Click the “Expert Knowledge” above to follow and get professional AI knowledge!
▌Introduction
The traditional Vector Space Model (VSM) assumes that feature items are independent of each other, which does not align with reality. To address this issue, a distributed representation of text (e.g., in the form of word embeddings) can be employed, representing text as continuous, dense data similar to images and audio.
This allows us to transfer deep learning methods to the field of text classification. Text classification methods based on word vectors and Convolutional Neural Networks (CNNs) not only consider the correlation between words but also the relative positions of words in the text, which undoubtedly enhances accuracy in classification tasks. Experiments show that this method achieved an F1-score of 0.9372 on the validation dataset, representing a 20% improvement over the previously used classification methods in the business.
▌Business Background Description
-
Classification problems are very important and universally significant challenges faced by humanity. Many issues in our lives ultimately boil down to classification problems.
-
Text classification categorizes text content into appropriate classes and is a crucial problem in Natural Language Processing (NLP). It is mainly applied in tasks such as information retrieval, machine translation, automatic summarization, information filtering, and email classification.
▌Overview of Text Classification
-
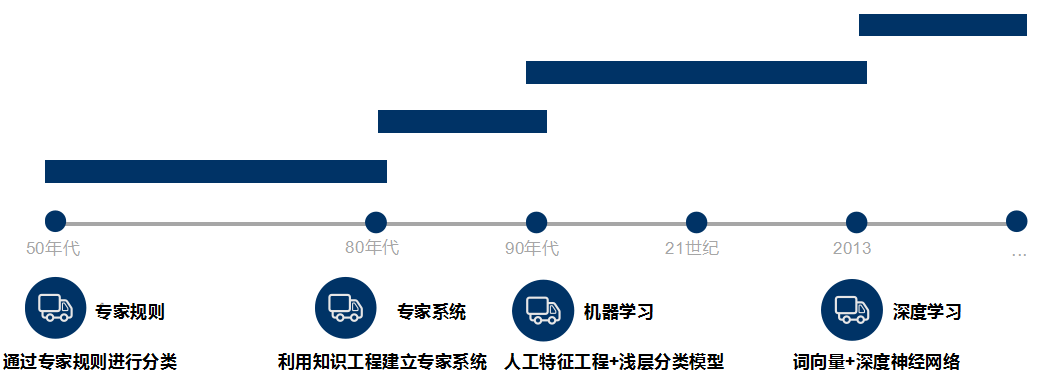
History of Text Classification
-
Text classification can be traced back to the 1950s when it primarily relied on expert-defined rules for classification.
-
In the 1980s, expert systems built using knowledge engineering emerged.
-
In the 1990s, machine learning methods began to be utilized for text classification, employing manual feature engineering and shallow classification models.
-
Currently, methods often use word vectors and deep neural networks for text classification.
-
Process of Text Classification
-
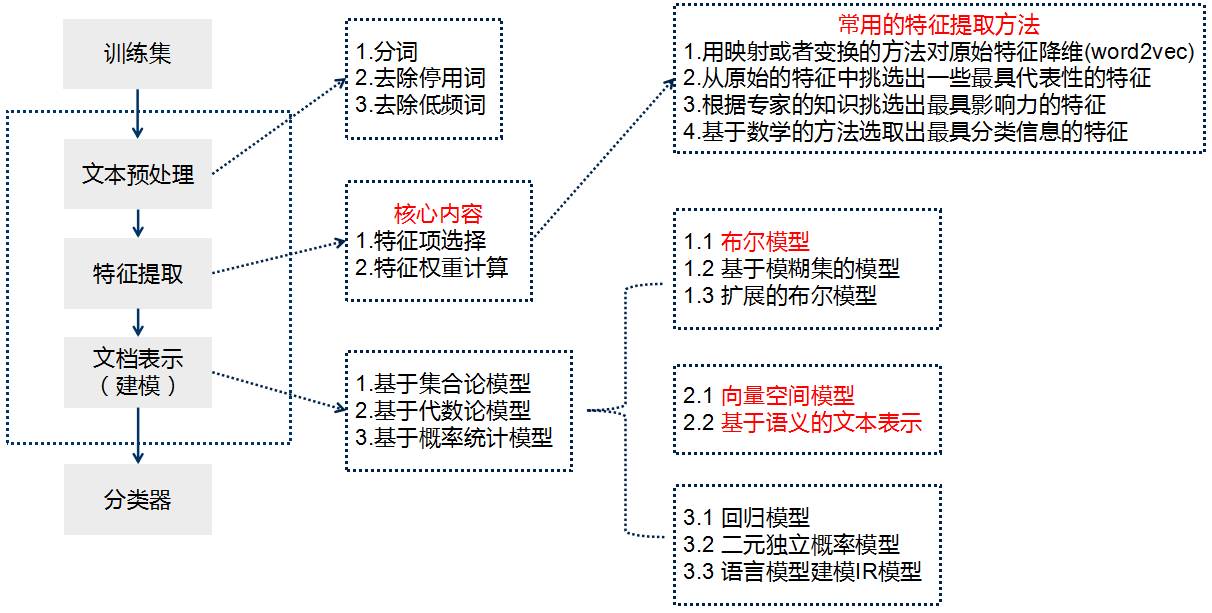
Document Representation
How to represent a document as structured data that algorithms can process is undoubtedly a vital step in text classification.
Based on the mathematical methods used in the text representation process, it can be categorized into the following types:
1. Set Theory Models: a. Boolean Model b. Fuzzy Set-Based Models c. Extended Boolean Models
2. Algebraic Models: a. Vector Space Model (VSM) b. Semantic Text Representation
3. Probabilistic Statistical Models: a. Regression Models b. Binary Independence Probability Models c. Language Modeling IR Models
Next, we will detail the Boolean Model, Vector Space Model (VSM), and Semantic Text Representation.
-
Boolean Model
The Boolean Model: Queries and documents are expressed as Boolean expressions, where documents are represented as an “AND” relationship among all words, similar to traditional database retrieval, which is precise matching.
For example:
Query: 2006 AND World Cup AND NOT Group Stage
Document 1: The 2006 World Cup was held in Germany
Document 2: The group stage of the 2006 World Cup has concluded
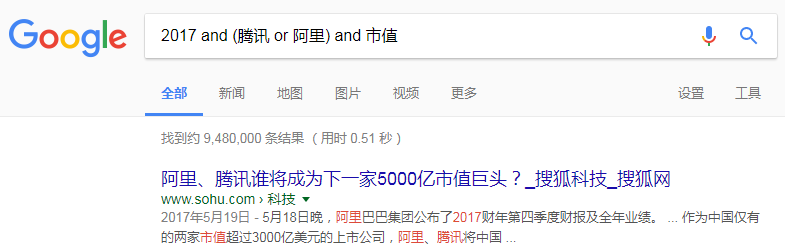
Document Similarity Calculation: Match the query Boolean expression with the Boolean expressions of all documents; a successful match scores 1, otherwise 0.
Advantages and Disadvantages of the Boolean Model:
Advantages: Simple, and the concept of the Boolean model is still included in modern search engines, such as the advanced search functions of Google and Baidu.
Disadvantages: It can only match strictly, and constructing queries can be challenging for ordinary users.
-
Vector Space Model
The Vector Space Model: Simplifies the processing of text content into vector calculations in a vector space. It expresses document similarity through spatial similarity.
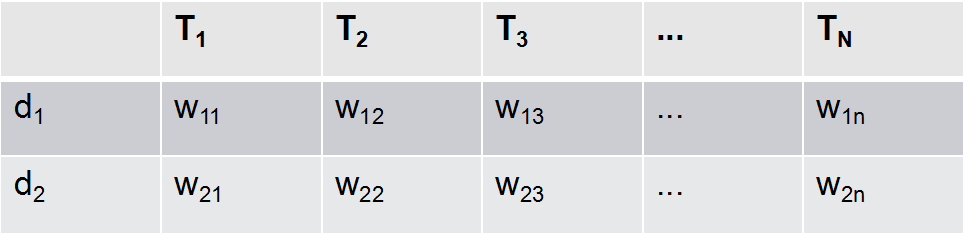
Each document is represented by a total of N feature items T1, T2, …, Tn, corresponding to weights Wi1, Wi2, …, Win. In this manner, each article is represented as an N-dimensional vector.
Similarity Calculation: The similarity between two documents can be measured by the cosine angle between the two vectors; the smaller the angle, the higher the similarity.
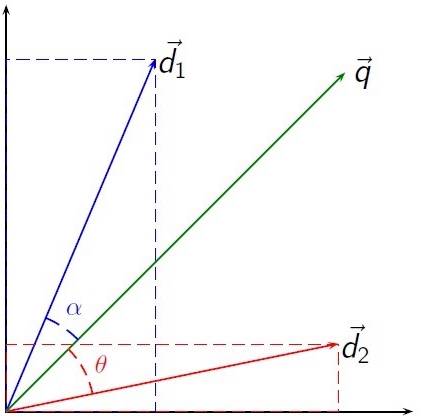
Advantages and Disadvantages:
Advantages: 1. Simple and intuitive, applicable in many fields (text classification, bioinformatics, etc.) 2. Supports partial and approximate matching, and results can be ranked 3. Good retrieval performance.
Disadvantages: 1. Theoretical support is insufficient, based on intuitive empirical formulas. 2. The assumption of independence among feature items does not hold true in practice. For instance, VSM assumes that the words “Xiao Ma Ge” and “Tencent” are independent, which is clearly not the case.

-
Semantic Text Representation
Semantic text representation methods: To address the unrealistic assumption of feature independence in VSM, some have proposed semantic text representation methods, such as LDA topic models and LSI/PLSI probabilistic latent semantic indexing. These methods are generally regarded as providing deeper representations of documents. The word embedding distributed representation method is a crucial foundation for deep learning methods.
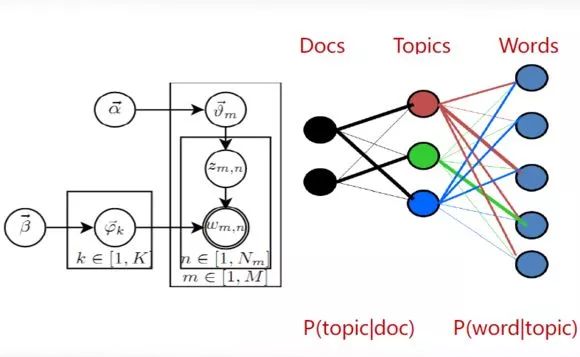
-
Distributed Representation of Text: Word Vectors (Word Embedding)
The basic idea of distributed representation of text (Distributed Representation) is to represent each word as a dense, continuous real-valued vector of n dimensions.
The greatest advantage of distributed representation is its powerful representational ability; for instance, an n-dimensional vector with k values can represent k to the power of n concepts.
In fact, both the hidden layers of neural networks and probabilistic topic models with multiple latent variables apply distributed representation. The neural network language model (NNLM) depicted below uses distributed text representation. The word vector (word embedding) is an additional product of training this language model, represented as Matrix C in the diagram.
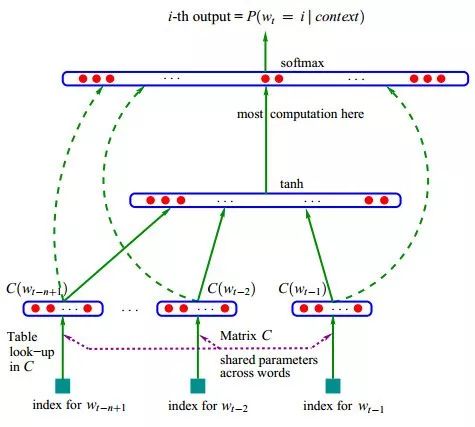
The neural network language model (NNLM)
Although distributed representation of words was proposed in 1986, it gained significant traction in 2013 when Google published two papers on word2vec, followed by the release of a simple word2vec toolkit, which validated it well in semantic dimensions and greatly advanced text analysis.
Text representation through word vector representation transforms text data from a high-dimensional sparse format that neural networks struggle to process into continuous dense data similar to images and language, allowing us to transfer deep learning algorithms to the text domain. The following image illustrates the two models, CBOW and Skip-gram, mentioned in Google’s word vector article.
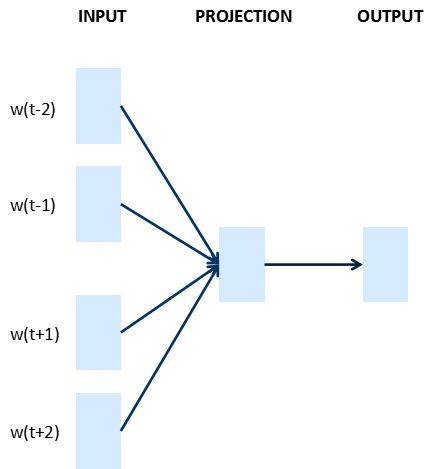
CBOW: Predicting the current word from context
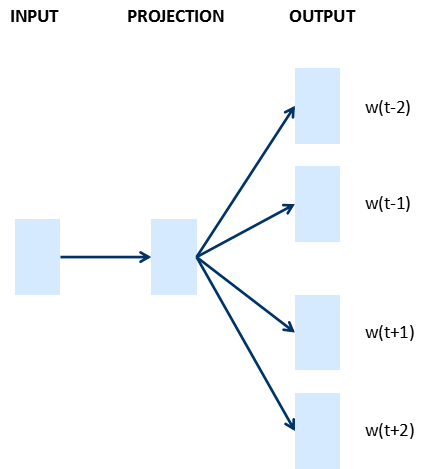
Skip-gram: Predicting context from the current word
-
Feature Extraction
Feature extraction corresponds to the selection of feature items and the calculation of feature weights.
The selection of feature items refers to independently scoring and ranking the original feature items (words) based on a certain evaluation metric, selecting the highest-scoring feature items and filtering out the rest.
The calculation of feature weights: The main idea is that the importance of a word is proportional to its frequency within the category (representativeness) and inversely proportional to its occurrence across all categories (discriminative power).
When selecting mathematical methods for feature extraction, the most crucial factor determining the effectiveness of text feature extraction is the quality of the evaluation function. Common evaluation functions include:
-
TF-IDF
TF: Term Frequency, calculates the ability of a word to describe the content of a document.
IDF: Inverse Document Frequency, measures the ability of a word to distinguish documents.
-
Idea: The importance of a word is proportional to its frequency within the category and inversely proportional to its occurrence across all categories.
-
Evaluation: a. The precision of TF-IDF is not particularly high. b. TF-IDF does not reflect the positional information of words.
-
Term Frequency (TF)
Term frequency is the number of times a word appears in a document. Using term frequency for feature selection means deleting words with frequencies below a certain threshold.
-
Idea: Words that occur infrequently have a minimal impact on filtering.
-
Evaluation: Sometimes, infrequent words contain more valuable information, so significant reductions in vocabulary are not advisable.
-
Document Frequency (DF)
It refers to how many texts in the entire dataset contain this word.
-
Idea: Calculate the document frequency of each feature and remove features with particularly low (non-representative) and particularly high frequencies (non-discriminative) based on a threshold.
-
Evaluation: Simple, low computational cost, fast, and has a linear relationship between time complexity and the number of texts, making it very suitable for feature selection in large-scale text datasets.
-
Mutual Information Method
Mutual information measures the statistical independence relationship between a word and a category, used to assess the discriminative power of features for the topic in filtering problems.
-
Idea: Words that appear frequently in a specific category but infrequently in other categories have a high mutual information with that category.
-
Evaluation: Advantages – No assumptions about the nature of the relationship between feature words and categories are needed. Disadvantages – Scores are easily influenced by the marginal probabilities of words. Experimental results show that mutual information often performs poorly in classification.
-
Expected Cross-Entropy
Cross-entropy reflects the distance between the probability distribution of text categories and the probability distribution of text categories given the presence of a specific word. The greater the cross-entropy of feature word t, the greater its impact on the distribution of text categories. Evaluation: The feature selection based on entropy does not consider the case where words do not occur, and performs better than information gain.
-
Information Gain
Information gain is an important concept in information theory, representing the impact of the presence or absence of a feature on category prediction.
-
Idea: The greater the information gain value of a feature, the greater its contribution and importance for classification.
-
Evaluation: Information gain often exhibits low classification performance because it considers the case where text features do not occur.
-
Chi-Square Test
It refers to how many texts in the entire dataset contain this word.
-
Idea: Terms that appear frequently in designated category texts compared to other category texts are very helpful in determining whether documents belong to that category.
-
Evaluation: The accuracy and classification performance of the chi-square test feature selection algorithm are less influenced by the training set, resulting in stable outcomes. It outperforms other classification methods when classifying texts with category crossover phenomena.
-
Other Evaluation Functions
-
Quadratic Information Entropy (QEMI)
-
Text Evidence Weight (The weight of Evidence for Text)
-
Odds Ratio
-
Genetic Algorithm
-
Principal Component Analysis (PCA)
-
Simulated Annealing Algorithm
-
N-Gram Algorithm
-
Summary of Traditional Feature Extraction Methods
Traditional feature selection methods mostly utilize the above feature evaluation functions for calculating feature weights.
However, since these evaluation functions are based on statistical principles, one drawback is that they require a large training set to obtain features that play a critical role in classification, which consumes significant human and material resources.
Furthermore, feature extraction methods based on evaluation functions are built on the assumption of feature independence, which is difficult to establish in practice.
-
Feature Extraction through Mapping and Transformation
Feature selection can also be achieved by transforming the original features into fewer new features using mapping or transformation methods. Traditional feature extraction dimensionality reduction methods may lose some document information; for instance, DF removes low-frequency words, which may contain significant information and be important for classification.
To address the shortcomings of traditional feature extraction methods: find similar high-frequency words for low-frequency words. For example, in a poem describing the moon, “Jade Rabbit” and “Charming” are low-frequency words; we can replace them with the high-frequency word “Moon,” which undoubtedly enhances the classification system’s depth of understanding of the text.Word vectors can effectively represent the similarity between words.
-
Traditional Text Classification Methods.
-
Basically, most machine learning methods have applications in the field of text classification.
-
For example: Naive Bayes, KNN, SVM, ensemble methods, maximum entropy, neural networks, etc.
-
Deep Learning Text Classification Methods
-
Convolutional Neural Networks (TextCNN)
-
Recurrent Neural Networks (TextRNN)
-
TextRNN+Attention
-
TextRCNN (TextRNN+CNN)
This article employs Convolutional Neural Networks (TextCNN).
▌Practice and Results
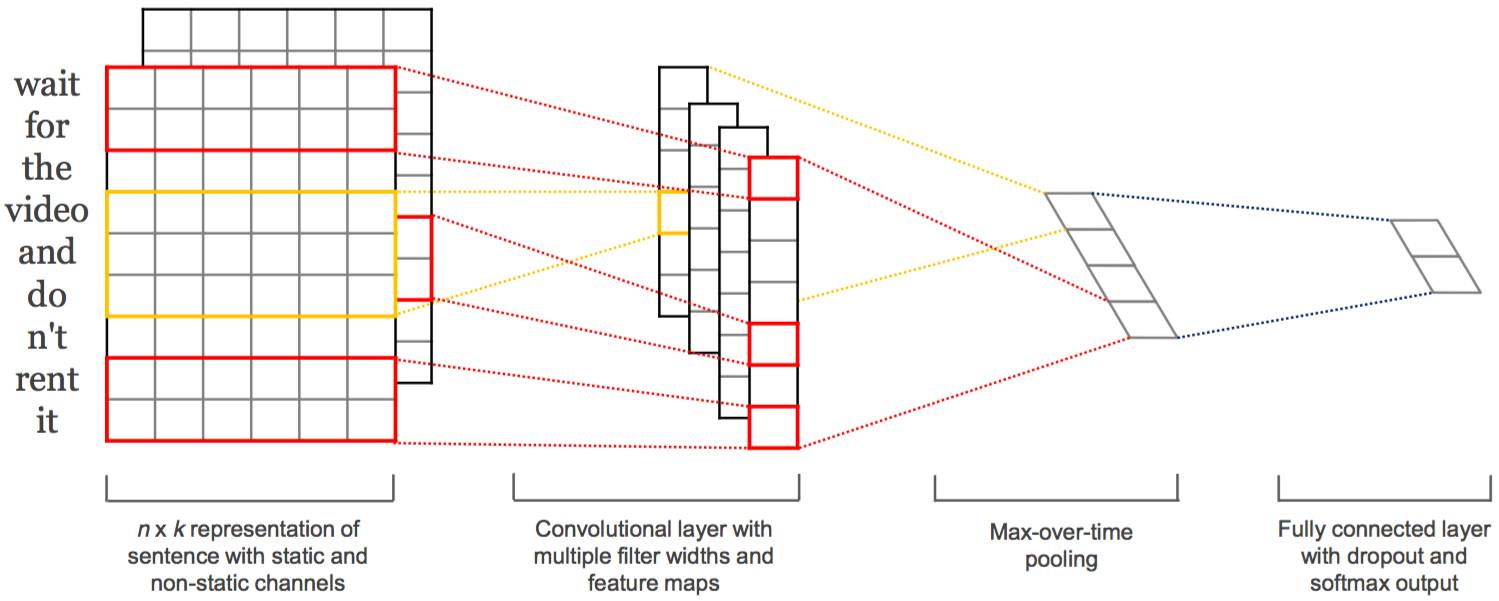
Overview of the TextCNN Network
-
Experiments and Steps
-
First, train the word vector model based on the details of the police case, vector.model
-
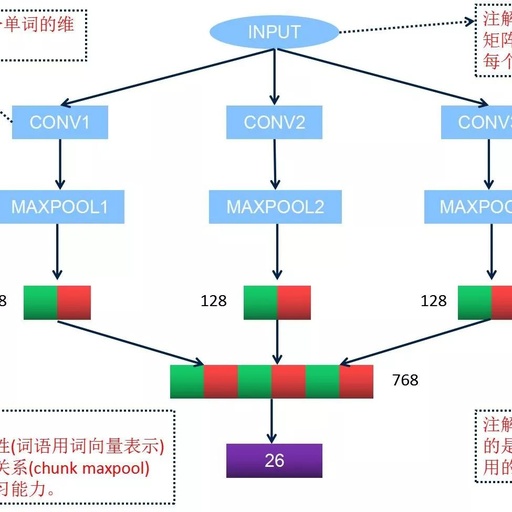
Tokenize the text of the police case details, remove stop words, and use word vectors to represent each document as a 250*200 matrix (250: number of words in the document, padded to 200 dimensions with -5.0 if insufficient, 200: each word is represented by a 200-dimensional vector).
-
Split the police training samples into train-set, validation set, and test set.
-
Train and test using the designed convolutional neural network.
-
Designed Convolutional Neural Network Structure
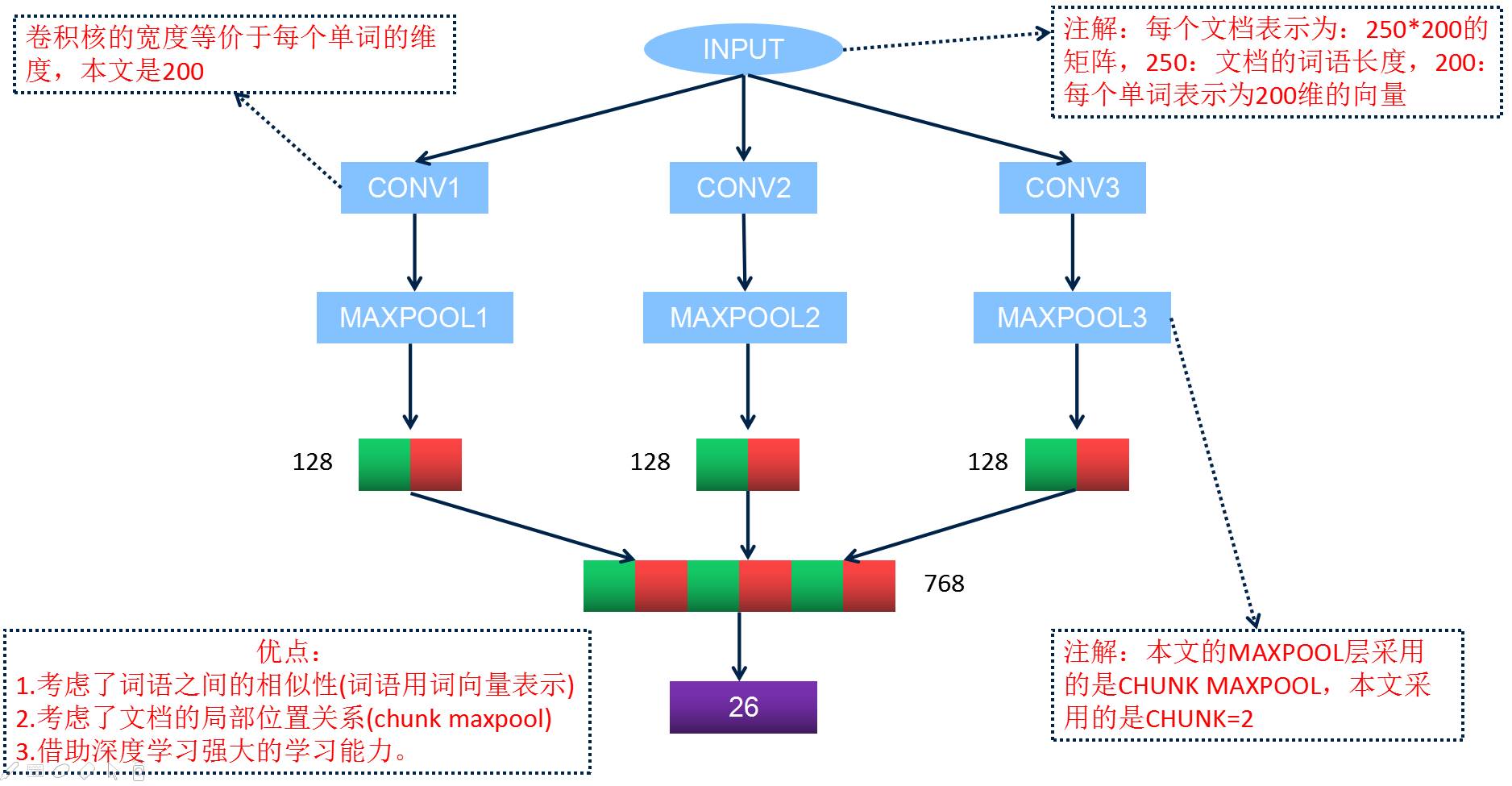
-
Experimental Results
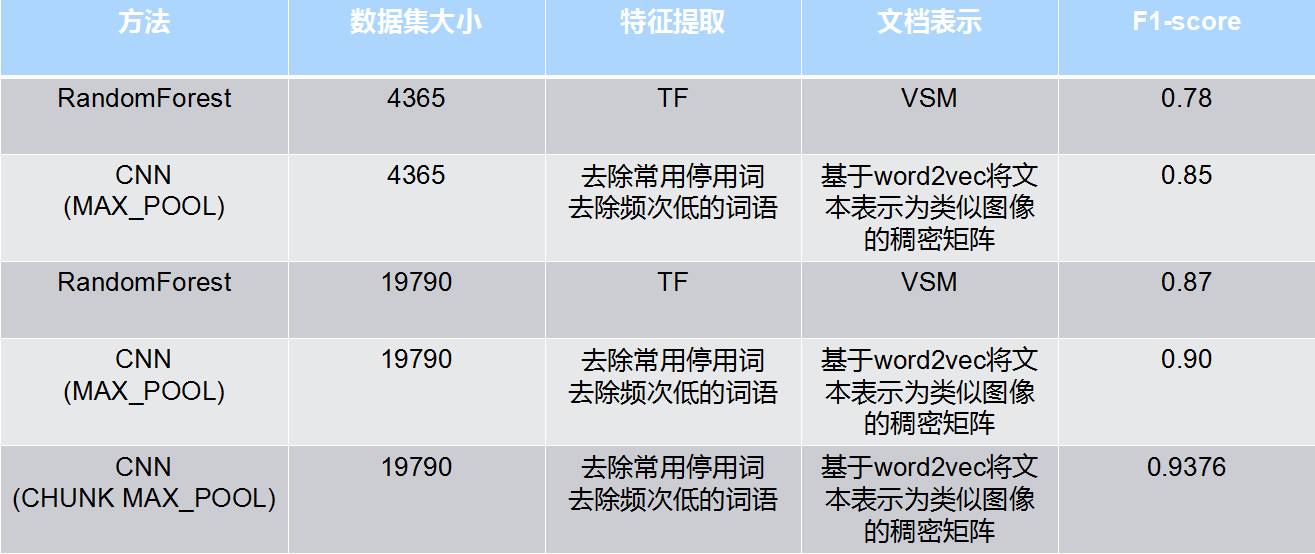
To verify the model’s classification accuracy on real data, we additionally manually reviewed 1000 case data from Shenzhen, which improved the classification accuracy from the original 68% to 90%, indicating that our model is indeed effective and shows significant improvement over the previous model.
-
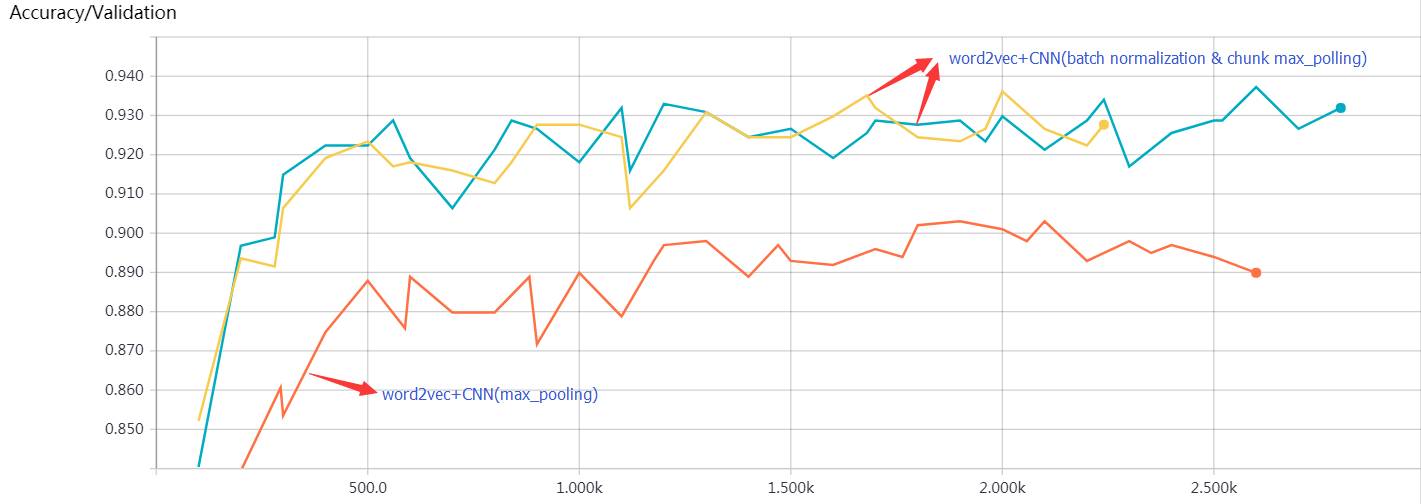
Red: The accuracy trend of word2vec+CNN (max_pooling) on the validation set
-
Yellow and Blue: The accuracy trend of word2vec+CNN (batch normalization & chunk max_pooling: 2 chunk) on the validation set
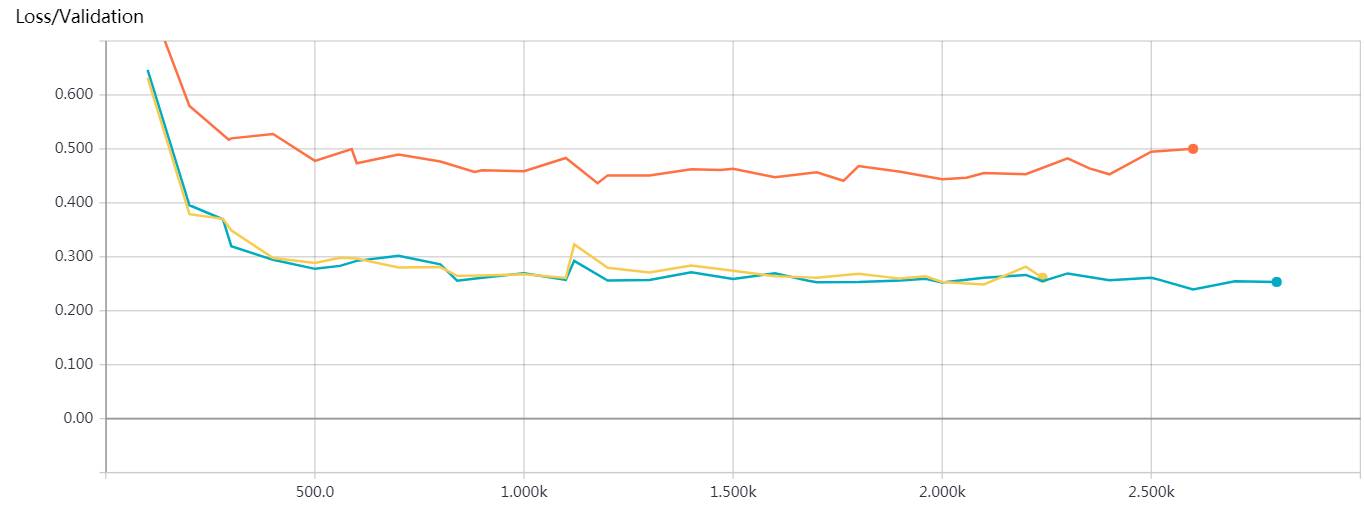
Red: The Loss trend of word2vec+CNN (max_pooling) on the validation set; Yellow and Blue: The Loss trend of word2vec+CNN (batch normalization & chunk max_pooling: 2 chunk) on the validation set.
-
Some Insights
-
Understand your data thoroughly.
-
Keep good records and analyses of experiments.
-
A large number of data samples are more effective than improving the model, but they are costly.
-
Read papers, understand principles, broaden your horizons, strengthen practice, dare to try, and pursue excellence.
Some References
-
CSDN – CNN Text Classification Based on TensorFlow
-
CSDN – Application of Deep Learning in Text Classification
-
Zhihu – Using Deep Learning to Solve Large-Scale Text Classification Problems – Overview and Practice
-
Jianshu – Implementing Convolutional Neural Networks for Text Classification Using TensorFlow
-
CSDN – Automatically Generating Semantically Similar Sentences Using Word Embedding
-
Github – Implementing a CNN for Text Classification in TensorFlow
-
Application of Convolutional Neural Networks in Sentence Modeling
-
CSDN – Common Max-Pooling Operations in CNN Models for Natural Language Processing
-
WILDML – Understanding Convolutional Neural Networks for NLP
-
Blog Garden – Deep Representation Models for Text – Word2Vec & Doc2Vec Word Vector Models
-
CSDN – Comparing Document Similarity Using Docsim/Doc2Vec/LSH
-
Deeplearning Chinese Forum – Natural Language Processing (III) – Word Embedding
-
CSDN – Learning DeepNLP, The Origins of Word Embedding – Deep Learning
-
CSDN – Writing Word2Vec by Yourself
This article is reproduced from: https://www.qcloud.com/community/article/931071
Welcome to view the complete collection of knowledge resources on computer vision by Expert Knowledge (follow this public account – Expert Knowledge, to obtain the download link):
[Expert Knowledge Collection 02] Natural Language Processing NLP Knowledge Resource Collection (Beginner/Advanced/Papers/Toolkit/Data/Overview/Experts, etc.) (PDF download attached)
-END-
Expert Knowledge
Please log in to www.zhuanzhi.ai on PC or click to read the original text, register and log in to Expert Knowledge to obtain AI knowledge resources!!
Please follow our public account to obtain professional knowledge in artificial intelligence. Scan the QR code to follow our WeChat public account.
