1. What is a Neural Network?
A neural network (Neural Networks, abbreviated as NN), also known as an artificial neural network (ANN) or simulated neural network (SNN), is a subset of machine learning (ML, Machine Learning) and is the core of deep learning (DL, Deep Learning) algorithms. Its name and structure are inspired by the human brain, mimicking the way biological neurons transmit signals.The following image is a schematic diagram of the biological neuron structure:
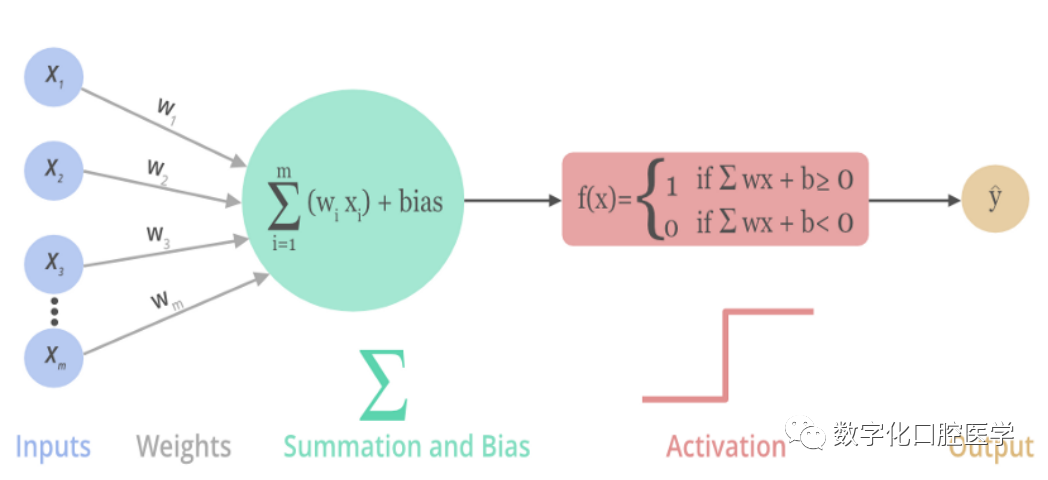
An artificial neural network (ANN) consists of layers of nodes, including an input layer, one or more hidden layers, and an output layer (as shown in the figure below). Each node, also known as an artificial neuron xi, connects to another node with associated weights Weight and thresholds. If the output of any single node exceeds a specified threshold, that node will be activated Activation and send data to the next layer of the network. Otherwise, the data will not be passed to the next layer of the network.
The neural network relies on training data to continuously learn and improve its accuracy over time. However, once the accuracy of these learning algorithms is fine-tuned, they become powerful tools in computational science and artificial intelligence, allowing us to quickly classify data (such as feature recognition, image segmentation, etc.). Tasks like speech recognition or image recognition may only take minutes instead of hours compared to manual recognition by human experts.
2. How Does a Neural Network Work?
Imagine each node as its own linear regression model, consisting of input data (xi), weights (wi), biases (bias), and output results. The formula is as follows:
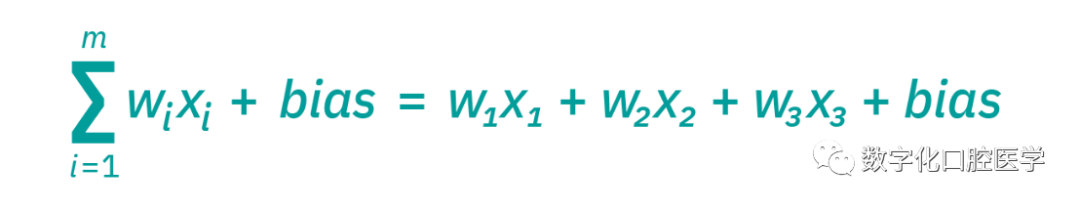
Once the input layer is established, weights are assigned (through training with a large sample of data, continuously optimizing this weight factor). These weights help determine the importance of any given variable; larger weights contribute more significantly to the output compared to other inputs. All inputs are multiplied by their respective weights and then summed. Afterward, the output is passed through an activation function (which will be introduced next) that determines the output result. If the output exceeds the given threshold, it will “trigger” (or activate) the node, passing data to the next layer in the network. This causes the output of one node to become the input of the next node. This process of passing data from one layer to the next defines the neural network as a feedforward network.
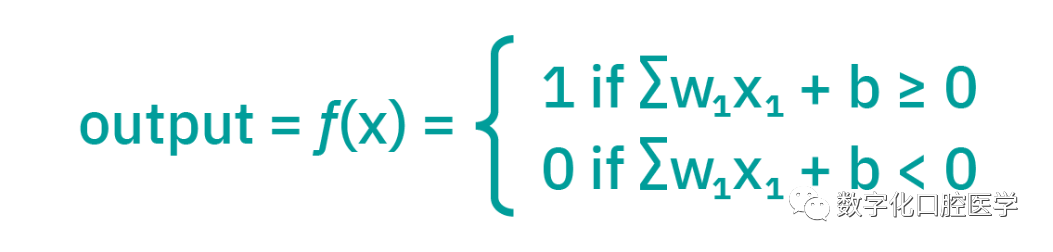
As we begin to think about more practical use cases for neural networks, such as image recognition or classification, we will use supervised learning or labeled datasets to train the algorithms. When training the model, we will use a loss function to evaluate its accuracy, typically using Mean Squared Error (MSE) in regression models, as shown in the formula below:

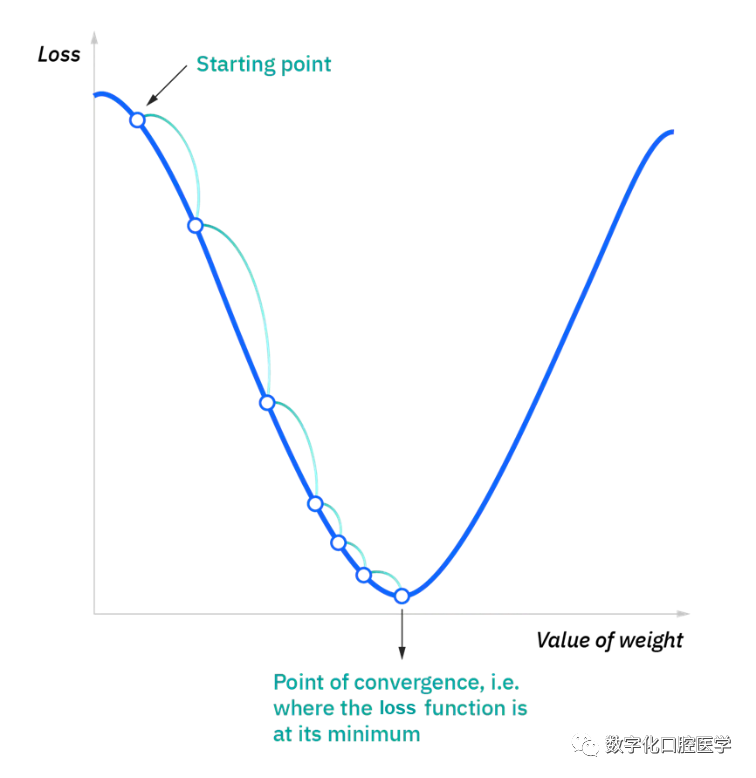
i represents the sample index, y-hat is the predicted result, y is the actual value, and m is the number of samples. The ultimate goal is to minimize the loss function to ensure the correctness of the fit for any given observation. As the model adjusts its weights and biases, it uses the loss function and reinforcement learning to reach a convergence point or local minimum. The algorithm adjusts the weights through gradient descent, allowing the model to determine the direction to reduce errors (or minimize the loss function). With each training example, the model’s parameters are continuously adjusted, gradually converging to the minimum. The following image illustrates the loss as weights change:
3. Types of Neural Networks
Neural networks can be classified into different types, each serving different purposes.
Feedforward Neural Networks or Multi-Layer Perceptrons (MLP) are composed of an input layer, one or more hidden layers, and an output layer. While these neural networks are often referred to as MLP, it is worth noting that they are actually composed of sigmoid neurons rather than perceptrons, as most real-world problems are nonlinear. Data is typically fed into these modules for training, and they form the basis for computer vision, natural language processing, and other neural networks.
Convolutional Neural Networks (CNN) are similar to feedforward networks but are typically used for image recognition, pattern recognition, and/or computer vision. These networks utilize principles of linear algebra (particularly matrix multiplication) to identify patterns in images.
Recurrent Neural Networks (RNN) are recognized by their feedback loops. These learning algorithms are primarily used in situations where time series data is used to predict future outcomes (such as stock market predictions or sales forecasts).
4. Neural Networks and Deep Learning
Deep learning and neural networks are often used interchangeably in conversation, which can be confusing. Therefore, it is worth noting that the “depth” in deep learning simply refers to the depth of layers in a neural network. A neural network with more than three layers (including input and output) can be considered a deep learning algorithm. A neural network with only two or three layers is merely a basic neural network.
References:
https://www.ibm.com/cn-zh/cloud/learn/neural-networks#toc–hcfiGN3t
https://www.cnblogs.com/maybe2030/p/5597716.html