
Technical Column

Author: Yang Hangfeng
Editor: Zhang Nimei
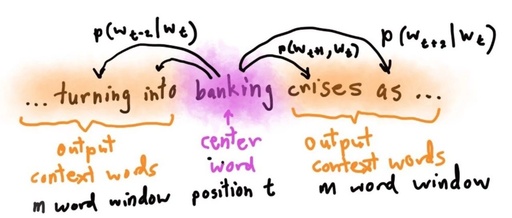
1.Word2Vec Overview
Word2Vec is simply a method of representing the semantic information of words through learning from text and using word vectors, that is, mapping the original word space to a new space through Embedding, so that semantically similar words are close to each other in this space.
Based on traditional neural networks, the neural probabilistic language model suffers mainly from excessive computational load, particularly in the matrix operations between the hidden layer and the output layer, as well as the Softmax normalization operations on the output layer.
Thus, 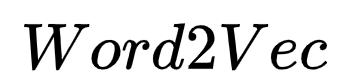 is designed to optimize the neural probabilistic language model for these two issues. The two important models in
is designed to optimize the neural probabilistic language model for these two issues. The two important models in 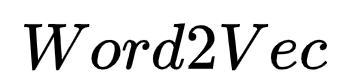 are CBOW model and Skip-gram model. For these two models,
are CBOW model and Skip-gram model. For these two models, 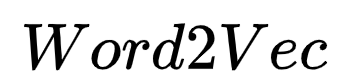 provides two frameworks based on Hierarchical Softmax and Negative Sampling for design, and this article focuses on the first type.
provides two frameworks based on Hierarchical Softmax and Negative Sampling for design, and this article focuses on the first type.
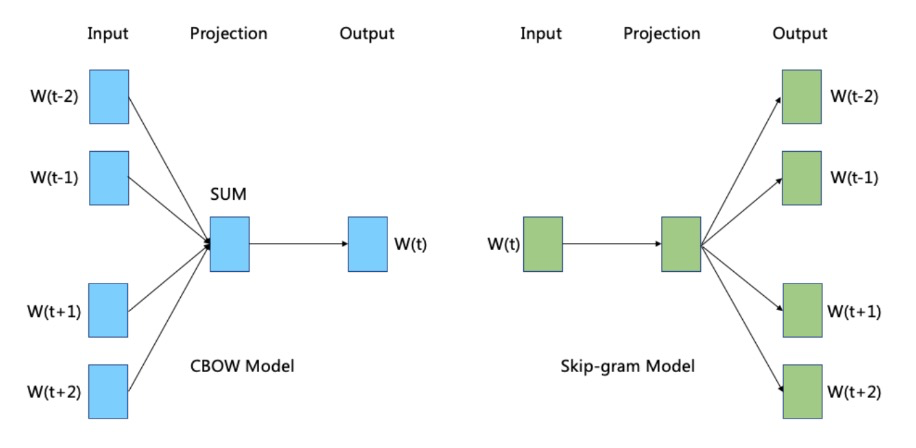
2.CBOW Model
2.1 Network Structure Based on Hierarchical Softmax
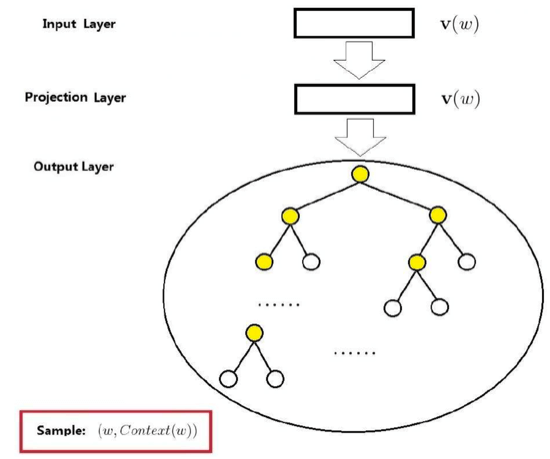
CBOW stands for Continuous bag-of-words, which includes three layers: input layer, projection layer, and output layer.
1.Input Layer: contains the word vectors of 2c words in Context(w)
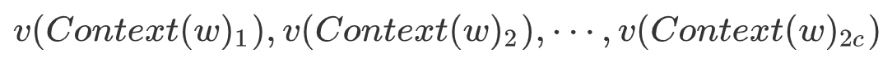 where n represents the length of the word vector.
where n represents the length of the word vector.
2.Projection Layer: sums the 2c vectors from the input layer.
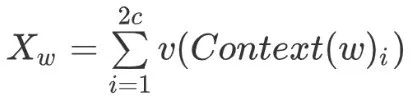
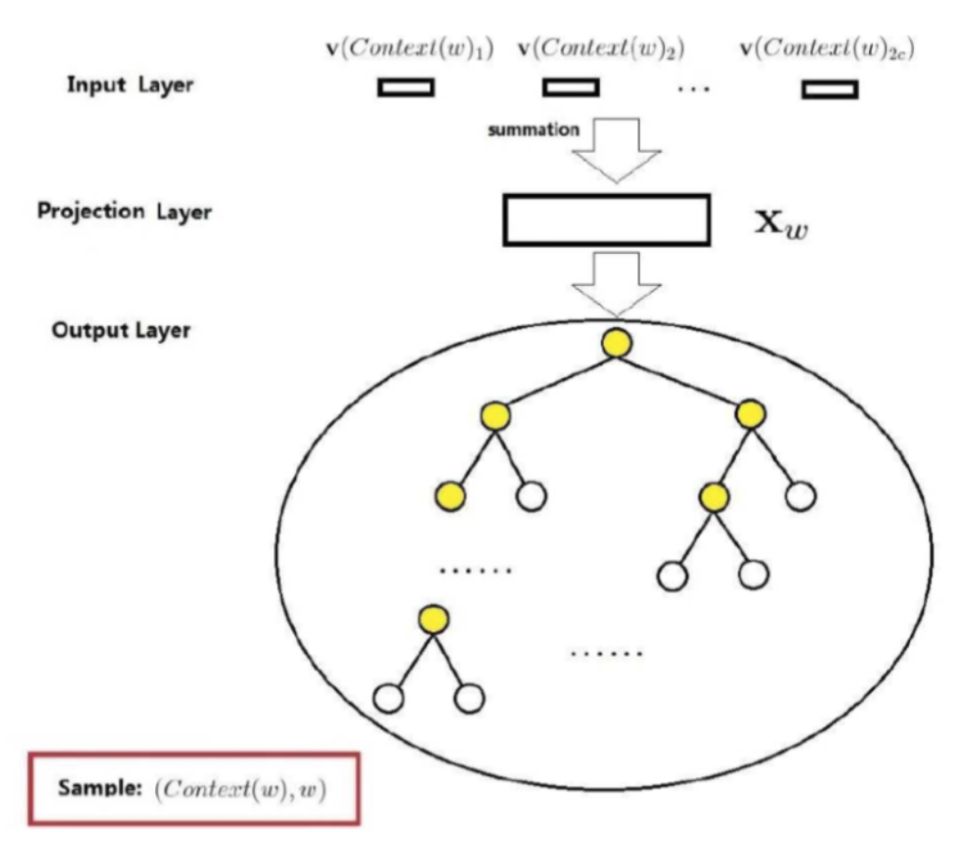
3.Output Layer: corresponds to a 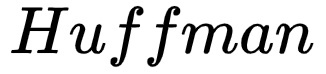 tree, which is constructed with the words appearing in the corpus as leaf nodes and their occurrence counts in the corpus as weights. In this
tree, which is constructed with the words appearing in the corpus as leaf nodes and their occurrence counts in the corpus as weights. In this 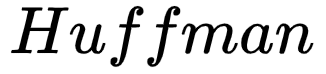 tree, there are N(=|D|) leaf nodes corresponding to the words in the dictionary D, and N-1 non-leaf nodes (the yellow nodes in the figure).
tree, there are N(=|D|) leaf nodes corresponding to the words in the dictionary D, and N-1 non-leaf nodes (the yellow nodes in the figure).
2.2 Gradient Calculation
To facilitate the description of the problem later, we first provide a unified explanation of the symbols used in the  model:
model:
-
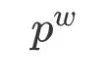 : the path from the root node to the corresponding leaf node
: the path from the root node to the corresponding leaf node  ;
; -
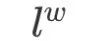 : the path from the root node to the corresponding leaf node
: the path from the root node to the corresponding leaf node 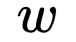 ;
; -
 : the path
: the path 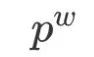 containing
containing 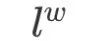 nodes, where
nodes, where 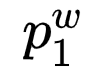 represents the root node, and
represents the root node, and 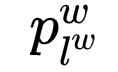 represents the word
represents the word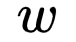 corresponding node;
corresponding node; -
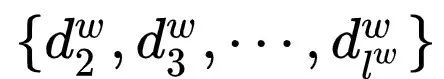 , where
, where 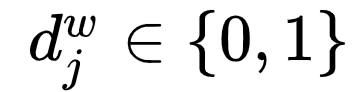 : the word
: the word 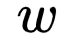 corresponds to a
corresponds to a  encoding, which consists of
encoding, which consists of 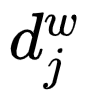 bits encoding, where
bits encoding, where 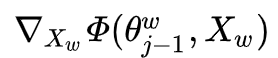 represents the encoding of the node corresponding to the
represents the encoding of the node corresponding to the 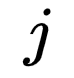 node in the
node in the 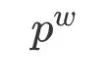 path (the root node does not correspond to an encoding);
path (the root node does not correspond to an encoding); -
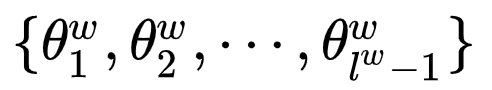 where represents the vector corresponding to the non-leaf node in the path
where represents the vector corresponding to the non-leaf node in the path 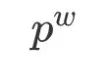 .
.
Thus, the idea of  is that for any word in the dictionary
is that for any word in the dictionary  , there must be a unique path from the root node to the corresponding leaf node in the tree. This path has
, there must be a unique path from the root node to the corresponding leaf node in the tree. This path has 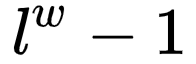 branches, and each branch can be seen as a binary classification, so each classification corresponds to a probability. Finally, multiplying these probabilities together gives
branches, and each branch can be seen as a binary classification, so each classification corresponds to a probability. Finally, multiplying these probabilities together gives  .
.
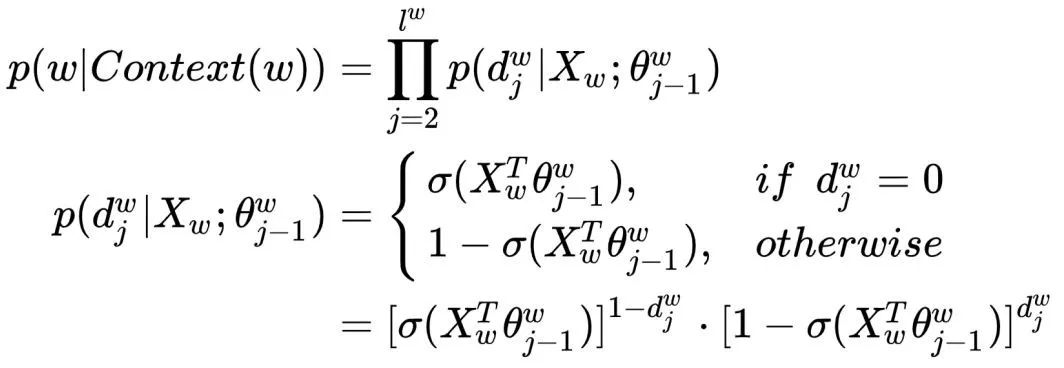
Where 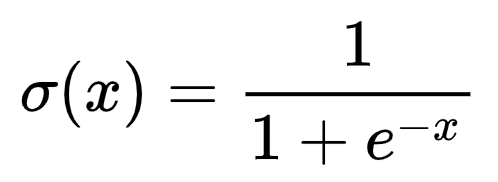 , through log-likelihood maximization, the objective function of the
, through log-likelihood maximization, the objective function of the 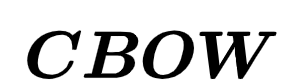 model is:
model is:
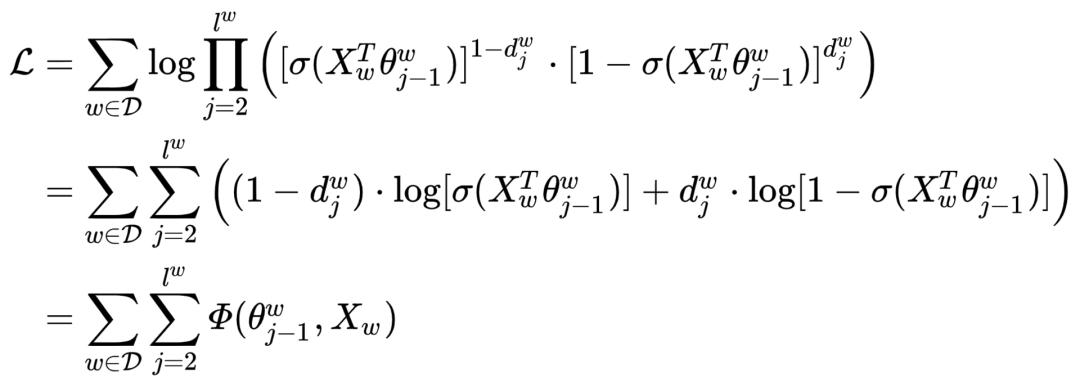
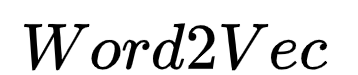 The algorithm used to maximize the objective function is Stochastic Gradient Ascent. First, consider the gradient calculation of
The algorithm used to maximize the objective function is Stochastic Gradient Ascent. First, consider the gradient calculation of  with respect to
with respect to 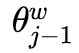 :
:
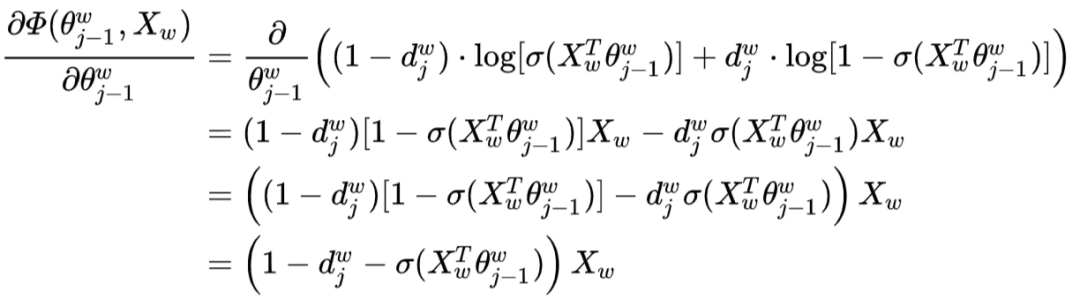
Therefore, the update formula for 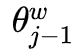 is:
is:
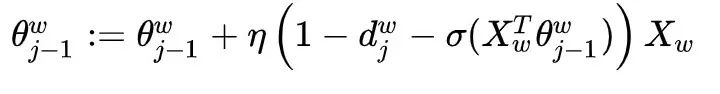
Next, consider the gradient calculation of 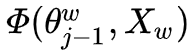 with respect to
with respect to 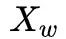 :
:
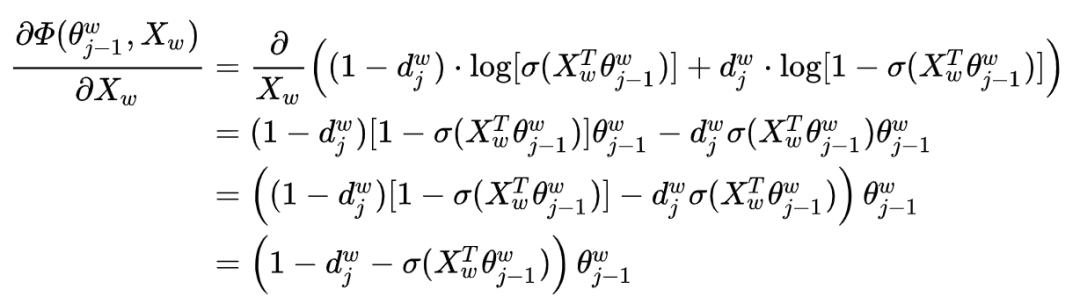
If we observe that 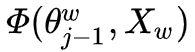 and
and 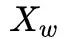 have symmetry, then it would be easier to calculate the corresponding gradient. Since
have symmetry, then it would be easier to calculate the corresponding gradient. Since 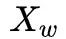 represents the sum of all word vectors in
represents the sum of all word vectors in 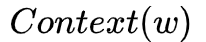 , how to update each component
, how to update each component 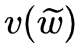 ? The approach is very straightforward, simply taking
? The approach is very straightforward, simply taking
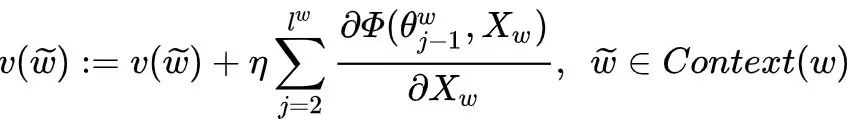
2.3 CBOW Model Update Pseudocode
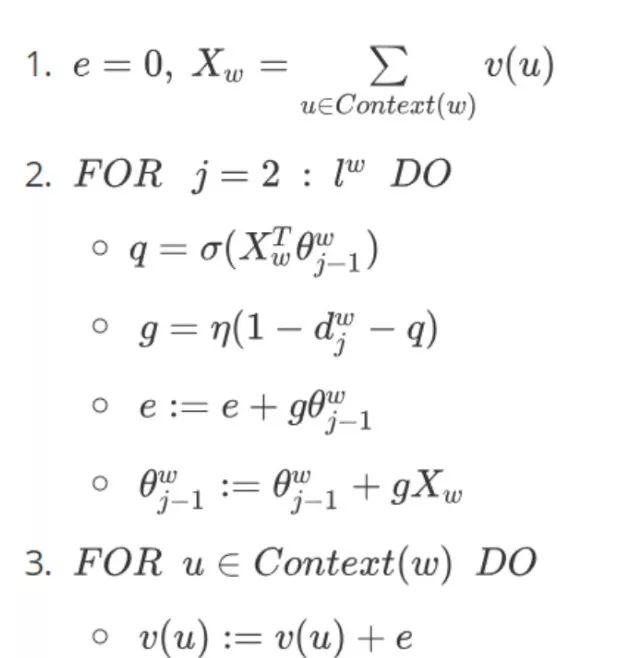
3.Skip-gram Model
3.1 Network Structure Based on Hierarchical Softmax
Similar to  model, the
model, the  model also includes three layers: input layer, projection layer, and output layer:
model also includes three layers: input layer, projection layer, and output layer:
-
Input Layer: contains only the word vector of the center word
 for the current sample
for the current sample .
. -
Projection Layer: This layer is an identity projection, which can actually be optional. It is just for convenience and comparison with the
 model’s network structure.
model’s network structure.
3.Output Layer: Like the  model, the output layer is also a
model, the output layer is also a 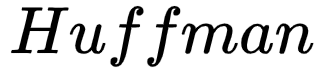 tree.
tree.
3.2 Gradient Calculation
For the 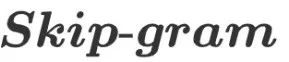 model, it is known that the current word
model, it is known that the current word 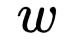 needs to predict the words in its context
needs to predict the words in its context 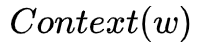 . Therefore, the key is to construct the conditional probability function
. Therefore, the key is to construct the conditional probability function 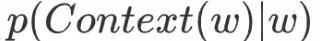 . In the
. In the  model, it is defined as:
model, it is defined as:
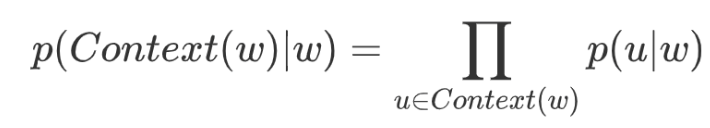
In the above formula, 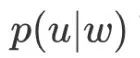 can be compared to the idea introduced in the previous section
can be compared to the idea introduced in the previous section  . Therefore, we have:
. Therefore, we have:
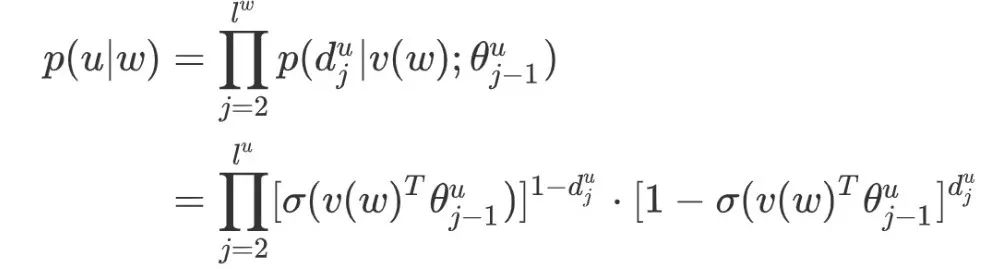
Through log-likelihood maximization, the objective function of the 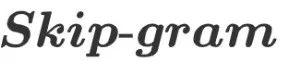 model is:
model is:
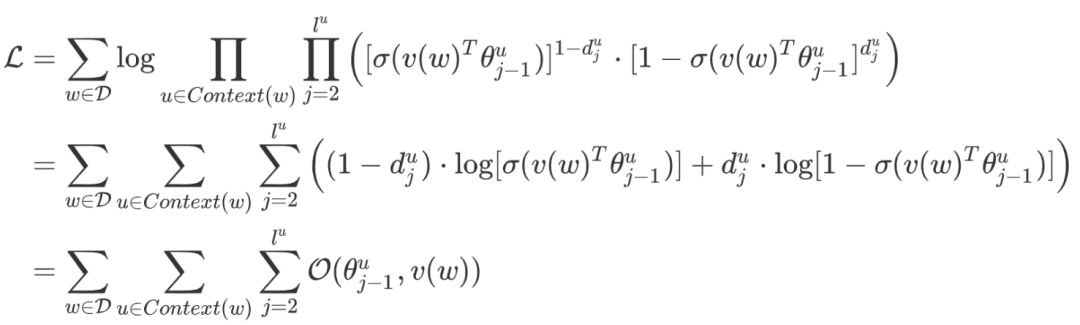
First, consider 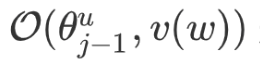 with respect to
with respect to 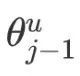 :
: 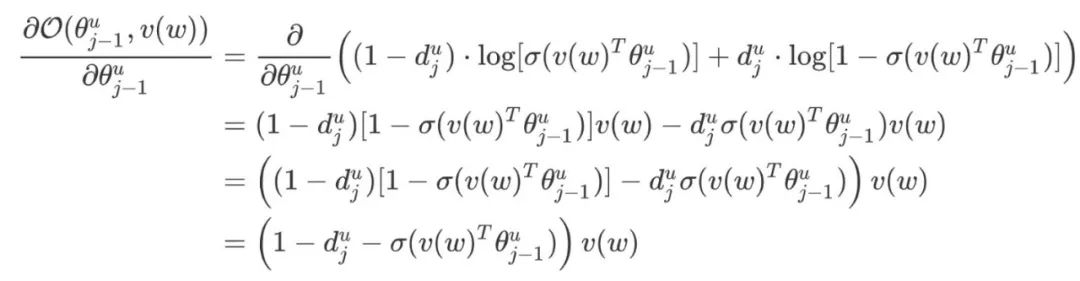
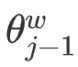 is:
is:
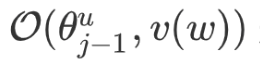 regarding
regarding 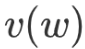 : Gradient calculations (can also be derived directly from symmetry):
: Gradient calculations (can also be derived directly from symmetry):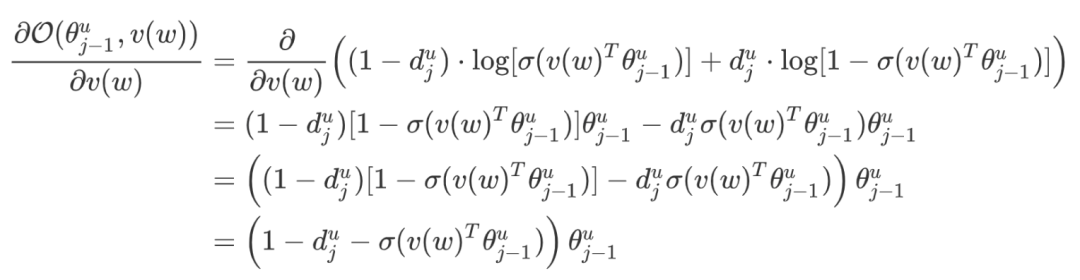
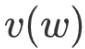 is:
is: 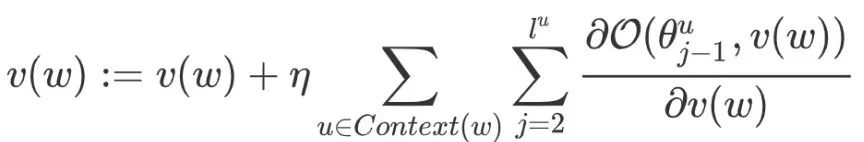
3.3 Skip-gram Model Update Pseudocode
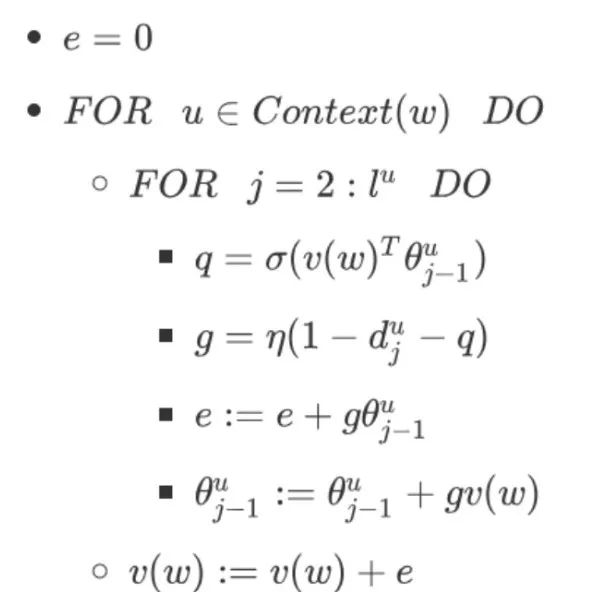
4. Summary
Word2Vec fundamentally transforms each word in natural language into a unified meaning and dimension word vector. Only by converting natural language into vector form can we build related algorithms on top of it. As for the specific meaning of each dimension in the vector, it is unknown and unnecessary to know. As the saying goes, it is mysterious and profound!
If you find this helpful, feel free to give a like, love ❤️!


<< Swipe left to add @Eva to the group >>