1. Feigenbaum and DENDRAL
Feigenbaum entered Carnegie Institute of Technology (the predecessor of Carnegie Mellon) to study Electrical Engineering (EE) when he was only 16 years old. In his junior year, a course on “Mathematical Models in Social Science” set the course for his life, taught by Simon Haykin. After graduating, he stayed on to pursue his PhD at the Industrial Management Graduate School, where Haykin was the dean. After completing his PhD, he joined the Faculty of Business Administration at the University of California, Berkeley. He co-edited a collection of papers titled “Computers and Thinking” with his junior, Julian Feldman, and the royalties from this collection were later used to fund the “Computers and Thinking” award at the International Joint Conference on Artificial Intelligence (IJCAI), which became the most important award for young scholars under 40 in the field of artificial intelligence, somewhat akin to the Fields Medal in mathematics. The first recipient of this long list of awardees was Terry Winograd, followed by Douglas Lenat, the late Maler, and Andrew Ng, with the most recent recipient (2016) being Stanford University’s rising star in natural language processing, Percy Liang. In 1962, McCarthy moved from the East Coast’s MIT to the beautiful San Francisco Bay Area to establish the Computer Science Department at Stanford University. In 1964, Feigenbaum answered McCarthy’s call, leaving Berkeley to assist McCarthy at Stanford University.

Feigenbaum (1936— )
In 1958, Joshua Lederberg won the Nobel Prize in Physiology at the age of 33. The year after winning, he left his teaching position at the University of Wisconsin to move to California, invited to rebuild Stanford University’s medical school and serve as the head of the Genetics Department. At that time, Stanford’s medical school was still located in San Francisco, along with the public University of California, San Francisco. Other campuses of UC did not have medical schools, and the San Francisco campus was the medical school for all of UC until the late 1990s, when Stanford Medical School and UCSF sought to merge but ultimately did not succeed. Speaking of which, Lederberg was influenced by the “Leibniz Dream” during his undergraduate studies at Columbia University, attempting to find universal rules of human knowledge. In the summer of 1962, Lederberg was taking programming classes at Stanford’s computing center, and the first language he learned was BALGOL. He quickly met McCarthy, who had just joined Stanford from MIT, and they attempted to attract Minsky to Stanford Medical School.

Joshua Lederberg (1925—2008)
Feigenbaum met Lederberg at a conference at Stanford University’s Center for Advanced Behavioral Sciences in 1964, and their shared love for the philosophy of science led to a long and fruitful collaboration. At that time, Lederberg’s research direction was space life detection, more specifically, analyzing data collected from Mars using a mass spectrometer to see if there was a possibility of life on Mars. Feigenbaum’s interest was in machine induction, which we now call machine learning. They complemented each other perfectly: one had the data, and the other had the tools. From the perspective of the history of science, this was an interdisciplinary collaboration, with Lederberg’s influence and leadership playing a central role. According to Buchanan, the task of the computer team led by Feigenbaum was to algorithmize Lederberg’s ideas. After Lederberg completed his philosophical concepts, his interest shifted; his initial ideas took Feigenbaum and his team five years to realize, and Lederberg blamed them for being too slow.
Feigenbaum soon discovered that Lederberg was a geneticist who had no understanding of chemistry, so they enlisted the help of Carl Djerassi, a chemist, writer, and inventor of the oral contraceptive, who was also at Stanford. Djerassi had not won a Nobel Prize, but he had received the National Medal of Science (whose laureates include Wiener, Gödel, Shannon, and Yau) and the National Medal of Technology and Innovation (whose laureates include DuPont’s founder, Packard, Intel’s founder, Noyce, and Microsoft’s founder, Gates), which is quite unique. Another person who received both awards was John Cocke, who invented the RISC architecture for computers. Djerassi had just moved to Stanford from Wayne State University, and Lederberg was his first friend in California. The result of their collaboration was the first expert system, DENDRAL. DENDRAL takes mass spectrometer data as input and outputs the chemical structure of the given substance. Feigenbaum and his students captured the chemical analysis knowledge from Djerassi and his students, distilling that knowledge into rules. This expert system sometimes performed better than Djerassi’s students. In Djerassi’s extensive autobiography, only a small section mentions DENDRAL, which was not particularly significant in his illustrious academic career and colorful life. Djerassi stated that Feigenbaum always referred to the core of DENDRAL as the “Djerassi Algorithm”, while Buchanan recalled that everyone thought the provider of specialized knowledge was Lederberg; perhaps Feigenbaum was diplomatic, or perhaps the computer team had more contact with Lederberg.
Feigenbaum was an academic activist; upon arriving at Stanford, he became the director of the computing center, a position that was probably more influential than that of the computer science department chair. In the early to mid-1960s, Feigenbaum visited the Soviet Union twice and was impressed by the Soviet’s theoretical but less practical approach to computer science and cybernetics. However, the success of Soviet chess programs indeed surprised the world. The definition of Soviet cybernetics was too broad and all-encompassing, resulting in a lack of breakthroughs, while at that time, China’s automation discipline was emulating the Soviet model. The United States did not have a distinct automation discipline; the broad field of EE had significant overlap with automation. Feigenbaum realized that his Soviet colleagues were attempting to use his reputation to endorse their work and secure funding. In the United States, Bellman, the inventor of dynamic programming, advised the Air Force through the RAND Corporation that the U.S. should be wary of Soviet computer science research. Feigenbaum was displeased with Bellman’s report, believing he was using the Soviet threat to secure research benefits for himself. However, several years later, Feigenbaum used Japan’s fifth-generation project to promote a narrative of Japanese threat, raising questions about his motives. The companies founded by Feigenbaum did not achieve significant success for various reasons. Among them, Teknowledge did not succeed, but a byproduct, the knowledge base project SUMO, remains and has become one of the foundational common sense knowledge graphs now available as open source.
2. MYCIN
MYCIN’s leader, Buchanan, was also a core member of DENDRAL. Buchanan came from a philosophy background and had broad interests. In 1964, while studying philosophy at Michigan State University, he sought a summer internship at the System Development Corporation (SDC), only to find that SDC had forwarded his resume to RAND Corporation, apparently sharing resumes across defense-related organizations. At that time, Feigenbaum was working at RAND for the summer and called Buchanan, leading to his internship at RAND and his connection with Feigenbaum. Buchanan’s research direction was scientific discovery, and he approached it from a logical rather than psychological perspective, unexpectedly finding that Feigenbaum was also deeply interested in the philosophy of science. In fact, Feigenbaum and Lederberg’s earliest article about DENDRAL mentioned the concept of “mechanizing scientific inference.” After earning his PhD, Buchanan wanted to teach philosophy and asked Feigenbaum for a recommendation letter, but Feigenbaum persuaded him to come to Stanford to engage in genuine scientific discovery. Buchanan’s philosophical background helped him; at the beginning of the DENDRAL project, neither Lederberg nor Feigenbaum had considered the distinction between hypothesis generation and theory generation, while Buchanan realized that the Carnap theory he learned in philosophy class was computationally unfeasible. There was not a single team member in DENDRAL who fully understood the chemistry involved; each assumed that the others had knowledge. Buchanan’s early talks always had to include some background knowledge in chemistry, which frustrated the audience; he recalls one instance where McCarthy stood up and shouted, “Can’t you just listen?” McCarthy’s prestige saved him.
After DENDRAL’s success, Buchanan began looking for new directions. Experimental science compared to theoretical science is relatively primitive, and primitive experiences are relatively easy to translate into rules. Besides chemistry and biology, medicine is another field where expert systems could be immediately applied. At this time, Stanford Medical School welcomed a talented individual, Edward Shortliffe, who graduated with a bachelor’s degree in mathematics from Harvard University. He received his M.D. from Stanford Medical School in 1976, but a year earlier, under Buchanan’s supervision, he had already earned a Ph.D. in computer science, with his thesis being the expert system MYCIN, a diagnostic system for bacterial infections. MYCIN’s prescription accuracy was 69%, while the accuracy of specialists at that time was 80%, but MYCIN’s performance was already better than that of non-specialized physicians. For this, Shortliffe received the 1976 ACM Grace Murray Hopper Award for young computer scientists. Shortliffe then worked as an internal medicine resident at Massachusetts General Hospital for three years before returning to Stanford University as a professor in both the medical school and the computer science department.
MYCIN’s team considered DENDRAL to be the ancestor of expert systems, partly because DENDRAL indeed came earlier, and partly because Buchanan himself was from DENDRAL. However, Newell, as an outsider, believed that MYCIN was the true ancestor of expert systems because MYCIN originated the production rules that later became a feature of expert systems: imprecise reasoning. The original intention of DENDRAL was to perform machine induction based on data collected from experts, or machine learning. Although MYCIN was never clinically used, the principles behind its development were gradually distilled into the core of expert systems, EMYCIN. The motivation for EMYCIN was twofold: besides generalization, government funding was also a reason. In the early 1970s, DARPA cut funding for artificial intelligence, changing from long-term funding to annual reviews. Each time they reported to DARPA, Feigenbaum’s team had to be cautious with their wording; they dared not mention that research funds were being used for medical-related research. It wasn’t until they received funding from the National Institutes of Health (NIH) and the National Library of Medicine (NLM) that the situation improved.
3. Maturity of Expert Systems
One of the primary measures of a field’s maturity is its ability to generate revenue. The lack of commercial applications for artificial intelligence has long been a point of criticism. The most successful case of the expert system era was DEC’s expert configuration system XCON. DEC was the darling of the pre-PC era, using minicomputers to challenge IBM. When customers ordered DEC’s VAX series computers, XCON could automatically configure components according to their needs. From its launch in 1980 to 1986, XCON processed a total of 80,000 orders.
The exact savings generated by XCON for DEC has always been a mystery; the highest claim was that it saved $40 million a year, while others claimed it was $25 million, and the lowest estimate was just a few million. Regardless, DEC promoted XCON as a commercial success. XCON indeed reflected technological advancements, its origins trace back to Carnegie Mellon’s R1. Interestingly, the original XCON was written in Fortran, and after its failure, it was infamously rewritten in BASIC. Newell’s PhD student Charles Forgy invented the Rete algorithm and OPS language, significantly improving the efficiency of expert systems, which XCON quickly adopted along with subsequent versions OPS5.
From the early 1980s to the early 1990s, expert systems experienced a golden decade, but with the disillusionment surrounding Japan’s fifth-generation project, the term “expert system” became not only unfashionable but also carried negative connotations. The rise of e-commerce fueled by the Internet gave rise to many applications similar to XCON, leading to the rebranding of expert systems as rule engines, becoming standard middleware. Credit scoring, fraud detection, and risk control have always been fields where rule systems excel, and the credit company FICO acquired a series of struggling expert system companies, including Forgy’s RulesPower. Today, there are very few independent expert system companies.
4. Knowledge Representation
Knowledge representation has always been a lukewarm area in artificial intelligence, spurred by expert systems and natural language understanding. KRL (Knowledge Representation Language) is one of the earliest knowledge representation languages; it was influential but not successful. Winograd, who participated in the KRL project at Xerox PARC, summarized the lessons years later, stating that KRL needed to solve two problems simultaneously: first, the usability for knowledge engineers, meaning it should be human-readable and writable; second, it required a foundational logic in the McCarthy style to support semantics. Attempting to solve these two conflicting issues led to overly complex and ambiguous results, failing to satisfy both knowledge engineers and logicians.
Logic
Logic is the most convenient knowledge representation language, familiar to people since Aristotle, and it has various mathematical properties. Any introductory logic textbook will include the famous example of Socrates: “All men are mortal; Socrates is a man; therefore, Socrates is mortal.” This syllogism can be expressed in modern mathematical logic as follows.
Major premise and minor premise: (∀x) Man(x) ⊃ Mortal(x) & Man(Socrates)
Conclusion: Mortal(Socrates)
First-order logic is also known as predicate logic, the result of Hilbert’s simplification of Russell’s “Principia Mathematica.” Predicate logic lacks an ontology, meaning it has no axioms about a specific world. For this reason, philosophers and logicians like Quine equate logic with first-order logic. First-order logic is merely syntax without ontology or semantics; higher-order logic, in Quine’s view, is actually “set theory in disguise.” The knowledge that Feigenbaum referred to is ontology. Of course, Feigenbaum did not approach the issue from a logical perspective but rather from a psychological one, which was clearly influenced by his teachers Newell and Haykin.
Computability and computational complexity theory are closely tied to logic. First-order logic is undecidable, and the satisfiability problem for propositional logic is NP-complete. A core issue in knowledge representation is to find a subset of first-order logic that is decidable and as efficient as possible. Description logic emerged to address this need. Description logic can express entities and classes, as well as relationships between classes. The entities in description logic correspond to constants in first-order logic. The representation of entities in description logic is also known as ABox; for example, “Newton is a physicist” can be represented as:
In description logic, variables are not needed; the terminology is more akin to set theory, and the relationships between classes are referred to as TBox. For instance, in an ontology, a law firm (Lawfirm) is a subset of a company (Company), which is a subset of an organization (Organization), which is a subset of an agent (Agent), which is a subset of a thing (Thing). This series of relationships can be expressed as:
Lawfirm ⊑ Company ⊑ Organization ⊑ Agent ⊑ Thing
The corresponding first-order logic expression would be: Lawfirm(x) → Company(x), Company(x) → Agent(x), Agent(x) → Thing(x)
In the term index technique of first-order logic theorem proving, the concept of Subsumption represents the set-subset relationship between terms. TBox expresses a simplified version of Subsumption. In addition to ABox and TBox, there is also RBox, which represents relationships or roles; relationships can have operations common in set theory, such as subsets, intersections, and unions. For example, “Father’s father is grandfather” can be represented as: has Father ◦ has Father ⊑ has GrandFather, with the corresponding first-order logic expression being:
has Father(x, y) ∧ has Father(y, z) → has GrandFather(x, z)
Psychology and Linguistics
Another source of knowledge representation is psychology and linguistics, for example, the inheritance relationship of concepts is most conveniently represented as a tree rather than first-order logic. Psychological experiments show that answering “Can a canary fly?” takes longer than answering “Can a bird fly?” To answer the first question, one must make the reasoning that “A canary is a bird” again. This is because people store knowledge abstractly, which is a consideration of spatial economy. Psychologists Miller and Chomsky, among others, pioneered cognitive science, with Miller’s most famous paper being “The Magic Number Seven.” In addition to theoretical contributions, he led Princeton University’s cognitive science laboratory in his later years to create “WordNet.” WordNet is not just a thesaurus; it also defines the hierarchical relationships of words. For example, a higher-level term for car is motor, which can be further generalized to wheeled vehicle, and eventually to entity. WordNet has become a fundamental tool for natural language processing.

Figure: WordNet
Minsky’s Frame
A frame represents a type. A canary is a bird; all the properties of birds automatically transfer to canaries. An iPhone is a phone; phones can make calls, and so can iPhones. Frames have led to the object-oriented (OO) design philosophy, and related programming languages have been influenced by this. In this sense, it indeed validates the idea that when a concept has a mature implementation, it automatically separates from artificial intelligence. The semantic network (Semantic Net) that appeared around the same time is an equivalent representation method to frames. Each node in a semantic network represents a frame, and the edges on each node can be viewed as slots.
Sowa’s Conceptual Graph
John Sowa of IBM proposed the “conceptual graph” in the early 1980s, attempting to lay knowledge representation on a more solid mathematical and logical foundation. Around the same time or slightly earlier, German mathematician Rudolf Wille proposed “formal concept analysis” based on algebra. The theory of programming languages also became increasingly rigorous. In conceptual graphs, the multiple inheritance type hierarchy can be represented using the algebraic partial order relation known as a lattice. A “total order” relation is a special case of a “partial order”. In a totally ordered set, each member is either a ≤ b or b ≤ a. A partial order allows a member to have multiple superiors and subordinates, whereas in a totally ordered set, each member can only have one superior and one subordinate. Thus, total order relations are sometimes referred to as linear relations. When knowledge is represented using lattices, each concept is a member of the lattice, and the concepts follow a partial order relationship.
5. Lenat and Large Knowledge Systems
Amidst the frenzy brought on by Japan’s fifth-generation project, the U.S. government decided to unite several high-tech companies to establish the Microelectronics and Computer Technology Corporation (MCC) in Austin, Texas, to counter Japan. Admiral Inman was appointed CEO, and Woody Bledsoe, a senior professor engaged in machine theorem proving at the Austin campus, joined MCC full-time to lead R&D. This calls to mind the division of labor between General Griffiths and Oppenheimer during the Manhattan Project in World War II. Feigenbaum proposed creating a National Center for Knowledge Technology in the U.S., akin to Diderot’s Encyclopedia, to compile the knowledge of humanity throughout history, which naturally influenced MCC’s plans. Bledsoe recommended Feigenbaum’s student, Douglas Lenat.
Lenat, in his early 30s, was a rising star in the field of artificial intelligence. After earning dual degrees in mathematics and physics from the University of Pennsylvania, he obtained a master’s in mathematics. After graduation, he lost interest in academic work in mathematics and physics, but faced conscription, so he went to Caltech to pursue a PhD. During this time, he developed a strong interest in artificial intelligence and transferred to Stanford University to study under McCarthy, but coincidentally, McCarthy was on sabbatical that year, so he became a student of Feigenbaum and Buchanan. His doctoral thesis implemented a program called AM, for which he received the “Computers and Thinking” award from IJCAI in the second year after his graduation. AM stands for Automated Mathematician, which can automatically “discover” theorems. Lenat did not use the term “invent”; in a sense, this reflects his philosophical stance. After facing a series of criticisms regarding AM’s lack of rigor, Lenat introduced AM’s successor, Eurisko. Eurisko’s application area was broader, including games.

Lenat (1950— )
When Lenat joined MCC, he had a new idea: to encode human common sense and build a knowledge base. This new project was called Cyc, named after the English word “encyclopedia.” This was essentially the earliest knowledge graph. Lenat firmly supported his teacher Feigenbaum’s Knowledge Principle: a system can exhibit advanced intelligent understanding and behavior primarily because of the specific knowledge it demonstrates in its field: concepts, facts, representations, methods, metaphors, and heuristics. Lenat even stated, “Intelligence is a million rules.”
Sowa proposed the notion of “knowledge soup”: the knowledge in our minds is not a lump of knowledge but several chunks, each internally consistent, but inconsistencies may exist between chunks, and the chunks are loosely coupled. Guha, whose doctoral advisors at Stanford were McCarthy and Feigenbaum, wrote his dissertation on how to decompose a large theory into multiple “microtheories” and how to use Cyc as a front end for multiple different data sources rather than as a whole, which is precisely the implementation of Sowa’s “knowledge soup.” Cyc thus became a tool for data or information integration. Lenat was somewhat displeased with this but still brought Guha on board.
Lenat held Cyc in high regard. In 1984, he predicted that within 15 years, by 1999, every computer sold on the streets would come pre-installed with Cyc. In 1986, Lenat reiterated that if Cyc were to be usable, it would need at least 250,000 rules, which would take at least 350 person-years, or 35 people working for ten years. At the start of the Cyc project, there were about 30 knowledge engineers, whose daily work was to encode everyday common sense using Cyc’s language, CycL, covering areas such as education, shopping, entertainment, and sports. By 1995, as Japan’s fifth-generation project faded, the U.S. government also cut support for MCC. Lenat took Cyc and left MCC to establish Cycorp, beginning a long entrepreneurial journey. Core member Guha left MCC and later joined Apple, Netscape, and Google.
WordNet, on the other hand, can be easily found in various versions of Linux configuration App Centers. WordNet is more fundamental and easier to use than Cyc, though it lacks the extensive reasoning capabilities of Cyc. In another 50 years, people may not be as familiar with first-order logic as they are with Shakespeare. Perhaps WordNet is not the best example. Cyc’s original goal was more akin to today’s Wikipedia, but while Wikipedia’s audience is human, Cyc’s users are machines. Cyc faced criticism in the early 1990s for lacking successful cases, while other expert systems had applications to varying degrees. Lenat defended that Cyc would only yield benefits once the volume of knowledge reached a critical mass. Now, leaving aside the criticisms of that time, more than 20 years have passed, and we still do not see substantial applications.
Cyc now has two versions: a commercial version and a research version. The commercial version is paid, while the research version is open to researchers. There was once an open-source version called OpenCyc, which was a simplified version, but it was discontinued due to numerous issues encountered during trials. Cyc is preparing to replace OpenCyc with a cloud version. Lenat once said, “Learning only occurs at the edges of known things, so people can only learn new things that are similar to what they already know. If you try to learn something that is too far from what you already know, you won’t succeed. The greater the range of that edge (the more you know), the more likely you are to discover new things.” This not only reflects his early insights into machine learning but can also be seen as his understanding of the later Cyc project. When Lenat started the Cyc project in 1984, he was just over 30 years old, and now, over 30 years later, he is nearing 70 and still serves as CEO of Cycorp.
6. Semantic Web
After the expert system wave subsided, this faction found itself lacking in logical prowess, often clashing with the theorem-proving faction; on the other hand, their engineering practices were somewhat lacking. After the expert system trend faded, they became an undercurrent until one of the accidental supporters of the World Wide Web, Tim Berners-Lee, proposed the “Semantic Web” (see Berners-Lee 2001), and they saw an opportunity. Berners-Lee became known for the grassroots and convenient HTTP protocol and hypertext linking standard HTML, being referred to by various media as the inventor of the World Wide Web. After the first wave of Internet hype, he left the European Particle Physics Laboratory to join the newly founded World Wide Web Consortium (W3C) at MIT as its chairman. MIT secured him a position in the then-Computer Science Laboratory (now merged into the CSAIL Computer Science and Artificial Intelligence Laboratory), evidently aiming to enhance the institute’s influence in the rising tide of the Internet. The Internet boom widened the gap between Silicon Valley, the U.S. tech innovation hub, and Boston’s Route 128, where MIT is located. Twenty years later, Berners-Lee fulfilled expectations by receiving the 2016 Turing Award, which is perhaps the lowest in value in Turing Award history.
In fact, the greater credit for the World Wide Web should go to the genius programmer Marc Andreessen, whose revolutionary Mosaic browser brought about the Internet revolution. Young Andreessen aimed to change the world rather than seek fame. Under the guidance and assistance of Jim Clark, he founded the iconic Internet company Netscape; after experiencing several challenging but not particularly successful startups, he adapted to the second peak of the Internet by founding the new-generation venture capital firm Andreessen Horowitz, achieving results and influence that rivaled established venture capital firms like KPCB and Sequoia Capital.
Returning to the topic, thanks to the SGML standard that matured in the 1980s, the hypertext linking standard HTML is a somewhat shortsighted simplification of SGML. HTTP was merely a trivial add-on to the browser until the Internet standardization organization IETF made several modifications to HTTP, making it resemble a more professional protocol. The purpose of W3C is to establish standards for the World Wide Web. A group of long-unrecognized non-mainstream IT practitioners quickly gathered around Berners-Lee. The various haphazard standards they proposed in W3C indeed reflected their lack of theoretical foundation. In various W3C meetings, senior practitioners from major tech companies who had drifted to the margins were often seen; some of them, even after changing jobs, continued to represent different companies in various standardization organizations, and their careers were not aimed at making technological contributions but rather finding noble reasons for their existence while detaching from corporate management. At the 2006 American Association for Artificial Intelligence (AAAI) conference, after Berners-Lee’s keynote speech, Peter Norvig, then Google’s Director of Research, sharply questioned him, which was perceived as a harsh critique of the Semantic Web.
The work of the W3C Semantic Web later introduced description logic after some quasi-logicians joined, becoming seemingly rigorous, but after several iterations, it evolved into a hodgepodge, theoretically unsound and practically unusable. The saying goes, “All beginnings are difficult,” but if a bad beginning is made, it becomes a disaster, creating artificial obstacles for future corrections. We can compare the work of the Semantic Web with early DENDRAL and MYCIN; it is clear that in terms of theory, practice, and socio-political context, they are not comparable. Almost every “Semantic Web” project bears the shadow of Guha; in 2013, while at Google, he gave a talk titled “Light at the End of the Tunnel,” which, rather than boasting about success, summarized lessons learned.
7. Google and Knowledge Graphs
Alongside Wikipedia, there was also Freebase. While Wikipedia is aimed at humans, Freebase emphasizes machine readability. In 2016, Wikipedia reached 10 million articles, with the English version hitting 5 million, while Freebase had 40 million entities represented. Behind Freebase was a startup called Metaweb, one of the founders being Danny Hillis. In 2010, Metaweb was acquired by Google, which gave it the catchy name “Knowledge Graph.” In 2016, Google stopped updating Freebase and donated all its data to Wikidata, a project supported by the Wikimedia Foundation, the parent organization of Wikipedia, and funded by the Allen Institute for Artificial Intelligence, founded by Microsoft co-founder Paul Allen.
Besides Wikidata, there are several other open-source knowledge graphs, such as DBpedia, Yago, and SUMO. Notably, SUMO is the legacy of Teknowledge, a failed company founded by Feigenbaum. One of the major sources of foundational data for all open-source knowledge graphs is Wikipedia. Taking the Wikipedia entry for Marie Curie as an example, on the right side of the “Marie Curie” page, there is a box called an infobox, which contains data about Marie Curie, such as her birthday, date of death, birthplace, alma mater, teachers, and students; this data is already close to structured quality.
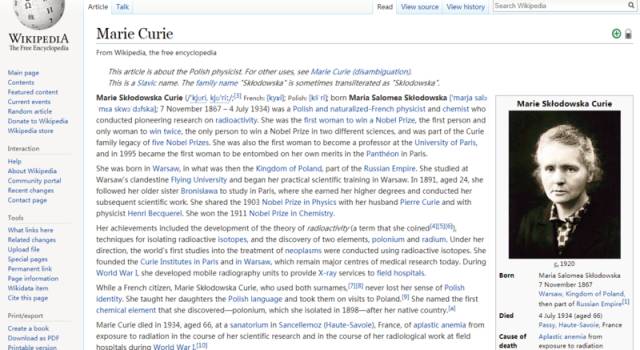
Wikipedia entry for “Marie Curie”
IBM Watson is built on the integration of two open-source knowledge graphs, Yago and DBpedia. Above the common sense graph, vertical domain-specific graphs (e.g., biomedical, health, finance, e-commerce, transportation, etc.) can be constructed.
Newell and Haykin are considered symbolic AI figures in artificial intelligence. In fact, there are sub-factions within the symbolic camp, with machine theorem proving being more “symbolic” than Haykin’s faction. Newell and Haykin’s early careers were intertwined with a group of logicians, and Feigenbaum inherited his teachers’ genes, attacking the second-generation representative of theorem proving, Alan Robinson, with vigor. Norberg, who conducted oral histories at the Babich Institute at the University of Minnesota, often tried to trace the symbolic camp back to the rivalry between MIT and Carnegie Mellon, with Stanford’s McCarthy and SRI’s Nilsson leaning toward MIT, while Feigenbaum at Stanford favored his alma mater, Carnegie Mellon. Of course, we can trace it back even further to the Dartmouth Conference, where McCarthy and Haykin’s rivalry began. But ultimately, the theoretical foundation of expert systems remains machine theorem proving. Although Feigenbaum, in a sense, created the topic of the opposition between knowledge and reasoning, emphasizing the importance of knowledge for logical reasoning, knowledge and reasoning are an inseparable pair. Emphasizing knowledge does not exempt one from the symbolic camp. If we look at expert systems from the perspective of pure theorem proving, knowledge is essentially axioms; the more axioms there are, the fewer reasoning steps there will be. The so-called opposition between knowledge and reasoning is actually the distinction between narrow (specific purpose) and broad (general). Knowledge is narrow, while reasoning is broad, as it does not require excessive axioms. Narrow knowledge leads to efficient short-term implementation for machines, but the learning threshold for humans is higher; broad reasoning naturally leads to inefficient implementation for machines, but the learning threshold for humans is lower. First-order logic has the lowest learning threshold, but as the knowledge base expands, the reasoning engine must become more specialized to be efficient.

Recommended Reading:
[TCMKB] The Strongest Explanation! What Exactly is the Traditional Chinese Medicine Knowledge Graph? How Did It Come About? What Does It Have?
This article is reproduced from the WeChat public account Open Knowledge Graph. The original text is excerpted from Chapter 3 of “A Brief History of Artificial Intelligence”: From Expert Systems to Knowledge Graphs, by Nick.
