7 Tips to Enhance PyTorch Performance
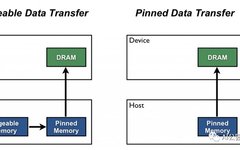
Kaggle Competition Tips Author:William Falcon, Source: AI Park Introduction Some small details can indeed improve speed. Over the past 10 months, during my work with PyTorch Lightning, the team and I have encountered many styles of structuring PyTorch code, and we have identified some key places where people inadvertently introduce bottlenecks. We are very careful … Read more






