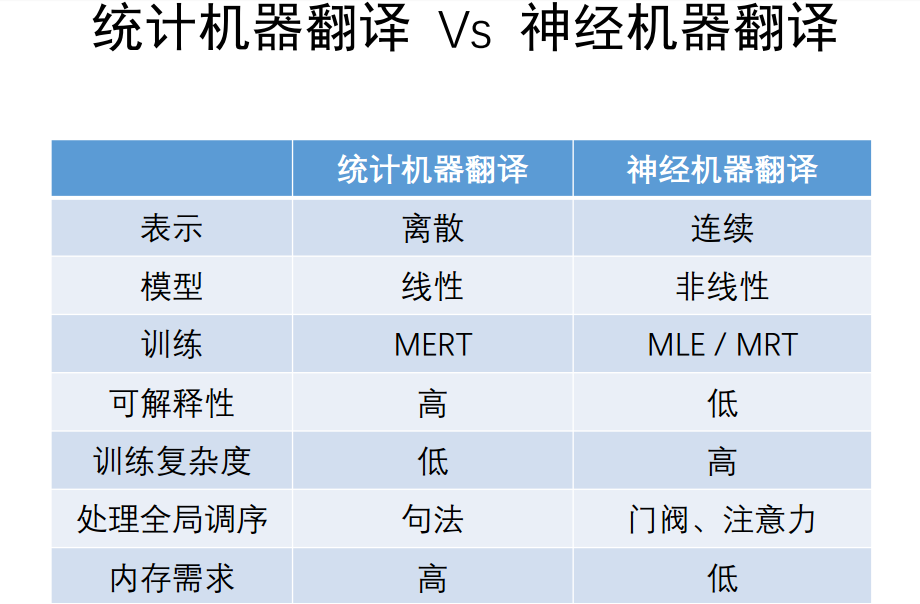
The history of machine translation can be roughly divided into two major phases. The first phase, from the 1960s to the early 1990s, was dominated by rationalist approaches, primarily involving human experts observing language patterns and describing them as rules for machines to follow in translation. The second phase began in the 1990s, especially after the advent of the Internet, where research into statistical machine translation gained momentum, driven by the availability of data and corresponding data-driven methods.
A classic statistical method model is the latent variable log-linear model, characterized by the need to design features where X represents input, Y represents output, and Z represents intermediate language structures. Various feature functions are defined to train a parameter, with much work focused on how to design good features to describe translation patterns.
However, language is too complex, and it is difficult to exhaustively design these features using human intelligence. One challenge is known as reordering. For example, in the phrase “a one-hour meeting was held on the Middle East situation,” this is a typical combination of prepositional and verbal phrases. In Chinese, the prepositional phrase is mentioned first, followed by the verbal phrase, but in English, it is the reverse.
After 2015, deep learning was applied in machine translation. The main significance of deep learning is that it can automatically extract representations from data, eliminating the need to design features to describe translation rules as before. One only needs to design a network that allows the machine to automatically find representations from data, which has shown excellent results. However, there are still difficult problems to solve; for instance, it fundamentally does not understand what numbers mean, does not know why it makes mistakes, does not know how to correct them, and is difficult to control.
The core technology currently is called the attention mechanism, which aims to automatically compute the correlation between Chinese and English. This is also a very core technology in deep learning. Now, some newer technologies can be utilized, such as transformers, which hope to handle longer sequences.
Machine Translation Aims to Fill Scenarios Where Humans Cannot
In recent years, a series of machine translation applications have emerged, such as translation devices and WeChat translation services. Machine translation largely serves to address communication issues between different countries and cultures. If machine translation can replace human translation to some extent and assist people, the communication channels will see a significant release. So, can machine translation truly replace humans?
Professor Zong Chengqing believes that the progress of machine translation in recent years has been substantial and can greatly improve translation efficiency. However, the use of machine translation needs to be based on specific scenarios and tasks. In certain situations, machine translation can indeed assist humans, such as asking for directions while traveling, but in certain fields, such as high-level translations, it is still too early to place too much hope on machine translation.
Professor Zhang Min agrees with Professor Zong’s viewpoint and adds that machine translation should be viewed from both academic and industrial perspectives. Academia can continue to pursue research, while in the industry, machine translation has already flourished, with strong demand for academic technology in the industry. The technology has reached the low-end threshold of the industry, and the industry drives technological development, which in turn serves the industry.
Professor Li Changshuan also believes that while machine translation has made remarkable progress, there will never be a day when it replaces humans. The main reason is that the quality of machine translation still does not meet professional translation requirements; it can understand individual sentences, but lacks overall logic.
Professor Zhu Jingbo agrees with the viewpoints of Professors Zong and Zhang, and gives an example: it is usually assumed that the results of translators are completely correct, while technology aims to exceed 100% accuracy to achieve 101%, which is fundamentally impossible.
However, the rapid development of machine translation after big data does not aim to replace humans. For instance, with millions of patent documents in national intellectual property, only machine translation can be utilized, as human translation is not feasible; similarly, while abroad, human translators may not always be available, necessitating the use of machine translation. This does not count as replacing human translation but rather fills the application scenarios where human translation cannot be performed.
Is It a Problem with Machine Translation or Is the Technology Not Mature Yet?
Professor Li Changshuan summarizes the main problems encountered in machine translation based on his experience:
When translating long Chinese sentences into English, they need to be broken down into several sentences. However, after breaking them apart, the latter sentences lack subjects, requiring the addition of subjects. It is unclear how machine translation supplements the subjects.
For example, “litigation procedures” may yield dozens of translation versions from machine translation. This issue should be solvable, but neural network translation seems to have not yet addressed it.
Machine translation relies on formal transformations, deciding on modification relationships based on probabilities when encountering ambiguities. The same applies to polysemy; even with a corpus, a word can have many meanings within the same professional field.
Professor Zhu Jingbo partially agrees with this:
First, the current sentence-level translation systems mainly stem from specific implementation mechanisms. In fact, there has been considerable academic research on discourse-level machine translation. Based on context analysis for subject omission and reference resolution, he prefers to view this as an understanding issue rather than a translation issue, but believes that combining both can achieve better translation results.
Secondly, some issues should be considered in two stages. For example, in cases of original text errors, humans can correct mistakes through understanding before translating. However, for machine translation, it assumes that this represents the user’s intended meaning and cannot easily modify the original text, leading to erroneous translations. This raises the question of whether machine translation performs better when integrated with other technologies.
Finally, the issues of polysemy and structural ambiguity are not being adequately addressed. It is not that machine translation lacks the ability to solve these, as the core of machine translation modeling is to tackle these two problems.
Professor Zong Chengqing points out that the fundamental assumption of current machine translation is that as long as enough samples are collected, it will suffice. However, this assumption is problematic. First, it is uncertain whether the model can learn effectively. Second, it should not be solely based on samples, but also on daily life experiences and common sense. Current models are not intelligent enough, and providing sufficient samples alone cannot lead to effective learning, which is why knowledge-based machine translation has been proposed.
Professor Zhang Min analyzes two major issues in machine translation from an academic perspective. First is the discourse issue; translation should be based on context understanding and logical analysis, but current machine translation modeling methods treat translation purely as a mathematical mapping at the sentence level. Therefore, deep learning methods can dramatically decline when faced with insufficient training data. Second is the need for knowledge and reasoning, which encompasses not only linguistic knowledge but also common sense, domain knowledge, and world knowledge.
Proposals for Pre-training and Background Supplementation
Professor Liu Yang gives an example of a high-level translator who spent a week riding the Paris metro to translate a thick subway manual, asking conductors for various information. A similar approach was taken for translating nuclear power documents, emphasizing that most of the effort in translation is spent on understanding background knowledge.
In contrast, current machine translation is still based on data and has not elevated to knowledge. Pre-training is a remarkably different idea, designing learning tasks related to questions on monolingual data, making the data nearly infinite, and then training models on top of that.
In the past year, pre-training methods have significantly improved performance in language processing tasks by 8-10 points. However, machine translation has not achieved such good results because the output of translation is not simply classification but an entire sequence. The complexity is very high as it involves outputting not just a word but also arranging the data and hierarchy.
The combination of pre-training and machine translation is a promising direction. If we can elevate it to a knowledge-based translation system, it would clearly be a better strategy. Currently, it is easy to think of combining knowledge graphs with machine translation, but there has been no breakthrough progress in this area.
Professor Li Changshuan also believes that professional translators spend most of their time researching materials. He gives an example: “A certain gentleman pointed out the issue of coastal islands in Somalia, and the liaison group encouraged legal action based on the practice of capture and release.” After reading it, it is incomprehensible; this is the result of machine translation.
In such cases, professional translators will consult relevant materials, understand the context, and then translate: “A certain individual pointed out that given the practice of capture and release in some countries, a certain group encourages the relevant countries to legislate to allow prosecution.” Translation is an ongoing process of investigation and understanding, with expression naturally formed based on comprehension.
At the same time, Professor Li Changshuan provides his thoughts on optimizing machine translation. The machine’s ability to supplement knowledge is an advantage; it has an endless supply of corpus. When translating a sentence, it can utilize hyperlinks and other means to provide relevant background, which will greatly facilitate the translation process.
Professor Zhu Jingbo lists three essential elements for a good machine translation system based on his experience. First, expand the scale of training data to improve quality; second, continuously innovate technology; third, refine based on problems. All three are indispensable. He expands the concept of machine translation technology to the equivalent transformation between two different objects, stating that machine translation is an industry, and machine translation+ is also an industry.
Professor Zong Chengqing believes that although there are many problems with machine translation now, there is no need for pessimism. From a research perspective, only by identifying problems can improvements be made, and problems represent room for progress.
The Breakthrough for Machine Translation Lies in Generating New Paradigms
Professor Zhu Jingbo believes that the future breakthrough in machine translation lies in forming a closed loop between industry, academia, and research, where application demands continuously drive theoretical and technological research in machine translation.
Professor Liu Yang states that innovation in paradigms is essential; it is crucial to find good strategies and methods to fully utilize unannotated data. Either the data can be well utilized, or knowledge can be extracted from unannotated data, both of which are critical.
Professor Li Changshuan believes that switching between Chinese and English remains challenging for machine translation, but in fields like news language, the quality of machine translation has already improved significantly. Future breakthroughs must return to changes in paradigms or thinking methods, capturing meanings from sentences and re-expressing them, which is the cognitive process humans use in translation, and future machine translation should follow this as well.
Professor Zong Chengqing adds that achieving high-quality machine translation results does not necessarily mean reaching the ultimate goal of faithfulness, expressiveness, and elegance, which is the ultimate goal of human translation. Currently, in certain scenarios, translation results are already quite good, but more detailed issues still need to be resolved. In a sense, the performance of current neural network machine translation has already approached its ceiling. Future improvements must focus on refining and enhancing translation models. From the perspective of technological application and industrial development, specific needs and tasks must be clarified, and targeted development should be conducted. This is a more feasible route to truly make the technology practical.
Professor Zhang Min states that machine translation is both a scientific and engineering problem. For future breakthroughs, scientific breakthroughs must originate from scientific technology, generating new paradigms; engineering breakthroughs must rely on knowledge, which requires collaboration across different fields and all of humanity to resolve.
AI Time was founded by a group of young people interested in the development of artificial intelligence, aiming to promote scientific and critical thinking. It invites individuals from various fields to explore the essential issues of artificial intelligence theories, algorithms, scenarios, and applications through debates and intellectual exchanges, creating a knowledge-sharing hub for artificial intelligence. Big Data Digest serves as a cooperative media partner for long-term reporting.
Interested parties can also click the link below to view content from the previous five issues:
-
Academician Zhang Bo from Tsinghua and Dean Wen Jirong from Renmin University Debate Passionately: The Human Love and Fear of AI
-
Should We Have a Powerful “Black Box” or “Explainable” Machine Learning?
-
Is the Construction of Knowledge Graphs Primarily Dependent on Humans or Machines?
Intern/Full-time Editor and Reporter Recruitment
Join us to experience every detail of reporting at a professional technology media outlet, growing alongside a group of the best talents from around the world in the most promising industry. Located in Beijing, at Tsinghua East Gate, reply “Recruitment” in the dialogue page of Big Data Digest’s homepage for more details. Please send your resume directly to [email protected]
Those who click “View” have all become more attractive!