
The few-shot problem in image tasks (where insufficient training data makes it difficult for models to learn effective and generalized features) is widespread due to challenges such as high costs of data labeling and uneven sample distribution. This can lead to models overfitting on few samples and classifiers being biased towards the majority class due to severe class imbalance. Given the targeted, personalized, and precise nature of few-shot samples, algorithms for image processing in this context will remain an important research topic for a long time.
In March 2024, the journal “International Imaging Systems and Technology” (JCR Q2, impact factor 3.3) featured an article titled “SVTNet: Automatic Bone Age Assessment Network Based on TW3 Method and Vision Transformer” by Zhang Yi, Wu Tongning, and others from the China Academy of Information and Communications Technology on its cover. This article addresses the few-shot image recognition problem by integrating a hybrid CNN-ViT model framework that focuses on global information while tackling the learning model’s perspective in classification tasks. Below is an introduction to the research background and content of the article.

Figure 1: March 2024 Cover Feature of the Article in International Imaging Systems and Technology
Research Background: Development of Vision Transformer and CNN-ViT
In 2020, the Google team proposed the ViT model, applying Transformer technology to image classification. Unlike CNNs, ViT learns global patterns and detailed features from images by splitting them into sequence data for the Transformer, eliminating the need for convolution operations. However, ViT may not perform as well as CNNs in handling fine-grained features due to its lack of inductive bias, especially relying on regularization and data augmentation in small datasets. The hybrid CNN-ViT model can compensate for ViT’s shortcomings and merge the advantages of both. In this model, images are first processed through CNN layers for initial feature extraction, followed by classification through ViT, effectively combining CNN’s ability to capture local information with ViT’s understanding of global context.
Research Content: Construction and Application of the CNN-ViT Model
Bone age assessment (BAA) is a crucial method for evaluating children’s growth and development, playing an important role in predicting adult height and diagnosing various diseases such as osteoporosis, precocious puberty, and dwarfism. Clinically, the Tanner-Whitehouse 3 (TW3) method is commonly used for bone age assessment, which involves grading the maturity of 20 regions of interest (ROIs) (Figure 2) and then aggregating these scores to calculate an overall skeletal maturity score, which is then converted into bone age. Although the TW3 method is widely adopted due to its high interpretability and accuracy, its process is cumbersome and relies on the expertise of radiologists, making the development of an automated TW3-BAA system crucial for assisting clinicians.
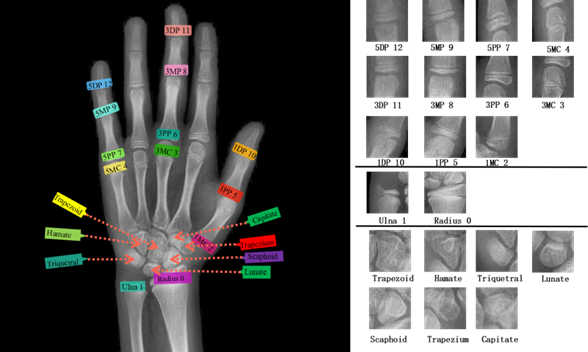
Figure 2: Diagram of TW3 Bone Age Assessment Method ROIs
The artificial intelligence research team at the China Academy of Information and Communications Technology proposed a multi-region ensemble network, SVTNet, based on the CNN-ViT framework for automated TW3-BAA tasks. This algorithm first uses a Spatial Configuration-Net (SCN) to locate 37 key points (as shown in Figure 3), which serve as reference markers to crop the 20 TW3-RUS/C scoring ROIs and classify the skeletal maturity of each region. The SVTNet network addresses the few-shot problem in bone age assessment by combining CNN’s ability to extract local fine-grained features with ViT’s capability to utilize global context information for feature classification. Additionally, difficult sample mining techniques are introduced to focus more on hard-to-classify samples, improving the model’s classification accuracy. Finally, the bone age score is automatically derived using a rule table of “skeletal maturity-bone age.” The entire algorithm flow is illustrated in Figure 4.
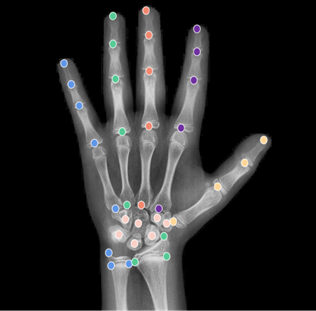
Figure 3: 37 Hand Key Points Located Using SCN Network
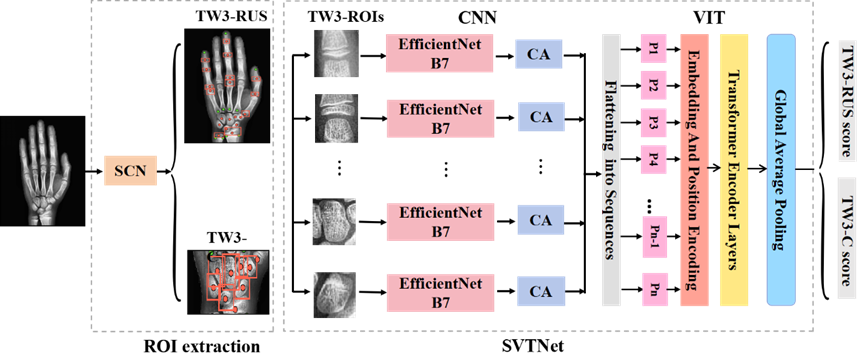
Figure 4: Algorithm Flowchart
This study evaluated the performance of the SVTNet model on a clinical database of Chinese children and calculated the mean absolute error (MAE) of skeletal maturity. The proposed algorithm’s RUS/C series bone maturity scores had MAEs of 29.4 and 30.4, with corresponding BAA MAE values of 0.47 years and 0.50 years. These results indicate that the accuracy of the SVTNet model is comparable to that of radiologists, and the algorithm can output all intermediate results, providing interpretability and traceability. Comparative experiments with related algorithms in the field of bone age assessment, such as Bonnet and SIMBA, conducted on the phalangeal data showed that the proposed algorithm achieved the best results (Figure 5).
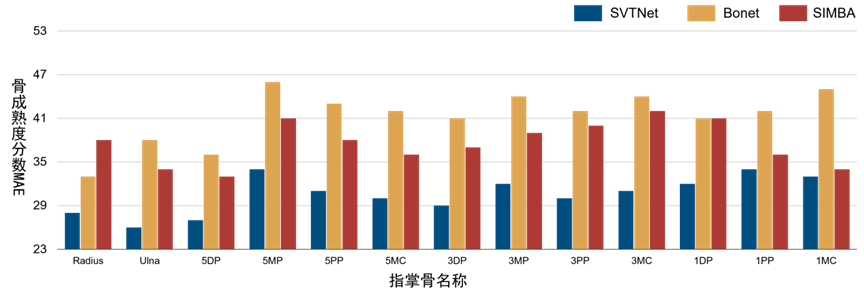
Figure 5: Comparative Experimental Results of Bone Maturity Score MAE on Phalangeal Dataset
Conclusion
The CNN-ViT network has shown significant advantages in the field of few-shot image recognition, particularly in the following aspects:
1. Fusion of Local and Global Features to Enhance Model Expressiveness: CNN effectively captures local features in images, such as edges and textures, while ViT can capture global information through self-attention mechanisms. This combination allows the CNN-ViT model to understand both the details and overall structure of images in few-shot recognition tasks, improving accuracy and generalization ability.
2. Balancing Efficiency and Performance, Lowering the Threshold for Large Model Deployment: Traditional ViT models require vast amounts of data and computational resources to achieve excellent performance. By combining CNN with ViT, the model can leverage CNN’s feature extraction capabilities to reduce the complexity of ViT processing, improving training efficiency without sacrificing too much performance.
3. Strengthening Few-Shot Learning to Address Sample Scarcity: Few-shot learning relies on the generalization ability of Transformers. The CNN-ViT structure can train better models with fewer samples, especially after introducing techniques like meta-learning in the ViT part, further enhancing the model’s adaptability to new categories.
The CNN-ViT architecture has demonstrated great potential in the field of few-shot image recognition, and the team plans to further research different network structures, improvements in attention mechanisms, and model compression techniques to enhance model performance and generalization ability.
Contact Information:
China Academy of Information and Communications Technology
Artificial Intelligence Research Institute
Zhang Yi
18810252336
Reviewed by | Jin Yan, Shan Shan
Edited by | Ling Xiao

Recommended Reading



