

This article is approximately 2600 words long and is recommended to be read in 9 minutes.
The SUPRA method significantly improves model stability and performance by replacing softmax normalization with GroupNorm.
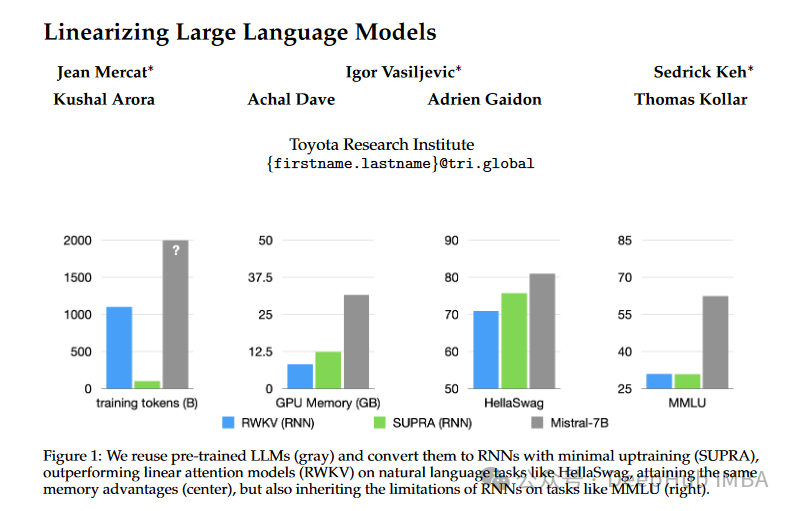
Transformers have established themselves as the primary model architecture, particularly due to their outstanding performance across various tasks. However, the memory-intensive nature of Transformers and the exponential increase in inference costs with the number of tokens present significant challenges. To address these issues, the paper “Linearizing Large Language Models” introduces an innovative approach called UPtraining for Recurrent Attention (SUPRA). This method leverages pre-trained Transformers and converts them into recurrent neural networks (RNNs), achieving efficient inference while retaining the benefits of pre-training.
The SUPRA method aims to transform pre-trained large language models (LLMs) into RNNs by replacing softmax normalization with GroupNorm and using a small MLP to project queries and keys. This approach not only reduces training costs (to just 5% of the original) but also harnesses the powerful performance and data of existing pre-trained models.
Transformers face high inference costs that grow linearly with sequence length. In contrast, RNNs provide fixed-cost inference because they maintain a constant-sized hidden state, making them attractive for tasks requiring efficient and scalable inference.
The introduction of linear Transformers alleviates the computational overhead of the standard softmax attention mechanism. Linear Transformers replace softmax with a linear similarity function, allowing them to operate like RNNs. However, in many benchmarks, linear Transformers still underperform compared to softmax due to stability issues and the complexity of pre-training.
Uptraining Method
Uptraining refers to the process of adapting a pre-trained model to a new architecture with minimal extra training, as opposed to fine-tuning, which typically involves retraining the model on different datasets. SUPRA specifically focuses on converting pre-trained Transformers to RNNs by modifying their attention mechanism.
The core of SUPRA lies in transforming the attention mechanism of Transformers into a recurrent form. The softmax attention is replaced by a linear function that allows for recurrent updates. This transformation is crucial as it enables the model to incrementally update its state, similar to RNNs.
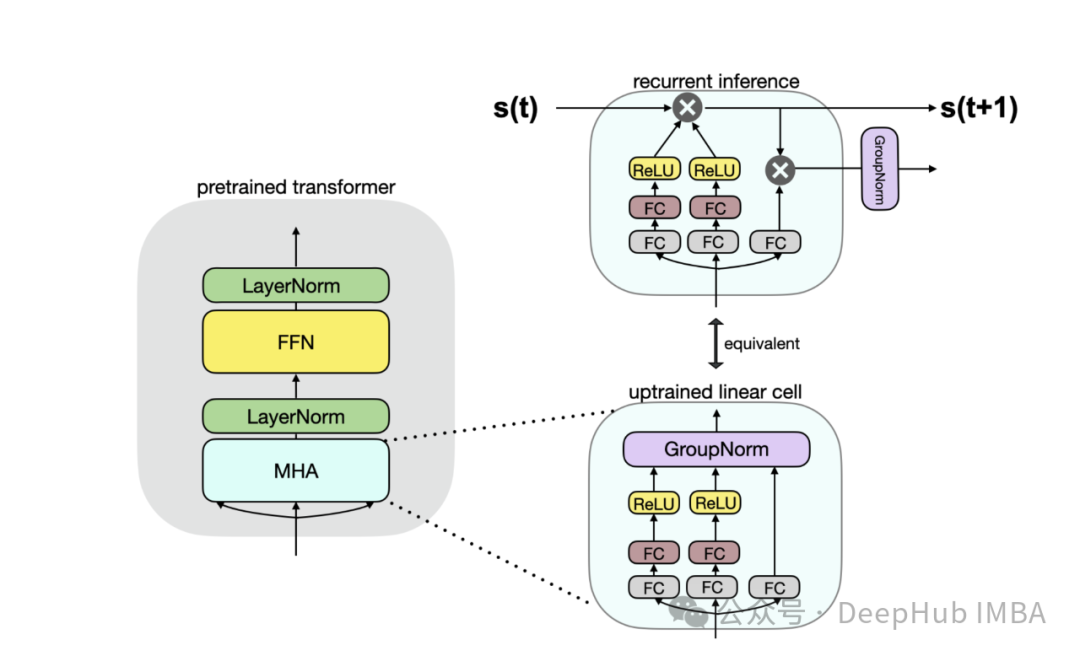
Using the transformed keys (k) and values (v) to update the recurrent state (s) and normalization factor (z) at each time step. These updates allow the model to process a sequence of tokens one at a time, significantly reducing inference costs.
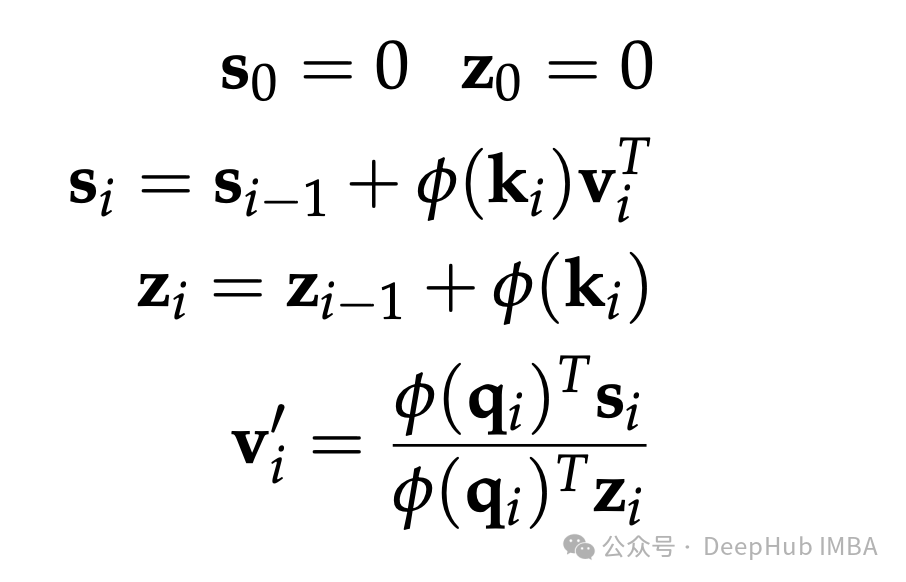
phi(x) is defined as:
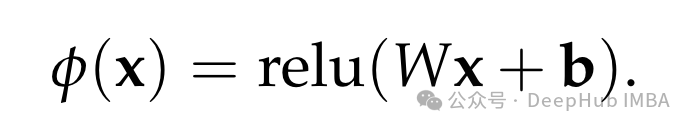
1. Initialize the recurrent state and normalization factor to zero.
2. For each token in the input sequence, compute the queries and keys using the learned weight matrices. Apply MLP and Rotational Position Embedding (RoPE) to these vectors to ensure they effectively handle sequential data.
3. Update the state and normalization factor using the transformed keys and values. The transformations applied by MLP appropriately adjust the keys and values.
4. Calculate the attention output for each time step by normalizing the dot product of the transformed queries and states. Apply GroupNorm to the output instead of traditional softmax normalization to enhance output stability.
Repeat the above steps for each token in the sequence to ensure the model processes the sequence in a recurrent manner.
Fine-tuning the Model
After using the above steps to convert Transformers to RNNs, fine-tune the model on a smaller dataset. This fine-tuning process adjusts the weights of the new components (MLP, GroupNorm, etc.) to optimize performance. This step requires only a small fraction of computational resources compared to pre-training from scratch.
Results Demonstration
Researchers tested the SUPRA method by scaling a series of models from 1B to 7B parameters (including Llama2 and Mistral models). These models were evaluated on standard language understanding benchmarks and long-context assessments to gauge their performance and limitations.
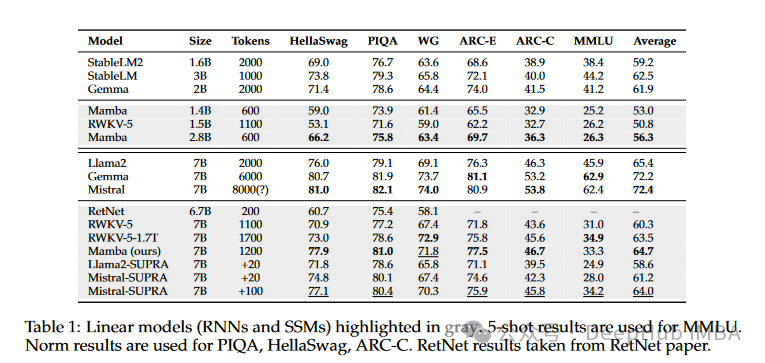
Using the Eleuther evaluation tool to assess standard natural language understanding (NLU) tasks. The initialized SUPRA models like Llama2-7B and Mistral-7B maintained high performance in most benchmarks, outperforming other linear models like RWKV-5.
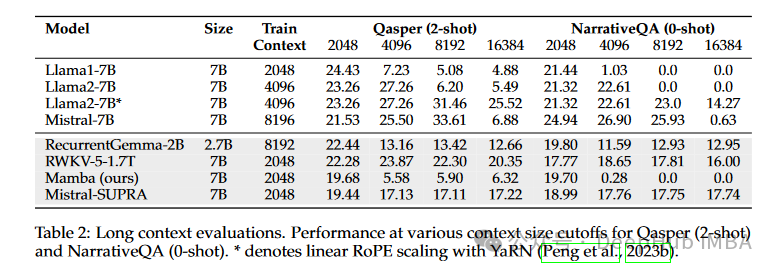
Due to the need to retain information over extended sequences, long-context tasks pose challenges for many models. The SUPRA models were evaluated on tasks from the SCROLLS benchmark (such as Qasper and NarrativeQA) across various context lengths. The performance of these models was compared to their training context lengths.
SUPRA models demonstrated the ability to maintain performance beyond their training context lengths, a typical characteristic associated with recurrent models. However, unmodified Transformers typically outperform SUPRA models at their maximum training context length. This indicates that while SUPRA models are effective, there is still room for improvement in handling very long contexts.
Main Arguments Explained
1. To what extent does the SUPRA method address performance deficiencies in long-context tasks?
The reason for performance deficiencies: A fixed decay vector γ was used, which performs well in short-context tasks but leads to a reduction in effective context length due to decay effects in long-context tasks, impacting performance. While the SUPRA method reduces inference costs by simplifying linear attention calculations, it still inherits the inherent shortcomings of linear models in long-context tasks. For example, linear models do not perform as well as softmax attention-based Transformer models in long-context modeling.
The paper suggests exploring more complex recurrent state update rules, such as gating strategies and higher-order linear attention, to improve performance in long-context tasks. Additionally, increasing training data specifically for long-context tasks may help enhance model performance on these tasks.
2. What are the specific impacts of replacing softmax normalization with GroupNorm on model stability and performance?
Softmax normalization can easily cause numerical instability during the training of large-scale models, especially when handling long sequence data. This instability is particularly pronounced in high-dimensional spaces. Replacing softmax normalization with GroupNorm can effectively mitigate this instability. GroupNorm reduces numerical fluctuations during model training by normalizing small batches of data within groups, thereby increasing training stability. Experiments in the paper indicate that the SUPRA model using GroupNorm exhibited more stable performance during the training of large-scale models (e.g., 7B parameter models), reducing interruptions and performance degradation caused by numerical instability.
Replacing softmax normalization with GroupNorm has a significantly positive impact on model stability and performance. Although performance may decline in some extremely long-context tasks, overall, this replacement performs well in improving training stability and maintaining performance. Future optimizations of GroupNorm usage could further enhance model performance across more tasks.
3. Can further optimization strategies (such as gating mechanisms) compensate for the SUPRA method’s shortcomings in context learning?
a. By introducing gating mechanisms, better control of information flow can be achieved, retaining important information while discarding unnecessary data, enhancing the model’s ability to model long contexts. Gating mechanisms can smooth the state update process, reducing gradient vanishing and explosion issues in long sequence data, thereby improving training stability.
b. Higher-order linear attention can capture richer feature interactions by introducing more complex kernel functions during attention calculation. By utilizing more complex kernel functions, more intricate feature interactions can be captured, enhancing the model’s expressive power and performance. Higher-order linear attention can more effectively handle long-context information, improving model performance on long-context tasks.
c. Dynamic position encoding methods (such as RoPE) can better handle positional information in long sequences. Dynamic position encoding enhances the model’s sensitivity to positional information in long sequences, improving long-context modeling capabilities. Dynamic position encoding can maintain stable performance across sequences of varying lengths, enhancing the model’s generalization ability.
Conclusion
The SUPRA method significantly enhances model stability and performance by replacing softmax normalization with GroupNorm. However, there are still certain deficiencies in handling long-context tasks. By introducing gating mechanisms, higher-order linear attention, specialized training data, task optimization, dynamic position encoding, and integrating other efficient attention mechanisms, the SUPRA method can be further optimized to address its shortcomings in context learning, enhancing the overall performance of the model.
Future research can continue to explore the combined application of these optimization strategies to further enhance model performance on long-context tasks, providing more possibilities for the development of the natural language processing field.
Paper link:
https://arxiv.org/abs/2405.06640
Source code:
https://github.com/tri-ml/linear_open_lm
Transformed model:
https://huggingface.co/TRI-ML/mistral-supra
Editor: Huang Jiyan
