
Author: Jaime Zornoza, Technical University of Madrid
Translation: Chen Zhiyan
Proofreading: Wang Weili
This article is approximately 3700 words, and it is recommended to read in 10+ minutes.
This article will help you understand deep learning neural networks in a way never seen before, and build a Chatbot using NLP!

Have you ever fantasized about being able to talk to your personal assistant or discuss any topic at will? Thanks to machine learning and deep neural networks, your past fantasies are quickly becoming reality. Let’s take a look at the magical features displayed by Apple’s Siri or Amazon’s Alexa.
Don’t get too excited; in the series of posts below, we are not creating an all-powerful AI, but rather creating a simple chatbot that can answer yes or no to questions related to pre-input information.
It is far from Siri or Alexa, but it demonstrates well that even with very simple deep neural network architectures, good results can be achieved. In this article, we will learn about Artificial Neural Networks, Deep Learning, Recurrent Neural Networks, and Long Short-Term Memory Networks. In the next article, we will utilize these concepts in a real project to answer questions.
Before we start discussing neural networks, take a close look at the image below. There are two images: one is a school bus driving down the road, and the other is an ordinary living room, both of which have been annotated by human annotators.

The images show two different pictures, annotated by human annotators.
Getting Started – Artificial Neural Networks
To build a neural network model for creating a chatbot, we will use a very popular neural network Python library: Keras. However, before diving deeper, we should first understand what an Artificial Neural Network (ANN) is.
An Artificial Neural Network is a machine learning model that attempts to mimic the functions of the human brain, constructed from a large number of interconnected neurons – hence the name “Artificial Neural Network.”
Perceptron
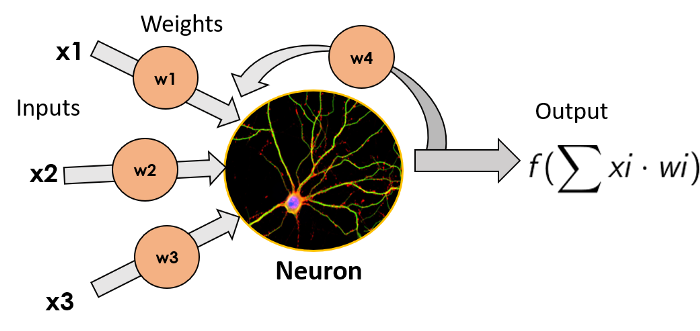
The simplest ANN model consists of a single neuron, which Star Trek named the Perceptron. It was invented by Frank Rosenblatt in 1957, consisting of a simple neuron that performs a function transformation on the weighted sum of inputs (which, in biological neurons, is performed by dendrites) and outputs its result (the output is equivalent to the axon of a biological neuron). We will not delve into the details of the function transformations used here, as the purpose of this article is not to become an expert, but simply to understand how neural networks work.
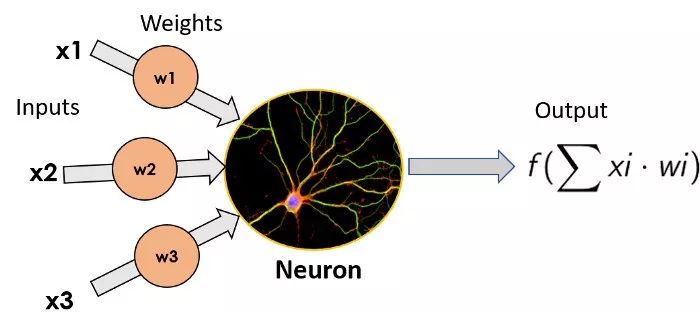
Image of a single neuron, with inputs on the left, multiplied by the weights of each input, the neuron applies a function transformation to the weighted sum of inputs and outputs the result.
These individual neurons can be stacked together to form layers containing different numbers of neurons, which can be placed sequentially adjacent to create a deeper network.
When a network is constructed in this manner, neurons that are not part of the input or output layers are called hidden layers, as their name describes: hidden layers are a black box model, which is one of the main features of ANNs. Typically, we have some understanding of the mathematical principles involved and what happens inside the black box, but if we try to understand it solely through the outputs of the hidden layers, our brains may not be sufficient.
Nevertheless, ANNs can produce good results, so no one complains about the lack of interpretability of these results.
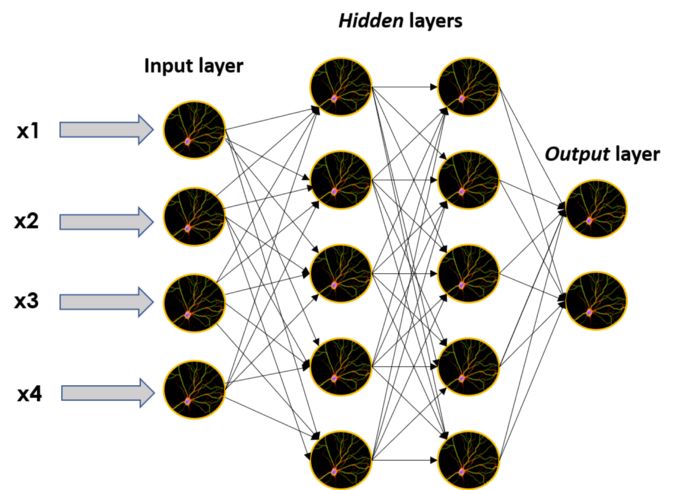
Image of a large neural network, consisting of many individual neurons and layers: one input layer, two hidden layers, and one output layer.
The structure of neural networks and how to train a neural network have been known for over twenty years. So, what has caused the current boom and hype surrounding artificial neural networks and deep learning? Below, we will provide an answer to this question, but first, let’s understand the true meaning of deep learning.
What is Deep Learning?
As the name suggests, deep learning uses multiple layers to gradually extract higher-level features from the data provided to the neural network. The principle is simple: use multiple hidden layers to enhance the performance of the neural model.
Once we understand this, the answer to the previous question becomes simple: scale. Over the past twenty years, the amount of available data of various types and the capabilities of our data storage and processing machines (i.e., computers) have grown exponentially.
The increase in computing power, along with the massive increase in the amount of available data for training models, has allowed us to create larger and deeper neural networks that outperform smaller neural networks.
Andrew Ng is one of the world’s leading experts in deep learning, and he made this point clear in this video. In this video (https://www.youtube.com/watch?v=O0VN0pGgBZM&t=576s), he shows an image similar to the one below and explains the advantages of using more data to train models, as well as the advantages of large neural networks compared to other machine learning models.
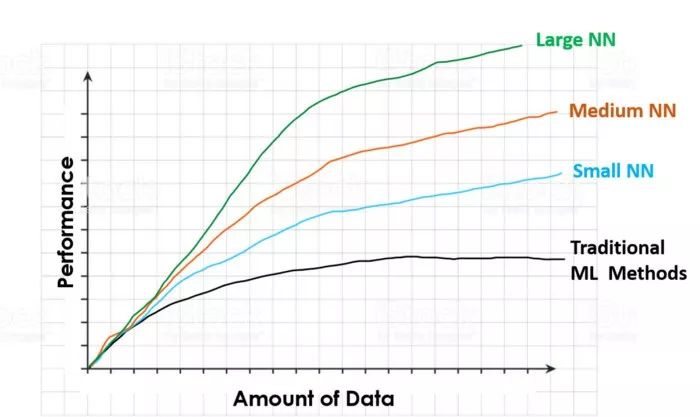
The image shows the performance evolution of different algorithms as the training dataset increases.
Traditional machine learning algorithms (such as linear or logistic regression, SVM, random forests, etc.) will see performance increase with the size of the training dataset, but once the dataset reaches a certain point, the performance of the algorithm will stop improving. Beyond this size, even if more data is provided to the model, traditional models do not know how to handle this additional data, and thus performance does not improve further.
Neural networks, on the other hand, never face this situation. The performance of neural networks always increases with the amount of data (provided the data quality is good), and as the size of the network increases, training speeds up. Therefore, to achieve optimal performance, one must be somewhere on the right side of the X-axis (high data volume) on the green line (large neural networks).
Moreover, while some algorithmic improvements are still needed, the main factors driving the rise of deep learning and artificial neural networks are scale: computational scale and data scale.
Jeff Dean (one of the pioneers of deep learning at Google) is another significant figure in this field, and regarding deep learning, Jeff said:
When I hear the term deep learning, I think of a large deep neural network. Deep usually refers to having many layers, which is a popular term in publications; at this moment, I consider it as deep neural networks.
When discussing deep learning, Jeff emphasizes the scalability of neural networks, meaning that as the amount of data increases and the model size increases, the output results improve, and the computational load for training also increases, which is consistent with the results seen earlier.
Now, having understood the principles, how does the neural network perform deep learning?
You might have guessed: neural networks learn from data.
Remember how we multiplied multiple inputs by weights and fed them into the perceptron? The “edges” (connections) connecting two different neurons also need to be weighted. This means that in a larger neural network, weights are also present in each black box edge, taking the output of one neuron, multiplying it, and then providing it as input to the next neuron connected by that edge.
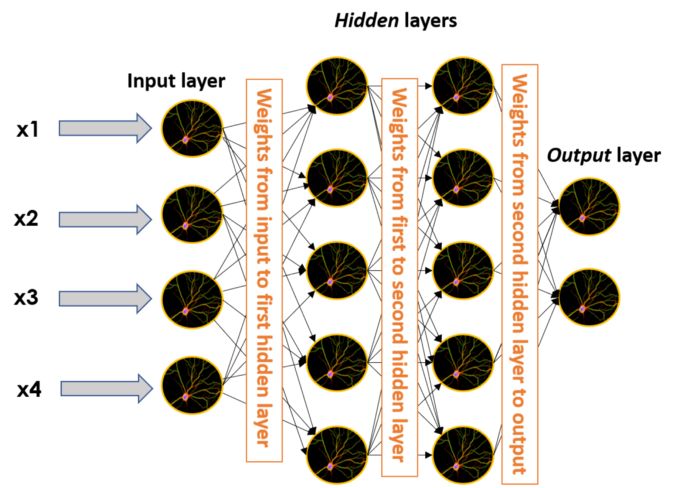
A neural network with two hidden layers and weights between each layer.
When training a neural network (training it to learn through ML expressions), we first provide it with a set of known data (referred to as labeled data in ML) and let it predict the features of this data (for example, labeling images as “dog” or “cat”) and then compare the predictions with the actual results.
When errors occur during this process, it adjusts the weights of the connections between neurons to reduce the number of mistakes made. For this reason, as shown earlier, in most cases, if we provide more data to the network, its performance will improve.
Learning from Sequential Data – Recurrent Neural Networks
Having understood artificial neural networks and deep learning, we now understand how neural networks learn, and we can start exploring the neural network used to build chatbots: Recurrent Neural Networks or RNNs.
Recurrent Neural Networks are a special type of neural network designed to effectively handle sequential data, which includes time series (a list of parameter values over a period), text documents (which can be viewed as sequences of words), or audio (which can be viewed as sequences of sound frequencies).
RNNs take the output from each neuron and feed it back as input; they not only receive new information at each time step but also add the weighted values of previous outputs to this new information, thus giving these neurons a kind of “memory” of previous inputs and somehow quantifying the feedback output to the neurons.
Recurrent neurons, output data multiplied by a weight and fed back into the input.
The function unit receiving input from previous time steps is called a memory unit.
The problem with RNNs is that as time goes on, they receive more and more new data, and they start to “forget” about the data by diluting new data through the activation function transformation and multiplication with weights. This means that RNNs have good short-term memory but still face some minor issues when trying to remember what happened a while ago (data from several previous time steps).
For this reason, some form of long-term memory is needed, and LSTMs provide the capability for long-term memory.
Enhancing Memory – Long Short-Term Memory Networks
Long Short-Term Memory Networks (LSTMs) are a variant of RNNs designed to solve the long-term memory problem of the latter. As a conclusion to this article, I will briefly explain how they work.
Compared to ordinary recurrent neural networks, they have a more complex memory unit structure, allowing them to better regulate how to learn from or forget different input sources.
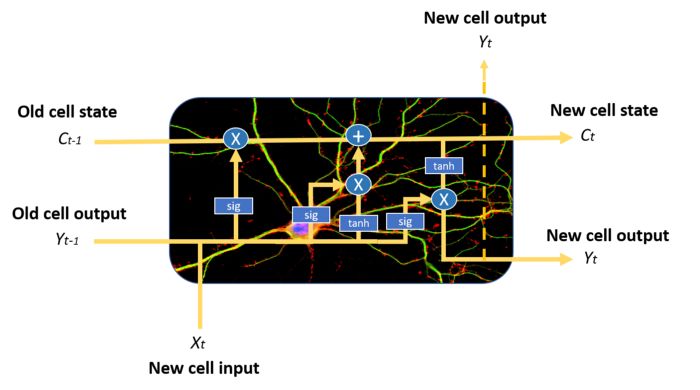
Example of an LSTM memory unit. Note the blue circles and squares, indicating that its structure is more complex than that of ordinary RNN units, which we will not elaborate on in this article.
LSTM neurons achieve this through the combination of states from three different gates: the input gate, the forget gate, and the output gate. At each time step, the memory unit can decide how to process the state vector: read from it, write to it, or delete it, thanks to a clear gating mechanism. Using the input gate, the memory unit can decide whether to update the unit’s state; using the forget gate, the memory unit can delete its memory; and through the output gate, the unit can decide whether the output information is available.
LSTMs can also mitigate the vanishing gradient problem, but this will not be detailed here.
That’s it! Now we have a basic understanding of these different types of neural networks, and we can start using them to build our first deep learning project!
Conclusion
Neural networks are truly amazing. In the next article, we will see that even a very simple structure with just a few layers can create a very powerful chatbot. Oh, by the way, do you remember this photo?

Two different images created by a neural network with brief text descriptions.
To prove how cool deep neural networks are, I must admit that I lied about how these images were generated.
Remember at the beginning of this article, it was stated that these descriptions were annotated by humans? In reality, the brief text on each image was actually generated by an artificial neural network.
If you want to learn how to use deep learning to create an amazing chatbot, please follow me on social media and stay tuned for my next article! Then, enjoy artificial intelligence!
Other Resources
The concepts described in this post are very introductory; for in-depth learning, please refer to the following additional resources.
-
How Neural Networks Work End-to-End
https://end-to-end-machine-learning.teachable.com/courses/how-deep-neural-networks-work/lectures/9533963
-
YouTube video series explaining the main concepts of training neural networks
https://www.youtube.com/watch?v=sZAlS3_dnk0
-
Deep Learning and Artificial Neural Networks
https://machinelearningmastery.com/what-is-deep-learning/
Alright, I hope you enjoyed this post. Feel free to connect with me on LinkedIn or follow me on Twitter at @jaimezorno. You can also check out my other posts on data science and machine learning here. Happy learning!
Jaime Zornoza is an industrial engineer with a bachelor’s degree in electronics and a master’s degree in computer science. Original. Reprinted with permission.
Original Title:
Deep Learning for NLP: ANNs, RNNs and LSTMs explained!
Original Link:
https://www.kdnuggets.com/2019/08/deep-learning-nlp-explained.html
Edited by: Huang Jiyan
Proofread by: Lin Yilin
Chen Zhiyan, graduated from Beijing Jiaotong University with a master’s degree in Communication and Control Engineering. Previously worked as an engineer at Great Wall Computer Software and Systems Company and Datang Microelectronics Company. Currently serves as technical support at Beijing Wuyi Super Translation Technology Co., Ltd. Engaged in the operation and maintenance of intelligent translation teaching systems, accumulating experience in artificial intelligence deep learning and natural language processing (NLP). In my spare time, I enjoy translation creation, with translated works including: IEC-ISO 7816, Iraq Oil Engineering Projects, New Fiscalism Declaration, etc., among which the Chinese to English translation of the “New Fiscalism Declaration” was officially published in GLOBAL TIMES. I hope to join the translation volunteer group of THU Data Hub in my spare time to exchange and share with everyone for mutual progress.
Translation Group Recruitment Information
Job Description: Requires a meticulous heart to translate selected foreign articles into fluent Chinese. If you are a data science/statistics/computer major student studying abroad, or working abroad in related fields, or confident in your foreign language skills, you are welcome to join the translation group.
What you can gain: Regular translation training to improve volunteer translation skills, enhance awareness of cutting-edge data science, and overseas friends can maintain contact with domestic technical application development. The background of THU Data Hub’s industry-university-research collaboration provides good development opportunities for volunteers.
Other Benefits: Data science professionals from well-known companies, students from Peking University, Tsinghua University, and other prestigious universities will become your partners in the translation group.
Click “Read Original” at the end to join the Data Hub team~
Reprint Notice
If you need to reprint, please prominently indicate the author and source at the beginning (Reprinted from: Data Hub ID: datapi), and place a prominent QR code of Data Hub at the end of the article. For articles with original identification, please send [Article Name – Awaiting Authorization Public Account Name and ID] to the contact email to apply for whitelist authorization and edit according to requirements.
After publication, please feedback the link to the contact email (see below). Unauthorized reprints and adaptations will be pursued legally.

Click “Read Original” to embrace the organization

