
Selected from arXiv
Authors: Guillaume Lample et al.
Translation by Machine Heart
Contributors: Zhang Qian, Lu
Recently, researchers from FAIR proposed two variants of machine translation models, one being a neural model and the other based on phrases. The researchers combined two recently proposed unsupervised methods, simplifying the structure and loss functions, resulting in a new model that performs better and is easier to train and tune.
Paper:Phrase-Based & Neural Unsupervised Machine Translation

Paper link: https://arxiv.org/pdf/1804.07755.pdf
Abstract:Machine translation systems have achieved near-human-level performance in certain languages, but their effectiveness largely depends on a large amount of bilingual text, which reduces the applicability of machine translation systems for most language pairs. This study explores how to perform machine translation with only large monolingual corpora. Both models utilize back-translation to automatically generate parallel corpora, leveraging the denoising effect of a reverse model running in the opposite direction and a language model trained on the target language side. These models significantly outperform methods in the literature while being simpler and having fewer hyperparameters. In the widely used WMT’14 English-French and WMT’16 German-English benchmark tests, our models achieved BLEU scores of 27.1 and 23.6, respectively, without using parallel sentences, surpassing the current best technology by 11 BLEU points.
Machine Translation (MT) has been a successful paradigm in the field of natural language processing in recent years. Its practical applications and function as a testing platform for sequence transduction algorithms have rekindled interest in this topic.
Despite recent advances indicating that translations for several language pairs using neural network methods have approached human-level performance (Wu et al., 2016; Hassan et al., 2018), other studies have revealed some public challenges (Koehn and Knowles, 2017; Isabelle et al., 2017; Sennrich, 2017). The existing learning algorithms’ dependence on large parallel corpora is one of them. Unfortunately, parallel corpora are scarce for the vast majority of language pairs: learning algorithms need to better leverage monolingual data to expand the applicability of MT.
A large body of literature has studied the issue of enhancing translation performance using monolingual data under limited supervision. This limited supervision typically takes the form of a small set of parallel sentences (Sennrich et al., 2015a; Gulcehre et al., 2015; He et al., 2016; Gu et al., 2018; Wang et al., 2018), a large set of parallel sentences using other related languages (Firat et al., 2016; Johnson et al., 2016; Chen et al., 2017; Zheng et al., 2017), bilingual dictionaries (Klementiev et al., 2012; Irvine and Callison-Burch, 2014, 2016), or comparable corpora (Munteanu et al., 2004; Irvine and Callison-Burch, 2013).
In contrast, recent researchers proposed two completely unsupervised methods (Lample et al., 2018; Artetxe et al., 2018), relying solely on monolingual corpora for each language, as in the pioneering work of Ravi and Knight (2011).
Although there are subtle technical differences between these two studies, we found several common factors contributing to their success. First, they carefully initialized the model using inferred bilingual dictionaries. Secondly, they utilized powerful language models by training sequence-to-sequence systems (Sutskever et al., 2014; Bahdanau et al., 2015) as denoising autoencoders (Vincent et al., 2008). Third, they transformed the unsupervised problem into a supervised one by automatically generating sentence pairs through back-translation (Sennrich et al., 2015a). The key to the back-translation process is maintaining two models, one translating from the source language to the target language, and the other vice versa. The former generates data for training the latter, and vice versa. The last common feature is that these models constrain the latent representations shared between the two languages produced by the encoder. By putting these pieces together, regardless of the input language, the encoder produces similar representations. The decoder is trained both as a language model and as a translator for noisy inputs, learning to produce increasingly better translations alongside the backward model (operating from target language to source language). This iterative process has yielded good results in a completely unsupervised environment; for instance, it achieved a BLEU score of ~15 in the WMT’14 English-French benchmark test.
This paper proposes a model that combines these two neural network methods, simplifying the structure and loss functions while adhering to the principles mentioned above. The resulting model outperforms previous methods and is easier to train and adjust. We then applied the same ideas and methods to traditional phrase-based statistical machine translation (PBSMT) systems (Koehn et al., 2003). It is well-known that when labeled data is scarce, PBSMT models perform better than neural models, as they only count occurrences, while neural models typically fit hundreds of millions of parameters to learn distributed representations, which can generalize better when data is abundant but easily overfit when data is scarce. Our improved PBSMT model is simple, interpretable, and fast to train, often achieving results similar to or better than NMT models. Our NMT model achieved an increase of about 10 BLEU points in widely used benchmarks, while the PBSMT model achieved an increase of about 12 BLEU points. This significantly raises the current optimal level in unsupervised environments.
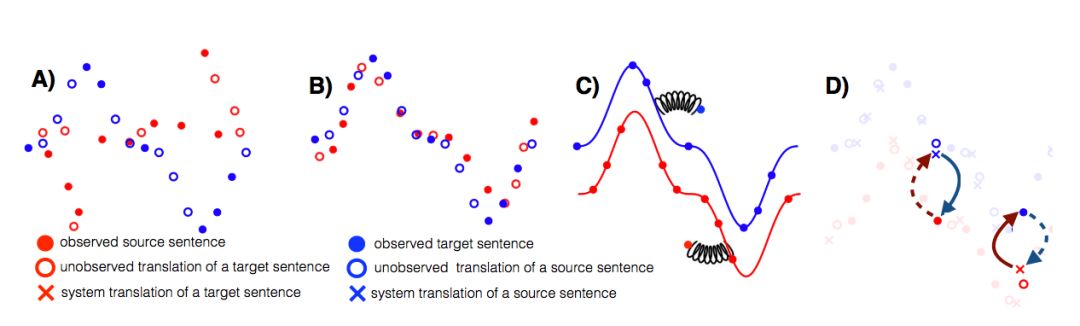
Figure 1: Illustration of the three principles of unsupervised MT.
A) Two monolingual datasets. Labels correspond to sentences (see legend for details). B) Principle One: Initialization. For example, these two distributions are roughly aligned by performing word-by-word translation using the inferred bilingual dictionary. C) Principle Two: Language Modeling. Independently learning language models in each domain to infer structure in the data (the continuous curves below); it acts as data-driven before denoising/correcting sentences (as shown, pulling sentences outside the curve back with springs). D) Principle Three: Back-Translation. Starting from observed source sentences (red solid circles), we use the current source→target model to translate (dashed arrow), producing potentially incorrect translations (blue crosses near hollow circles). From this (reverse) translation, we use the target→source model (solid arrow) to reconstruct the sentence in the original language. The differences between the reconstruction and the original sentences provide an error signal for training the target→source model parameters. The same steps are applied in the opposite direction to train the source→target model.

Algorithm 1: Unsupervised Machine Translation

Algorithm 2: Unsupervised PBSMT
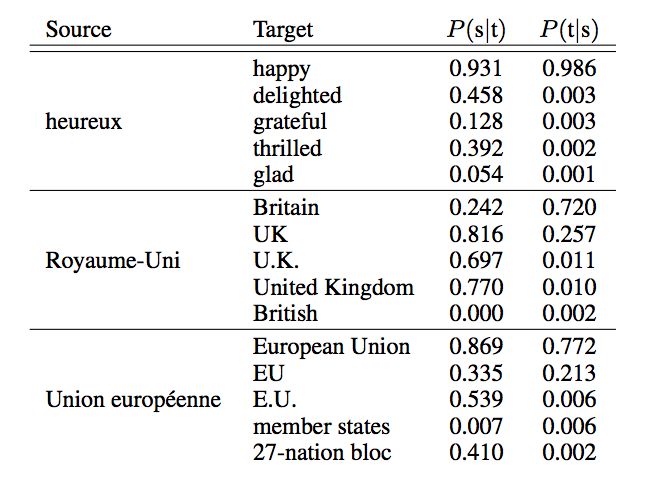
Table 1: Unsupervised Phrase Table. Examples of French to English translations of unigrams and bigrams, along with their corresponding conditional likelihoods P(s|t) and P(s|t).
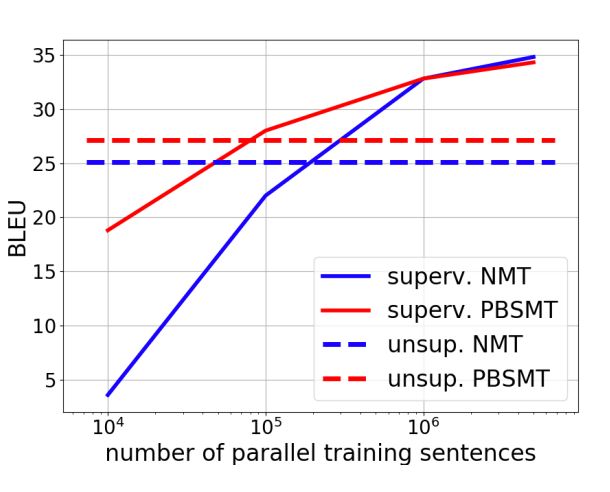
Figure 2: Comparison of supervised and unsupervised methods in WMT’14 English-French benchmark, varying the number of parallel sentences for supervised methods.
This article is compiled by Machine Heart, please contact this public account for authorization to reprint..
✄————————————————
Join Machine Heart (Full-time reporter/intern): [email protected]
Submissions or inquiries for coverage: [email protected]
Advertising & Business Cooperation: [email protected]