

This article is authorized for reprint by AI new media Quantum Bit (WeChat ID: qbitai), please contact the source for reprint.
This article has a total of 2400 words and is recommended to read in 9 minutes.
The traditional convolution operation is about to become a thing of the past.

Facebook and the National University of Singapore have jointly proposed a new generation of alternatives: OctConv (Octave Convolution), which is stunning in effect and very convenient to use.
OctConv acts like a “compressor” for convolutional neural networks (CNNs). Replacing traditional convolutions with it can improve performance while saving computational resource consumption.
For example, when replacing traditional convolutions in a classic image recognition algorithm, the recognition accuracy on ImageNet can achieve a 1.2% improvement while only requiring 82% of the computing power and 91% of the storage space.
If the accuracy requirement is not so high, and it meets the original level, only half of the floating-point computation power is sufficient.
To achieve such improvements, one might think it requires a complete overhaul of the neural network, right?
Not at all, OctConv is plug-and-play, requiring no modification of the original network architecture or adjustment of hyperparameters, making it incredibly convenient.
This new generation of convolution has Ian Goodfellow, the main creator of GANs and AI expert, eagerly promoting it, not only retweeting and recommending it but also stating he will continue to monitor its progress and inform everyone when it is open-sourced.
OctConv has also gained recognition from many netizens. In just 5 hours, Goodfellow’s tweet garnered 700 likes, with netizens exclaiming, “Excellent work!”
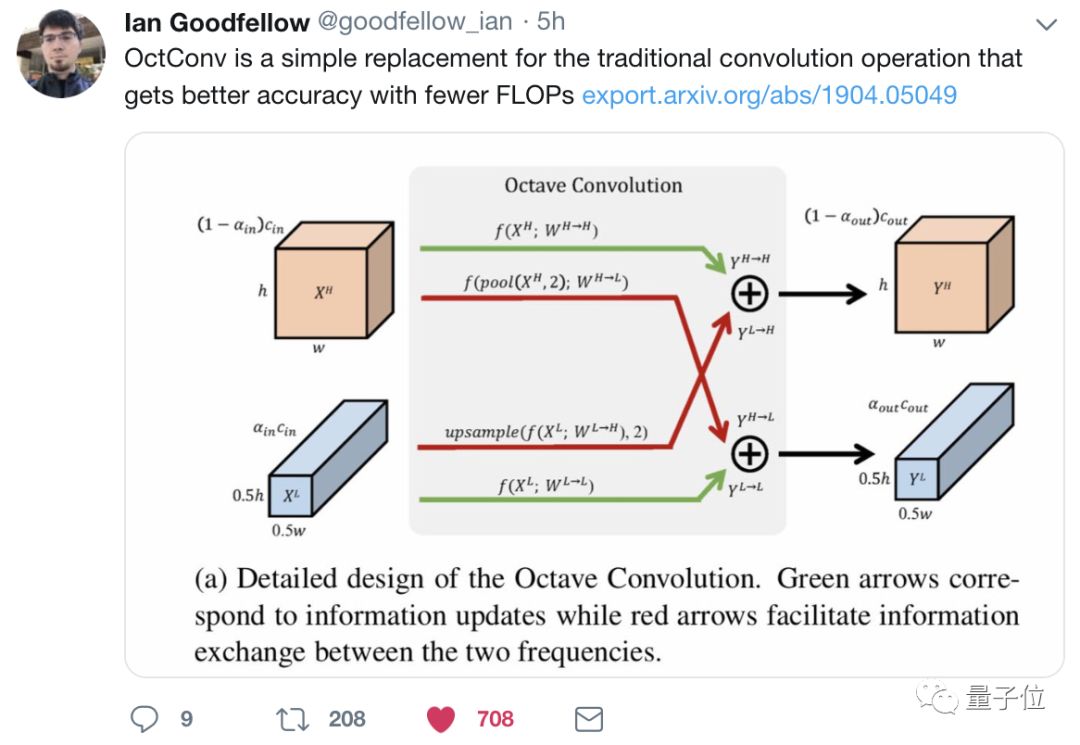
So, what exactly is this magical network called OctConv?
Compute Power ↓↓, Accuracy ↑↑
Let’s first take a look at its performance.
For instance, with the classic image recognition algorithm: ResNet-50, what changes will the new convolution operation bring?
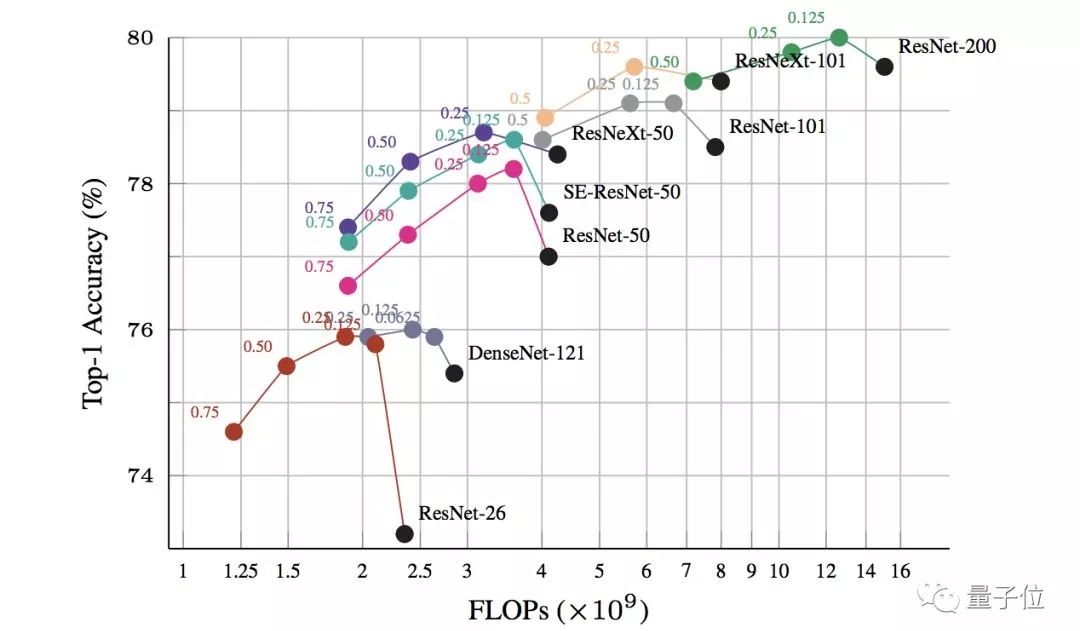
The pink line in the above figure shows the impact of different parameter configurations of OctConv on ResNet-50. The second pink dot from the left shows a relatively balanced configuration: slightly higher accuracy than the original version (the black dot on the far right), while the required floating-point computation power is only half of the original.
The other lines represent various image recognition networks, from ResNet-26 and DenseNet to ResNet-200, all demonstrating improved performance and reduced computational requirements with the support of OctConv.
By adjusting the parameter α of OctConv, one can find a balance between performance improvement and computational savings.
While reducing computational requirements, OctConv can also shorten the time required for neural network inference. For instance, the inference time for ResNet-50 can be gradually reduced as the parameter α increases. Keeping the accuracy unchanged, the inference time can be shortened to 74 milliseconds, which is 62% of the original.
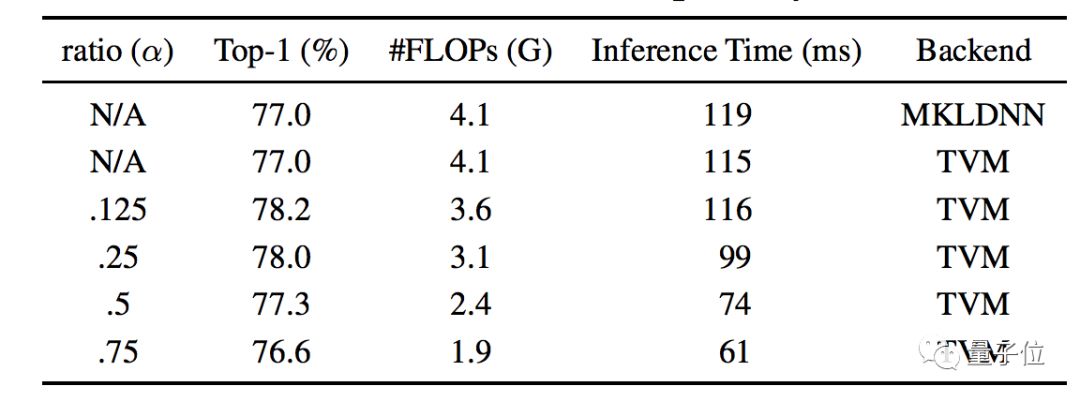
Researchers tested how OctConv would affect the image classification capabilities of large, medium, and small models.
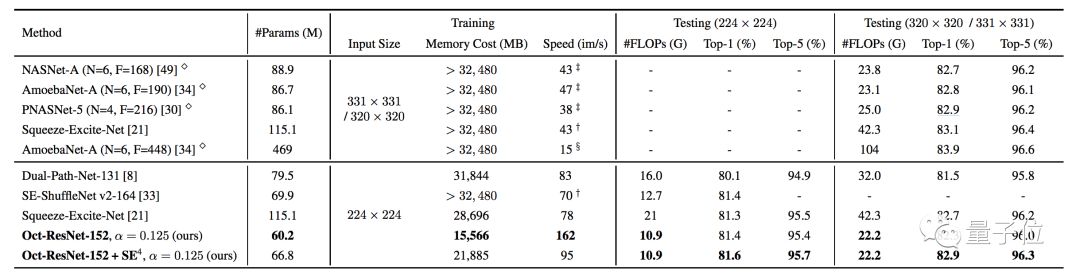
After using OctConv, the large neural network ResNet-152 can achieve a Top-1 classification accuracy of 82.9% with only 22.2 GFLOPs of computation.
OctConv is not limited to image recognition.
Both 2D and 3D CNNs can achieve this improvement. The paper tested not only the image classification capabilities of 2D CNNs like ResNet, ResNeXt, DenseNet, MobileNet, and SE-Net on ImageNet, but also the performance changes of video action recognition algorithms like C2D and I3D after switching to OctConv.
Compressing Convolutions Like Compressed Images
Where does the computational power saved by OctConv come from?
For standard convolution operations, all input and output feature maps have the same spatial resolution.
In fact, an image can be divided into two parts: rough structure (low-frequency part) and edge details (high-frequency part). For instance, a penguin photo can be separated into two components:

The parts of the penguin with similar fur colors and the background with slow color changes belong to low-frequency information, which has less information; while the parts where two fur colors meet and the edges of the penguin’s body, where color changes are drastic, belong to high-frequency information, which has more information.
Given this, we can compress the low-frequency part, reducing redundant space.
Similarly, the output feature maps of convolutional layers can also be viewed as a mixture of different frequency information, allowing for similar processing.
Researchers were inspired by the frequency separation and compression of images. The idea of Octave Convolution is to perform similar operations on convolution networks, compressing low-frequency parts, processing high and low-frequency data separately, and exchanging information between the two, thereby reducing the storage and computational load of convolution operations.
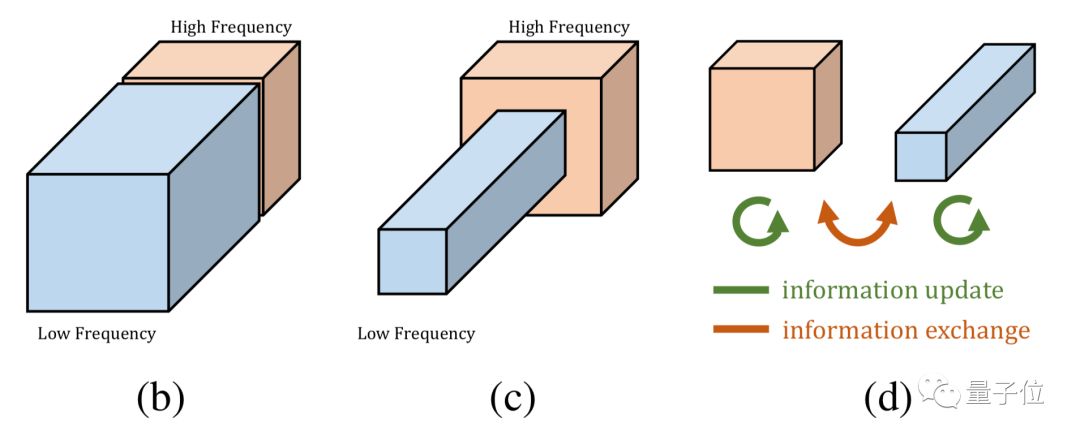
To adapt to the new feature representation, the article promotes traditional convolutions and proposes OctConv. Octave refers to the octave in music, where reducing an octave represents halving the frequency.
In OctConv, the size of the low-frequency part tensor is 0.5h×0.5w, which is exactly half the height and width of the high-frequency part h×w, thus saving tensor storage space and computational load.
Although OctConv compresses the information of the low-frequency part, it also effectively expands the receptive field in the original pixel space, which can improve recognition performance.
Implementation Process
For standard convolution methods, let W represent the k×k convolution kernel, and X and Y represent the input and output tensors respectively, with the mapping relationship between X and Y being:
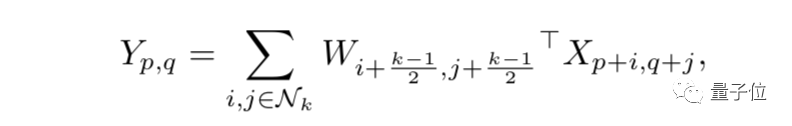
(p, q) are the position coordinates in the X tensor, and (i, j) indicates the range of neighboring points.
The goal of OctConv is to separately process the low-frequency and high-frequency parts of the tensor while achieving effective communication between the feature representations of high-frequency and low-frequency components.
We divide the convolution kernel into two components:
W=[WH, WL]
Thus, enabling effective communication between high and low frequencies. Therefore, the output tensor will also be divided into two components:
Y=[YH, YL]
YH=YH→H+YL→H, YL=YL→L+YH→L
Where YA→B indicates the updated result after feature mapping from A to B. YH→H and YL→L are information updates within frequency, while YL→H and YH→L are information updates between frequencies.
Thus, YH contains not only its own information processing but also the mapping from low frequency to high frequency.
To compute these terms, we further divide each component of the convolution kernel into frequency-internal and frequency-external parts:
WH=WH→H+WL→H, WL=WL→L+WH→L
The tensor parameters can be represented in a more visual way:
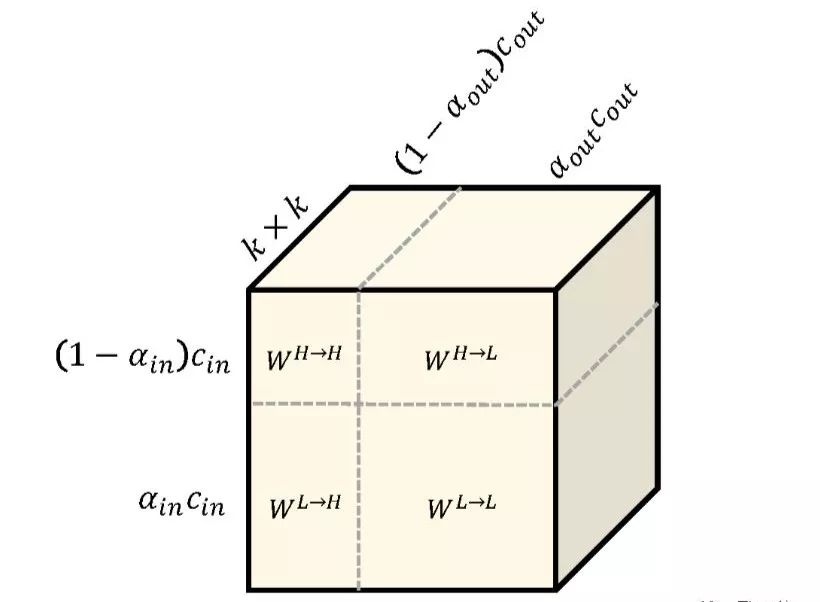
△OctConv’s convolution kernel
This form is somewhat similar to the complete square formula a^2+b^2+ab+ba, where the two square terms WH→H and WL→L are frequency-internal tensors, and the two cross terms are frequency-external tensors WL→H and WH→L.
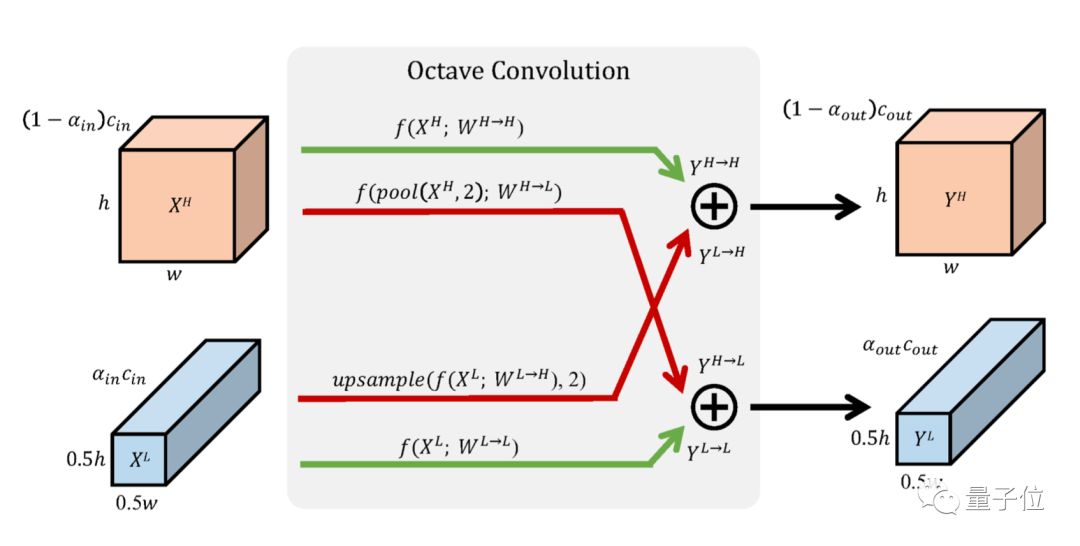
△The “cross” processing process of OctConv’s convolution kernel, with red arrows indicating information exchange between high and low frequencies
The calculation method of the output tensor is the same as that of ordinary convolution:
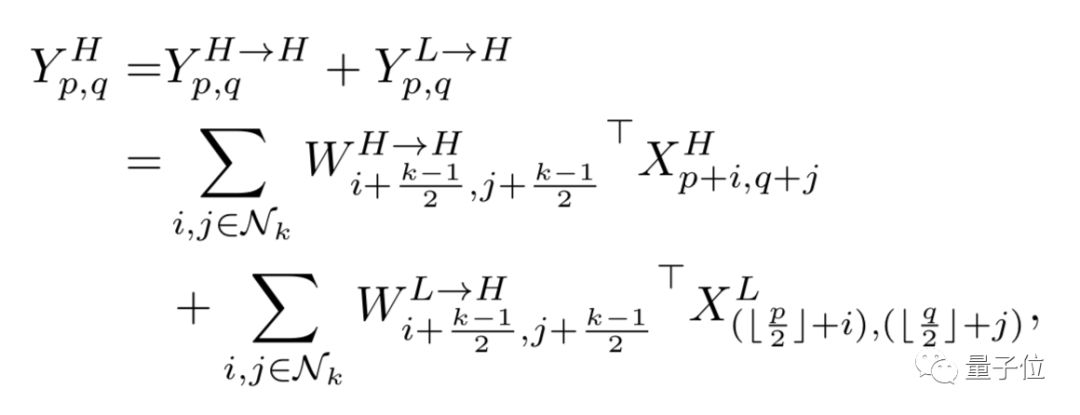
In OctConv, the ratio α is a tunable parameter, which is the adjustable parameter mentioned earlier. In all internal layers of the network, set αin = αout = α; in the first layer, αin = 0, αout = α; in the last layer, αin = α, αout = 0.
Another very useful feature of OctConv is that low-frequency feature mapping has a larger receptive field. Compared to ordinary convolution, it effectively doubles the receptive field. This further helps each OctConv layer capture more contextual information from afar, potentially improving recognition performance.
Chinese First Author
This paper was jointly completed by Facebook and the National University of Singapore.

The first author, Yunpeng Chen, graduated with a bachelor’s degree from Huazhong University of Science and Technology in 2015 and started interning at Facebook last year. Chen is currently pursuing a PhD at the National University of Singapore under the supervision of Shui-Cheng Yan and Jia-Shi Feng, both of whom are also authors of this paper. After graduating this year, Chen will become a researcher at Facebook.
Previously, as the first author, Chen has had 4 papers accepted at top conferences such as CVPR, NeurIPS, ECCV, and IJCAI, focusing on research in the intersection of deep learning and vision.

Shui-Cheng Yan, a tenured professor at the National University of Singapore, is also the Vice President of 360, Director of the Artificial Intelligence Research Institute, and Chief Scientist.
He mainly researches computer vision, machine learning, and multimedia analysis, with nearly 500 academic papers published and over 25,000 citations. He has been selected as a highly cited researcher globally three times. Currently, Yan holds many honors and is recognized as an IEEE Fellow, IAPR Fellow, and ACM Distinguished Scientist.

Jia-Shi Feng, currently an assistant professor in the Department of Electronic and Computer Engineering at the National University of Singapore, is the head of the Machine Learning and Vision Lab.
After graduating from the University of Science and Technology of China, Feng pursued a PhD at the National University of Singapore, followed by postdoctoral research at the AI Lab at UC Berkeley, focusing on image recognition, deep learning, and robust machine learning for big data.
Portal
Paper link: https://export.arxiv.org/abs/1904.05049
Editor: Huang Jiyan
Proofreader: Lin Yilin


Click “Read Original” to access the paper~