Convolutional Neural Networks (CNN): Principles and Applications
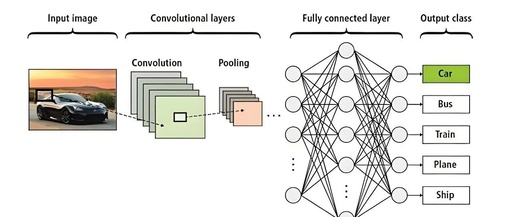
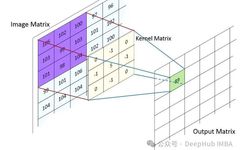
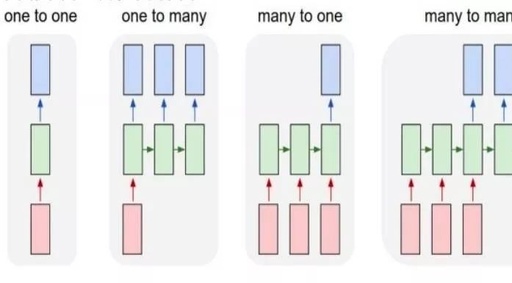
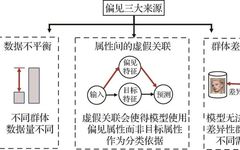
In the vast cosmos of artificial intelligence, Convolutional Neural Networks (CNN) shine like a brilliant star, leading the rapid development of computer vision, image recognition, natural language processing, and other fields. Since its inception in the 1980s, CNN has gradually become one of the core algorithms of deep learning due to its unique structure and … Read more