Machine Heart (Overseas) Original
Author: Mos Zhang
Participated by: Panda
Machine Translation (MT) is the process of “automatically translating text from one natural language (source language) to another (target language)” using machines [1]. The idea of using machines for translation was first proposed by Warren Weaver in 1949. For a long time (from the 1950s to the 1980s), machine translation was done by studying the linguistic information of both the source and target languages, which was based on dictionaries and grammar, known as Rule-Based Machine Translation (RBMT). With the development of statistics, researchers began applying statistical models to machine translation, generating translation results based on the analysis of bilingual text corpora. This approach is known as Statistical Machine Translation (SMT), which outperformed RBMT and dominated the field between the 1980s and 2000s. In 1997, Ramon Neco and Mikel Forcada proposed the idea of using an “encoder-decoder” structure for machine translation [2]. A few years later, in 2003, a research team led by Yoshua Bengio at the University of Montreal developed a neural network-based language model [3], which improved the data sparsity problem of traditional SMT models. Their research laid the foundation for the future application of neural networks in machine translation.
The Birth of Neural Machine Translation
In 2013, Nal Kalchbrenner and Phil Blunsom proposed a new end-to-end encoder-decoder structure for machine translation [4]. This model can encode a given source text into a continuous vector using Convolutional Neural Networks (CNN), and then use Recurrent Neural Networks (RNN) as a decoder to convert that state vector into the target language. Their research results can be considered the birth of Neural Machine Translation (NMT); NMT is a method that uses deep learning neural networks to obtain mapping relationships between natural languages. The nonlinear mapping of NMT differs from the linear SMT model and uses the state vector connecting the encoder and decoder to describe semantic equivalence. In addition, RNNs should also be able to capture information behind infinitely long sentences, thus addressing the so-called “long distance reordering” problem [29]. However, the “gradient explosion/vanishing” problem [28] made it difficult for RNNs to handle long-distance dependencies; therefore, the performance of NMT models initially was not very good.
Memory for Long-Distance Problems
A year later, in 2014, Sutskever et al. and Cho et al. developed a method called sequence-to-sequence (seq2seq) learning, which can use RNNs for both the encoder and decoder [5][6], and also introduced Long Short-Term Memory (LSTM, a type of RNN) for NMT. With the help of a gate mechanism (allowing explicit memory to be deleted and updated in LSTM), the “gradient explosion/vanishing” problem was controlled, enabling the model to better capture “long-distance dependencies” in sentences.
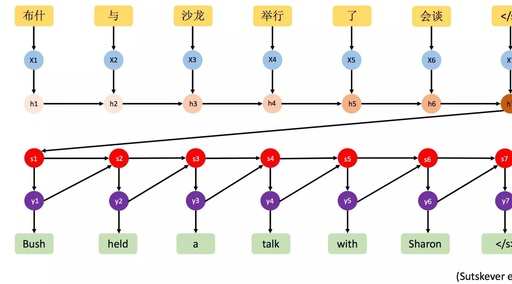
The introduction of LSTM addressed the “long distance reordering” problem, while transforming the main challenge of NMT into the “fixed-length vector” problem: as shown in Figure 1, regardless of the geometric length of the source sentence, this neural network needs to compress it into a fixed-length vector, which adds greater complexity and uncertainty during the decoding process, especially when the source sentence is long [6].
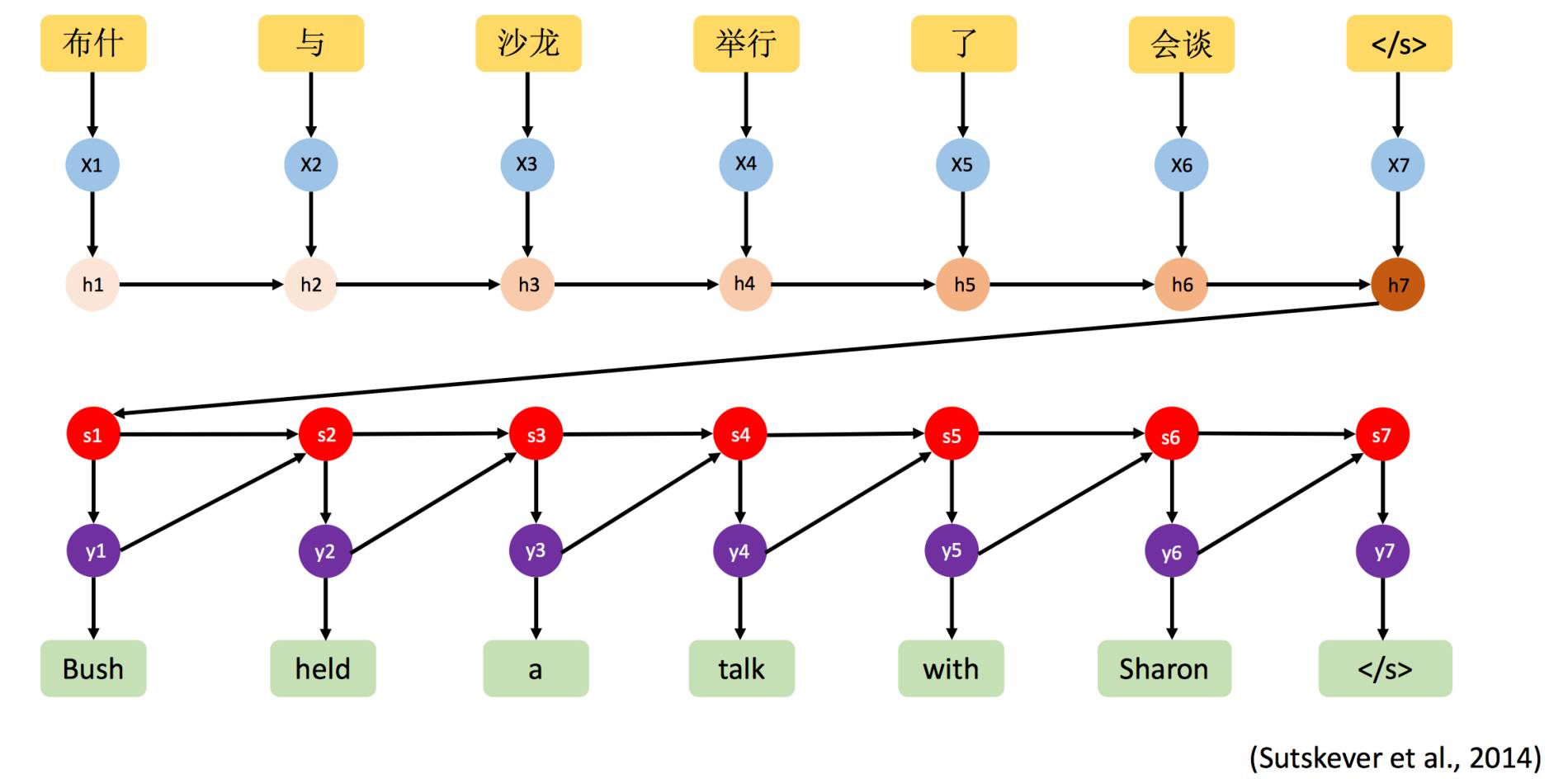
Figure 1: Original Neural Machine Translation Mechanism Without “Attention” [5]
Attention, Attention, Attention
Since Yoshua Bengio’s team introduced the “attention” mechanism for NMT in 2014 [7], the “fixed-length vector” problem began to be addressed. The attention mechanism was first proposed by DeepMind for image classification [23], allowing “neural networks to focus more on relevant parts of the input while paying less attention to irrelevant parts” [24] during prediction tasks. When the decoder generates a word to form the target sentence, only a small part of the source sentence is relevant; therefore, a content-based attention mechanism can be applied to dynamically generate a (weighted) context vector based on the source sentence (as shown in Figure 2, the transparency of the purple line indicates the weight size). The network then predicts words based on this context vector rather than a fixed-length vector. Since then, the performance of NMT has significantly improved, and the “attention encoder-decoder network” has become the current best model in the NMT field.
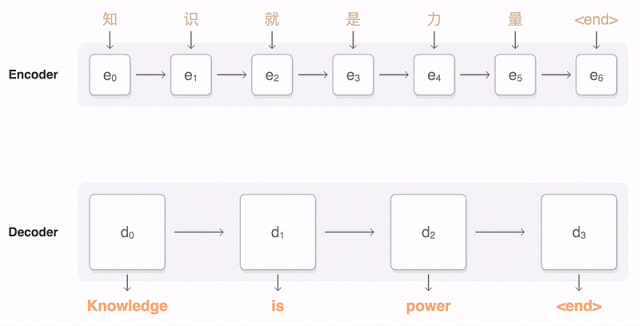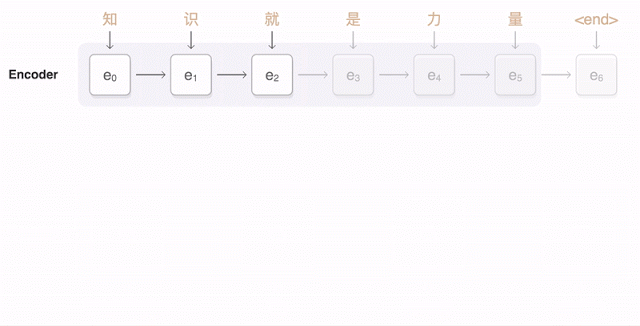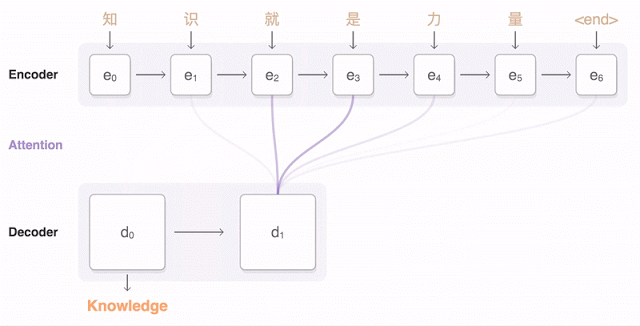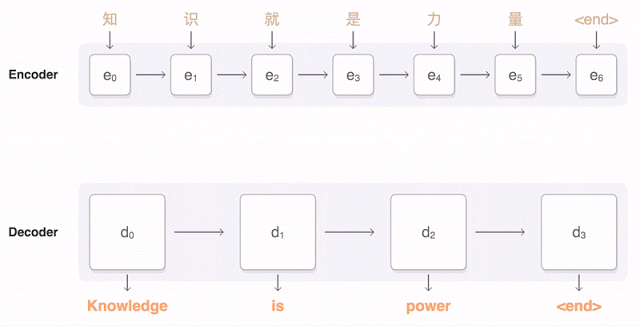
Figure 2: Mechanism of Google’s Neural Machine Translation (GNMT) [8] “Attention Encoder-Decoder Network” Architecture
NMT vs. SMT
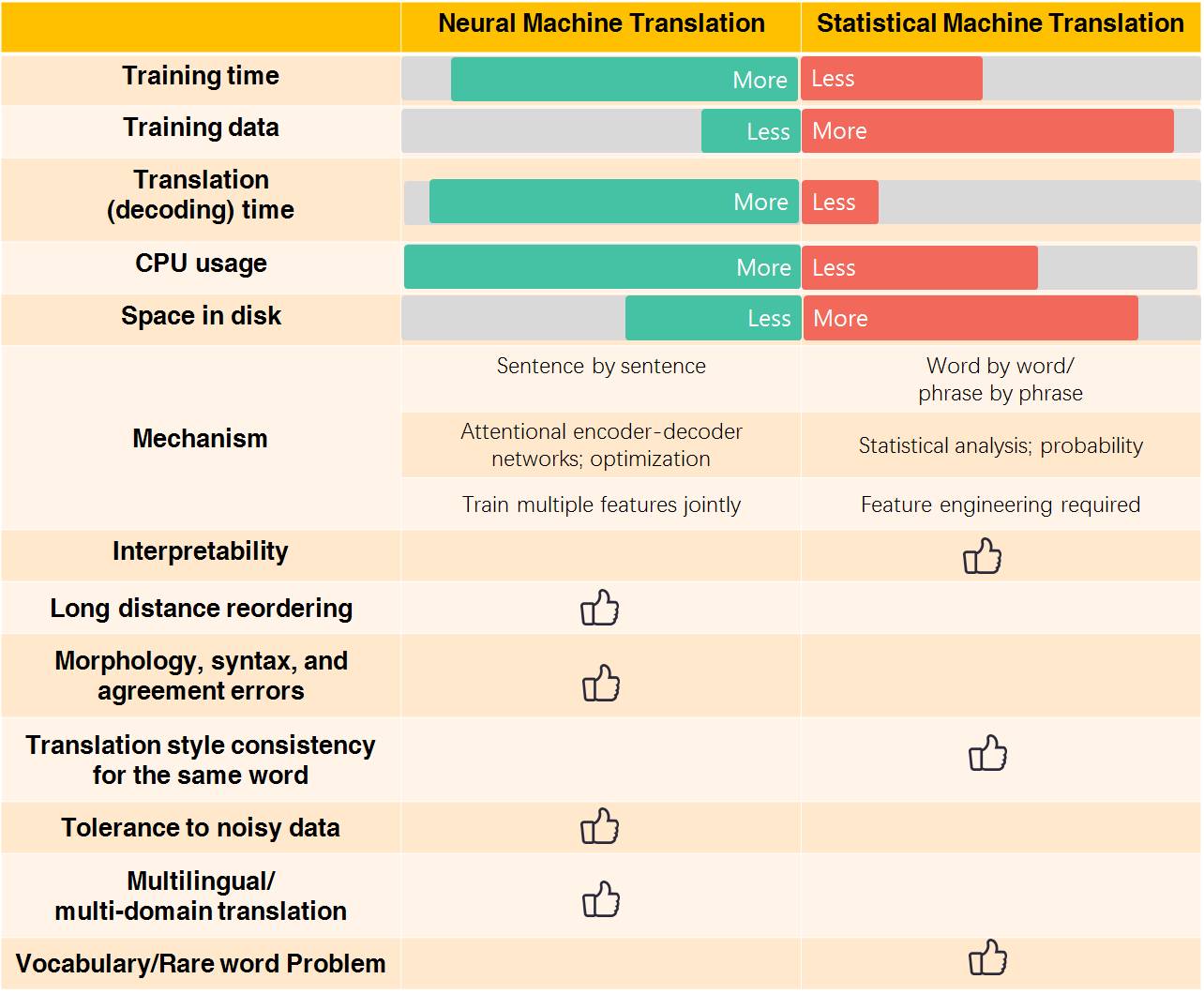
Although NMT has achieved remarkable results in specific translation experiments, researchers still wonder whether such excellent performance can be achieved in other tasks and whether NMT can indeed replace SMT. Therefore, Junczys-Dowmunt et al. conducted experiments on the “United Nations Parallel Corpus” which contains 15 language pairs and 30 translation directions; through BLEU scores (a method for automatically evaluating machine translation, the higher the score, the better [33]), NMT achieved comparable or better performance than SMT in all 30 translation directions. Additionally, at the 2015 Workshop on Statistical Machine Translation (WMT) competition, this team from the University of Montreal won first place in English-German translation and third place in German-English, Czech-English, and English-Czech translations [31].
Compared to SMT, NMT can jointly train multiple features without prior domain knowledge, enabling zero-shot translation [32]. In addition to higher BLEU scores and better sentence structures, NMT helps reduce common morphological, syntactic, and word order errors found in SMT. On the other hand, NMT also faces some unresolved issues and challenges: the training and decoding process is relatively slow; the translation style for the same word may be inconsistent; there is still the “out-of-vocabulary” problem in translation results; the interpretability of the “black box” neural network mechanism is poor; and most of the parameters used for training are selected empirically.
The Arms Race Has Begun
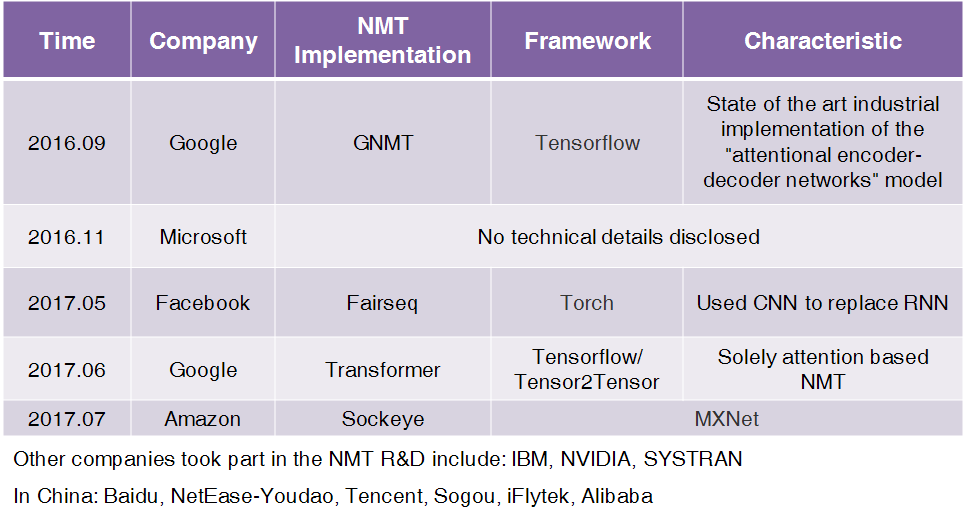
Due to the characteristics of NMT and its advantages over SMT, the industry has recently begun adopting NMT: In September 2016, the Google Brain team announced in a blog post that they had started using NMT to replace phrase-based machine translation (PBMT, a type of SMT) for the Chinese-English language pair in Google Translate. The NMT they deployed is called Google Neural Machine Translation (GNMT), and they also released a paper [9] at the same time detailing this model. Not long after (in 2017), Facebook’s AI Research (FAIR) announced their method of implementing NMT using CNN, achieving performance levels comparable to RNN-based NMT but at a speed 9 times faster [10][11]. In response, Google released a fully attention-based NMT model in June; this model did not use CNN or RNN but was entirely based on the attention mechanism [12].
Other tech giants are also making their moves. For example, Amazon just released their NMT implementation using MXNet in July [13]; Microsoft discussed their application of NMT in 2016, although further technical details have not yet been disclosed [27]. IBM Watson (a veteran in the field of machine translation), NVIDIA (a leader in AI computing), and SYSTRAN (a pioneer in machine translation) [35] have all been involved in the development of NMT to varying degrees. In East Asia, China, a rising star in the AI field, has many companies such as Baidu, Youdao, Tencent, Sogou, iFlytek, and Alibaba that have already deployed NMT. They are all striving to gain a competitive advantage in the next round of evolution in machine translation.
Is NMT the Future?
In a rapidly evolving and highly competitive environment, NMT technology is making significant progress. At the recent ACL 2017 conference, all 15 papers accepted in the machine translation category were related to neural machine translation [34]. We can see that NMT will continue to be improved in many aspects, including:
-
Rare word problem [14][15]
-
Usage of monolingual data [16][17]
-
Multilingual translation/multilingual NMT [18]
-
Memory mechanisms [19]
-
Language fusion [20]
-
Coverage issues [21]
-
Training process [22]
-
Integration of prior knowledge [25]
-
Multimodal translation [26]
Therefore, we have ample reason to believe that NMT will achieve even greater breakthroughs, gradually replacing SMT and developing into the mainstream machine translation technology, benefiting society in the near future.
Final Note
To help you understand the wonders of NMT, we have listed some open-source implementations of NMT that use different tools:
-
Tensorflow [Google-GNMT]: https://github.com/tensorflow/nmt
-
Torch [Facebook-fairseq]: https://github.com/facebookresearch/fairseq
-
MXNet [Amazon-Sockeye]: https://github.com/awslabs/sockeye
-
Theano [NEMATUS]: https://github.com/EdinburghNLP/nematus
-
Theano [THUMT]: https://github.com/thumt/THUMT
-
Torch [OpenNMT]: https://github.com/opennmt/opennmt
-
PyTorch [OpenNMT]: https://github.com/OpenNMT/OpenNMT-py
-
Matlab [StanfordNMT]: https://nlp.stanford.edu/projects/nmt/
-
DyNet-lamtram [CMU]: https://github.com/neubig/nmt-tips
-
EUREKA [MangoNMT]: https://github.com/jiajunzhangnlp/EUREKA-MangoNMT
If you are interested in further understanding NMT, we encourage you to read the papers listed in the references: [5][6][7] are essential core papers that can help you understand what NMT is; [9] provides a comprehensive display of the mechanisms and implementations of NMT. Additionally, machine translation is also an important chapter in the “Artificial Intelligence Technology Report” being compiled and edited by Machine Heart.
References
[1] Russell, S. & Norvig, P. (1995). Artificial intelligence: a modern approach.
[2] Neco, R. P., & Forcada, M. L. (1997, June). Asynchronous translations with recurrent neural nets. In Neural Networks, 1997., International Conference on (Vol. 4, pp. 2535-2540). IEEE.
[3] Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A neural probabilistic language model. Journal of machine learning research, 3(Feb), 1137-1155.
[4] Kalchbrenner, N., & Blunsom, P. (2013, October). Recurrent Continuous Translation Models. In EMNLP (Vol. 3, No. 39, p. 413).
[5] Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems(pp. 3104-3112).
[6] Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
[7] Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
[8] A Neural Network for Machine Translation, at Production Scale. (2017). Research Blog. Retrieved 26 July 2017, from https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
[9] Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., … & Klingner, J. (2016). Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144.
[10] Gehring, J., Auli, M., Grangier, D., & Dauphin, Y. N. (2016). A convolutional encoder model for neural machine translation. arXiv preprint arXiv:1611.02344.
[11] Gehring, J., Auli, M., Grangier, D., Yarats, D., & Dauphin, Y. N. (2017). Convolutional Sequence to Sequence Learning. arXiv preprint arXiv:1705.03122.
[12] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention Is All You Need. arXiv preprint arXiv:1706.03762.
[13] Train Neural Machine Translation Models with Sockeye | Amazon Web Services. (2017). Amazon Web Services. Retrieved 26 July 2017, from https://aws.amazon.com/blogs/ai/train-neural-machine-translation-models-with-sockeye/
[14] Jean, S., Cho, K., Memisevic, R., & Bengio, Y. (2014). On using very large target vocabulary for neural machine translation. arXiv preprint arXiv:1412.2007.
[15] Luong, M. T., Sutskever, I., Le, Q. V., Vinyals, O., & Zaremba, W. (2014). Addressing the rare word problem in neural machine translation. arXiv preprint arXiv:1410.8206.
[16] Sennrich, R., Haddow, B., & Birch, A. (2015). Improving neural machine translation models with monolingual data. arXiv preprint arXiv:1511.06709.
[17] Cheng, Y., Xu, W., He, Z., He, W., Wu, H., Sun, M., & Liu, Y. (2016). Semi-supervised learning for neural machine translation. arXiv preprint arXiv:1606.04596.
[18] Dong, D., Wu, H., He, W., Yu, D., & Wang, H. (2015). Multi-Task Learning for Multiple Language Translation. In ACL (1) (pp. 1723-1732).
[19] Wang, M., Lu, Z., Li, H., & Liu, Q. (2016). Memory-enhanced decoder for neural machine translation. arXiv preprint arXiv:1606.02003.
[20] Sennrich, R., & Haddow, B. (2016). Linguistic input features improve neural machine translation. arXiv preprint arXiv:1606.02892.
[21] Tu, Z., Lu, Z., Liu, Y., Liu, X., & Li, H. (2016). Modeling coverage for neural machine translation. arXiv preprint arXiv:1601.04811.
[22] Shen, S., Cheng, Y., He, Z., He, W., Wu, H., Sun, M., & Liu, Y. (2015). Minimum risk training for neural machine translation. arXiv preprint arXiv:1512.02433.
[23] Mnih, V., Heess, N., & Graves, A. (2014). Recurrent models of visual attention. In Advances in neural information processing systems (pp. 2204-2212).
[24] Dandekar, N. (2017). How does an attention mechanism work in deep learning for natural language processing?. Quora. Retrieved 26 July 2017, from https://www.quora.com/How-does-an-attention-mechanism-work-in-deep-learning-for-natural-language-processing
[25] Cohn, T., Hoang, C. D. V., Vymolova, E., Yao, K., Dyer, C., & Haffari, G. (2016). Incorporating structural alignment biases into an attentional neural translation model. arXiv preprint arXiv:1601.01085.
[26] Hitschler, J., Schamoni, S., & Riezler, S. (2016). Multimodal pivots for image caption translation. arXiv preprint arXiv:1601.03916.
[27] Microsoft Translator launching Neural Network based translations for all its speech languages. (2017). Translator. Retrieved 27 July 2017, from https://blogs.msdn.microsoft.com/translation/2016/11/15/microsoft-translator-launching-neural-network-based-translations-for-all-its-speech-languages/
[28] Pascanu, R., Mikolov, T., & Bengio, Y. (2013, February). On the difficulty of training recurrent neural networks. In International Conference on Machine Learning (pp. 1310-1318).
[29] Sudoh, K., Duh, K., Tsukada, H., Hirao, T., & Nagata, M. (2010, July). Divide and translate: improving long distance reordering in statistical machine translation. In Proceedings of the Joint Fifth Workshop on Statistical Machine Translation and MetricsMATR (pp. 418-427). Association for Computational Linguistics.
[30] Junczys-Dowmunt, M., Dwojak, T., & Hoang, H. (2016). Is neural machine translation ready for deployment. A case study on, 30.
[31] Bojar O, Chatterjee R, Federmann C, et al. Findings of the 2015 Workshop on Statistical Machine Translation[C]. Tech Workshop on Statistical Machine Translation, 2015.
[32] Johnson, M., Schuster, M., Le, Q. V., Krikun, M., Wu, Y., Chen, Z., … & Hughes, M. (2016). Google’s multilingual neural machine translation system: enabling zero-shot translation. arXiv preprint arXiv:1611.04558.
[33] Bartolome, Diego, and Gema Ramirez.「Beyond the Hype of Neural Machine Translation,」MIT Technology Review (May 23, 2016), bit.ly/2aG4bvR.
[34] ACL 2017. (2017). Accepted Papers, Demonstrations and TACL Articles for ACL 2017. [online] Available at: https://chairs-blog.acl2017.org/2017/04/05/accepted-papers-and-demonstrations/ [Accessed 7 Aug. 2017].
[35] Crego, J., Kim, J., Klein, G., Rebollo, A., Yang, K., Senellart, J., … & Enoue, S. (2016). SYSTRAN’s Pure Neural Machine Translation Systems. arXiv preprint arXiv:1610.05540.
Machine Heart English website article link: https://syncedreview.com/2017/08/17/history-and-frontier-of-the-neural-machine-translation/
This article is translated by Machine Heart, please contact this public account for authorization.
✄————————————————
Join Machine Heart (Full-time reporter/intern): [email protected]
Submit or seek coverage: [email protected]
Advertising & Business Cooperation: [email protected]