Some small details can indeed improve speed.

Over the past 10 months, during my work with PyTorch Lightning, the team and I have encountered many styles of structuring PyTorch code, and we have identified some key places where people inadvertently introduce bottlenecks.
We are very careful to ensure that PyTorch Lightning does not make any of these mistakes in the code we automatically write for you, and we even correct these errors for users when we detect them. However, since Lightning is just structured PyTorch, and you still control all of PyTorch, in many cases, we cannot do much for the user.
Additionally, if you are not using Lightning, you may inadvertently introduce these issues into your code.
To help you train faster, here are 8 tips you should know that might slow down your code.
Use Workers in DataLoaders

The first mistake is easy to fix. PyTorch allows loading data simultaneously across multiple processes.
In this case, PyTorch can bypass the GIL lock by processing 8 batches, each on a separate process. How many workers should you use? A good rule of thumb is:
num_worker = 4 * num_GPU
There is a good discussion on this here: https://discuss.pytorch.org/t/guidelines-for-assigning-num-workers-to-dataloader/813/7
Warning: The downside is that your memory usage will also increase.
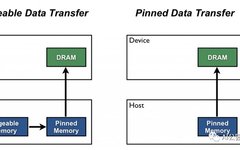
Pin Memory

Do you know that sometimes your GPU memory shows it is full but you are sure your model is not using that much? This overhead is called pinned memory. This memory is reserved as a type of “working allocation”.
When you enable pinned_memory in a DataLoader, it “automatically places the fetched data tensors in pinned memory, making data transfer to CUDA-enabled GPUs faster”.
This means you should not unnecessarily call:
torch.cuda.empty_cache()
Avoid CPU to GPU Transfers and Vice Versa
# bad.cpu()
.item()
.numpy()
I see a lot of calls to .item(), .cpu(), or .numpy(). This is very bad for performance because each call transfers data from the GPU to the CPU, greatly reducing performance.
If you are trying to clear the additional computation graph, use .detach().
# good.detach()
This will not transfer memory to the GPU; it will remove any computation graph attached to that variable.
Create Tensors Directly on GPUs
Most people create tensors on GPUs like this:
t = tensor.rand(2,2).cuda()
However, this first creates a CPU tensor and then transfers it to the GPU… which is really slow. Instead, create the tensor directly on the desired device.
t = tensor.rand(2,2, device=torch.device('cuda:0'))
If you are using Lightning, we automatically place your model and batches on the correct GPU. However, if you create a new tensor somewhere in your code (for example: sampling random noise for a VAE, or something similar), you must place the tensor yourself.
t = tensor.rand(2,2, device=self.device)
Each LightningModule has a convenient self.device call, whether you are on CPU, multiple GPUs, or TPUs, Lightning will choose the correct device for that tensor.
Use DistributedDataParallel, Not DataParallel
PyTorch has two main modes for training across multiple GPUs. The first is DataParallel, which splits a batch of data across multiple GPUs. But this also means the model must be replicated on each GPU, and once gradients are computed on GPU 0, they must be synchronized to other GPUs.
This requires a lot of expensive GPU transfers! In contrast, DistributedDataParallel creates model replicas on each GPU (in its own process) and only allows a portion of the data to be available to that GPU. It’s like training N independent models, except once each model computes gradients, they synchronize gradients between models… this means we only transfer data between GPUs once per batch.
In Lightning, you can easily switch between the two:
Trainer(distributed_backend='ddp', gpus=8)
Trainer(distributed_backend='dp', gpus=8)
Note that both PyTorch and Lightning discourage the use of DP.
Use 16-bit Precision
This is another way to speed up training that we don’t see many people using. In the part of your model that trains in 16bit, the data goes from 32-bit to 16-bit. This has several advantages:
-
You use half the memory (which means you can double the batch size and halve the training time). -
Some GPUs (V100, 2080Ti) can automatically accelerate (3-8 times) because they are optimized for 16-bit computation.
In Lightning, this is simple:
Trainer(precision=16)
Note: Before PyTorch 1.6, you also had to install Nvidia Apex, but now 16-bit is natively supported in PyTorch. However, if you are using Lightning, it supports both features and automatically switches based on the detected PyTorch version.
Profile Your Code
If you are not using Lightning, the last piece of advice may be difficult to implement, but you can use a tool like cprofiler to achieve it. However, in Lightning, you can get a summary of all the calls made during training in two ways:
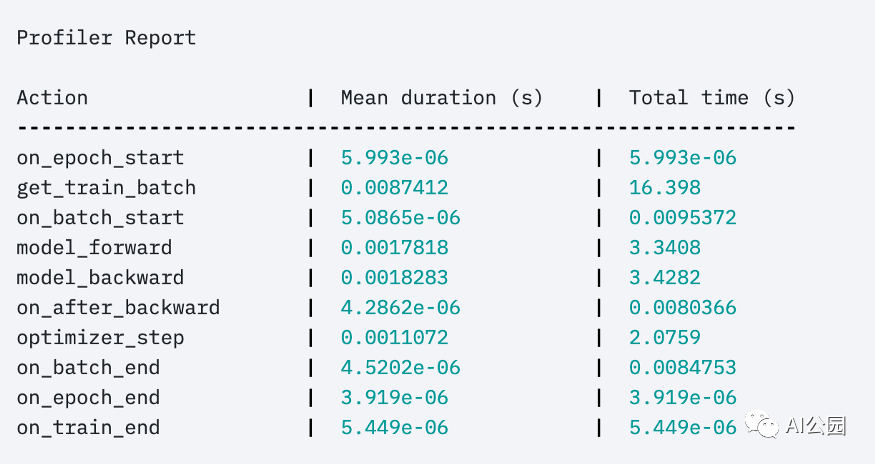
First, the built-in basic profiler
Trainer(profile=True)
can give output like this:
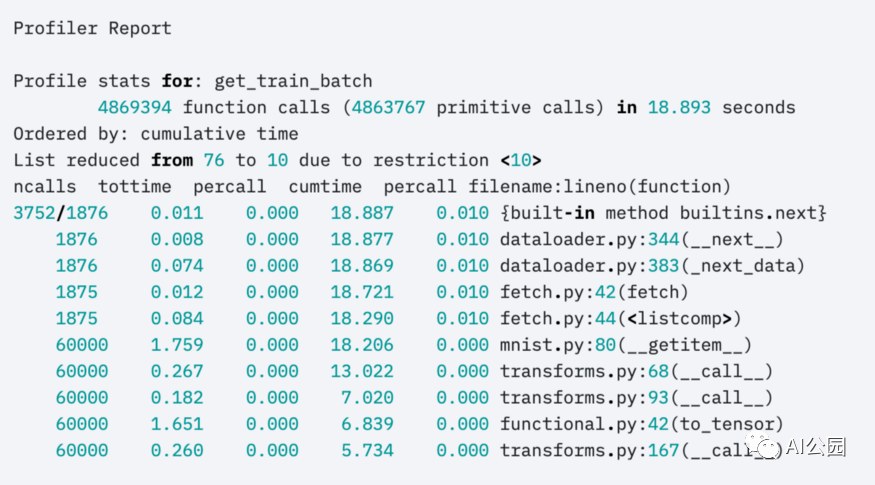
Or the advanced profiler:
profiler = AdvancedProfiler()
trainer = Trainer(profiler=profiler)
to get finer-grained results:

Original English: https://towardsdatascience.com/7-tips-for-squeezing-maximum-performance-from-pytorch-ca4a40951259
