
Author丨JayLou
Zhihu Column丨High-energy NLP Journey
Address丨https://zhuanlan.zhihu.com/p/76912493
This article summarizes and compares pre-trained language models in NLP in a Q&A format, covering three main aspects and the following models:
-
Unidirectional feature representation autoregressive pre-trained language models, collectively referred to as unidirectional models:
-
ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0;
-
Bidirectional feature representation autoencoding pre-trained language models, collectively referred to as BERT series models:
-
(BERT/MASS/UNILM/ERNIE1.0/ERNIE(THU)/MTDNN/ERNIE2.0/SpanBERT/RoBERTa)
-
Bidirectional feature representation autoregressive pre-trained language models: XLNet;
Question List
-
Q1:How to compare【pre-trained language models】from different dimensions?
-
Q2:What are the feature extraction mechanisms based on deep learning in NLP? What are their advantages and disadvantages?
-
Q3:What are the advantages and disadvantages of autoregressive and autoencoding language models?
-
Q4:What is the core mechanism of unidirectional models? What are their disadvantages?
-
Q5:In-depth understanding of the internal mechanism of Transformer:
-
Why is it scaled dot-product instead of dot-product model?
-
What advantages does the dot-product model have compared to additive models?
-
Why is the multi-head mechanism effective?
-
Q6-Q10:Exploration of BERT’s core mechanism
-
Why is BERT so effective?
-
What are the advantages and disadvantages of BERT?
-
What downstream NLP tasks is BERT good at handling?
-
Is BERT based on “character input” or “word input” better? (For Chinese tasks)
-
Why is BERT not suitable for natural language generation tasks (NLG)?
-
Q11-Q15:Regarding the shortcomings of the original BERT model, the subsequent BERT series models are:
-
How to improve【generation tasks】?
-
How to introduce【knowledge】?
-
How to introduce【multi-task learning mechanisms】?
-
How to improve【masking strategies】?
-
How to perform【fine-tuning】?
-
Q16:What is the background of XLNet?
-
Q17:Why is XLNet so effective:
-
How can PLM achieve bidirectional context modeling?
-
How to solve the problem of lacking target (target) position information?
-
Q18:How does Transformer-XL model long texts?
Summary Table


Introduction
When Microsoft Research Asia celebrated its 20th anniversary, it stated: NLP will usher in a golden decade[1]. Looking back at the significant progress of NLP technology based on deep learning, the timeline mainly includes[2]:NNLM(2003), Word Embeddings(2013), Seq2Seq(2014), Attention(2015), Memory-based networks(2015), Transformer(2017), BERT(2018), XLNet(2019):
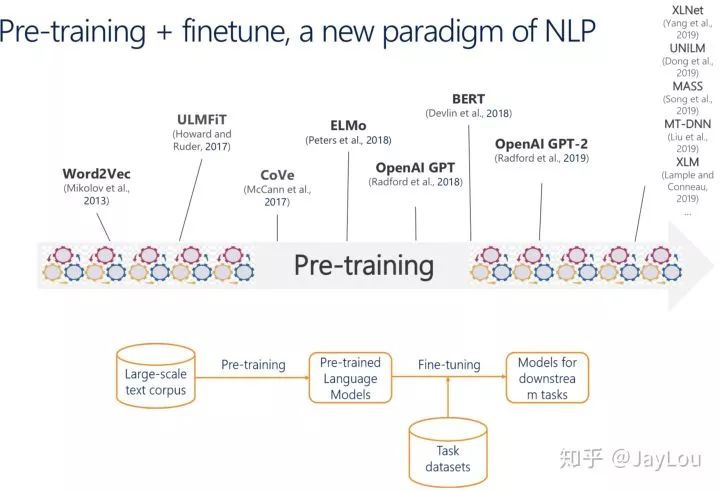
The main trends in NLP progress at ACL2019 include[3]: pre-trained language models, low-resource NLP tasks (transfer learning/semi-supervised learning/multi-task learning/active learning), model interpretability, more tasks & datasets. This article mainly introduces the progress in the NLP field from the perspective of【pre-trained language models】.【Pre-trained language models】 have formed a new NLP paradigm[4]: using large-scale text corpora for pre-training and fine-tuning on small datasets for specific tasks, reducing the difficulty of individual NLP tasks.
The essence of the pre-training idea is that model parameters are no longer randomly initialized but are pre-trained through some tasks (such as language models); pre-training falls under the category of transfer learning, and the【pre-trained language models】 discussed in this article mainly refer to unsupervised pre-training tasks (sometimes also called self-learning or self-supervised), with the transfer paradigm mainly being feature integration and fine-tuning.
Language models represent the joint probability distribution of sequential text, and to reduce the difficulty of estimating probabilities for long texts, a simplified n-gram model is usually used[5]. To alleviate the data sparsity problem encountered in estimating probabilities for n-gram language models, the neural network language model NNLM was proposed, where the first layer parameters can be used for word vector representation. Word vectors can be seen as a byproduct of NNLM, while word2vec focuses on the generation of word vectors through various optimization techniques, and the later glove word vectors are generated through efficient decomposition of co-occurrence corpus matrices, glove can also be seen as a global word2vec with a changed objective function and weight function. Since static word vectors like word2vec and glove do not consider polysemy and cannot understand complex contexts, contextually relevant feature representations (dynamic word vectors) can be produced through pre-trained language models.
(Note: This article does not include word2vec in the category of pre-trained language models, although word2vec can be seen as a language model, it focuses more on the generation of word vectors. The pre-trained language models discussed in this article mainly refer to those capable of producing contextually relevant feature representations.)
With ELMO/GPT/BERT and other pre-trained language models achieving SOTA results in NLP tasks, a series of new methods have been developed, such as MASS, UNILM, ERNIE1.0, ERNIE(THU), MTDNN, ERNIE2.0, SpanBERT, RoBERTa, XLNet, XLM, etc. Pre-trained language models have driven the advancement of NLP technology and attracted widespread attention.
This article introduces【pre-trained language models】 from the following aspects:
1. Comparison of pre-trained language models from different perspectives2. Basics of pre-trained language models: Feature extraction mechanisms + classification of language models3. Review of unidirectional models + exploration of core mechanisms4. Exploration of BERT’s core mechanism5. Introduction to the progress of BERT series models6. Exploration of XLNET’s core mechanism7. The future of pre-trained language models
1. Comparison of Pre-trained Language Models from Different Perspectives
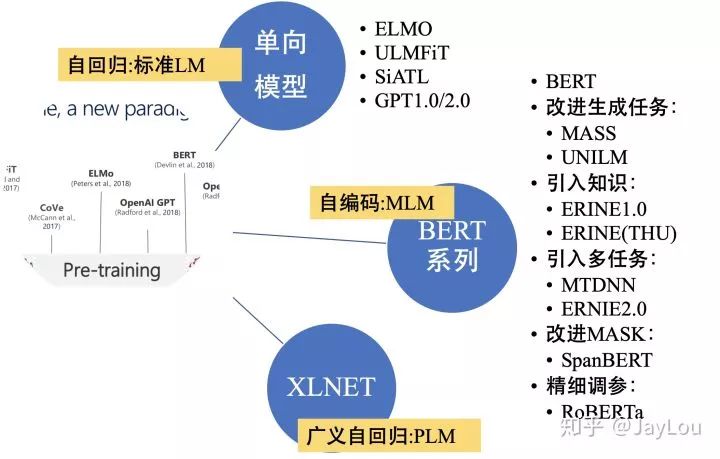
Q1:How to compare【pre-trained language models】from different dimensions
Comparing pre-trained language models from four perspectives: feature extraction, pre-trained language model objectives, improvement directions of BERT series models, and feature representations:
-
Different feature extraction mechanisms
-
RNNs:ELMO/ULMFiT/SiATL;
-
Transformer:GPT1.0/GPT2.0/BERT series models;
-
Transformer-XL:XLNet;
-
Different pre-trained language objectives
-
AutoEncode: BERT series models;
-
AutoRegression: Unidirectional models (ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0) and XLNet;
-
Improvements in BERT series models
-
Incorporating common sense: ERNIE1.0/ERNIE(THU)/ERNIE2.0 (referred to as “ERNIE series”);
-
Introducing multi-task learning: MTDNN/ERNIE2.0;
-
Improvements based on generation tasks: MASS/UNILM;
-
Different masking strategies: WWM/ERNIE series/SpanBERT;
-
Fine-tuning: RoBERTa;
-
Feature representation (whether it can represent context):
-
Unidirectional feature representation: Unidirectional models (ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0);
-
Bidirectional feature representation: BERT series models + XLNet;
2. Basics of Pre-trained Language Models: Feature Extraction Mechanisms + Classification of Language Models
Q2:What are the feature extraction mechanisms based on deep learning in NLP? What are their advantages and disadvantages?
1) Can handle long-distance dependencies
Long-distance dependency modeling capability: Transformer-XL > Transformer > RNNs > CNNs
-
MLP: Does not consider sequential (positional) information, cannot handle variable-length sequences, such as NNLM and word2vec;
-
CNNs: Considers sequential (positional) information, cannot handle long-distance dependencies, focuses on n-gram extraction, pooling operations can lead to loss of sequential (positional) information;
-
RNNs: Naturally suitable for handling sequential (positional) information, but still cannot handle long-distance dependencies (due to issues like gradient disappearance caused by BPTT), hence also called “long short-term memory units (LSTM)”;
-
Transformer/Transformer-XL: Self-attention solves long-distance dependencies, no positional bias;
2) Feedforward/Recurrent networks or serial/parallel computation
-
MLP/CNNs/Transformer: Feedforward/parallel
-
RNNs/ Transformer-XL: Recurrent/serial:
3) Computational time complexity (sequence length n, embedding size d, filter size k)
-
CNNs:

-
RNNs:

-
Self Attention:

Q3:What are the advantages and disadvantages of autoregressive and autoencoding language models?
1. Autoregressive language models
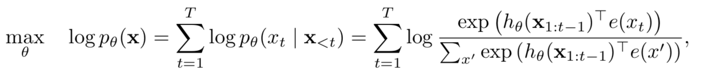
-
Advantages:
-
Density estimation of joint probabilities of text sequences, which is the traditional language model, naturally suitable for handling natural generation tasks;
-
Disadvantages:
-
Joint probabilities are decomposed from left to right according to the text sequence (sequential decomposition), and cannot perform bidirectional feature representation through contextual information;
-
Representative models: ELMO/GPT1.0/GPT2.0;
-
Improvements: XLNet extends the traditional autoregressive language model by changing sequential decomposition to random decomposition (permutation language model), producing contextually relevant bidirectional feature representations;
2. Autoencoding language models
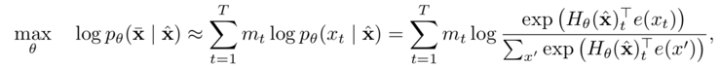
-
Advantages: Essentially a denoising autoencoding feature representation, obtaining contextually relevant bidirectional feature representations by introducing noise [MASK] to construct MLM;
-
Introduces independence assumptions for biased estimates of joint probabilities, not considering the correlation between predicted [MASK];
-
Not suitable for directly handling generation tasks, the MLM pre-training objective causes inconsistencies between the pre-training and generation processes;
-
The [MASK] noise during pre-training will not appear during the fine-tuning phase, leading to mismatches between the two phases;
-
Representative models: BERT series models;
3. Review of Unidirectional Models + Exploration of Core Mechanisms
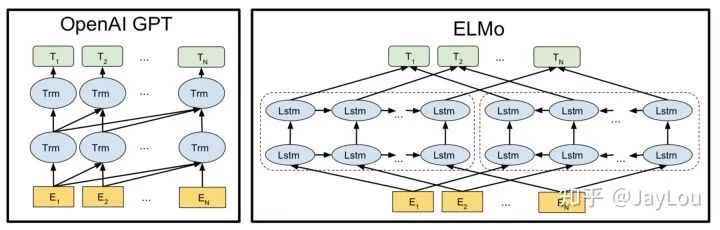
Q4:What is the core mechanism of unidirectional models? What are their disadvantages?
1. ELMO (University of Washington)[6]
-
Main points:
-
Introduces bidirectional language models, which are actually an integration of two unidirectional language models (forward and backward);
-
By saving the pre-trained 2-layer biLSTM, applying feature integration or fine-tuning to downstream tasks;
-
Disadvantages:
-
Essentially an autoregressive language model, can only obtain unidirectional feature representations, cannot simultaneously obtain contextual representations;
-
LSTM cannot solve long-distance dependencies.
-
Why can’t biLSTM be used to construct bidirectional language models?
-
Cannot use 2-layer biLSTM to simultaneously extract features to construct bidirectional language models, otherwise there will be a label leakage issue; therefore, the parameters of ELMO’s forward and backward LSTMs are independent, sharing word vectors, and independently constructing language models;

2. ULMFiT/SiATL
-
ULMFiT[7] main points:
-
3 stages: LM pre-training + fine-tuning specific task LM + fine-tuning specific classification task;
-
Feature extraction: 3-layer AWD-LSTM;
-
Fine-tuning specific classification tasks: gradually unfreeze;
-
SiATL[8] main points:
-
2 stages: LM pre-training + specific task fine-tuning classification task (introducing LM as an auxiliary objective, auxiliary objectives are useful for small data, contrary to GPT);
-
Feature extraction: LSTM+self-attention;
-
Fine-tuning specific classification tasks: gradually unfreeze;
-
Both solve the catastrophic forgetting problem during the fine-tuning process through some techniques: if the unsupervised data used for pre-training and the task data are from different domains, the effects brought by gradual unfreezing are more significant[9];
3. GPT1.0/GPT2.0 (OpenAI)
-
GPT1.0[10] main points:
-
Uses Transformer for feature extraction, being the first to apply Transformer to pre-trained language models;
-
During the fine-tuning phase, introduces language model auxiliary objectives (auxiliary objectives are useful for large datasets, small data may decrease, contrary to SiATL), solving the catastrophic forgetting problem during fine-tuning;
-
Pre-training and fine-tuning are consistent, unifying the two-stage framework;
-
GPT2.0[11] main points:
-
Does not have a specific fine-tuning process for the model: GPT2.0 believes that the pre-training already contains much of the information needed for specific tasks.
-
Achieves good results in generation tasks, using broader and higher-quality data;
-
Disadvantages:
-
Still a unidirectional autoregressive language model, cannot obtain contextually relevant feature representations;
4. Exploration of BERT’s Core Mechanism
This section introduces BERT’s core mechanism, before answering “Why is BERT so effective?” we first introduce the core mechanism of Transformer.
Q5:In-depth understanding of the internal mechanism of Transformer[12]
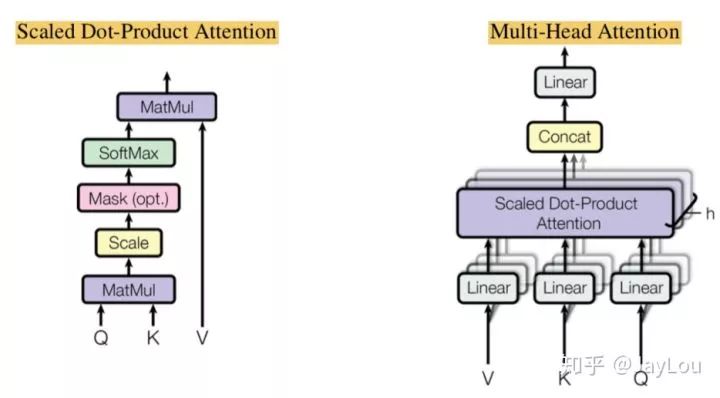
1. Multi-Head Attention and Scaled Dot-Product Attention:
Essentially, self-attention dynamically encodes variable-length sequences through attention masks, solving long-distance dependencies, no positional bias, and allowing parallel computation;
-
Why is it scaled dot-product instead of dot-product model?
-
When the dimensionality of input information d is relatively high, the values of the dot-product model usually have a relatively large variance, leading to smaller gradients of the softmax function. Therefore, the scaled dot-product model can solve this problem better.
-
Why is it a bilinear dot-product model (after linear transformation Q
 K)?
K)? -
Bilinear dot-product model introduces asymmetry, making it more robust (the diagonal elements of the attention mask may not be the largest, meaning that the attention score of the current position to itself may not be the highest).
-
What advantages does the dot-product model have compared to additive models?
-
The commonly used attention mechanisms are additive models and dot-product models, theoretically the complexities of both are similar, but the dot-product model can utilize matrix multiplication better in implementation, resulting in higher computational efficiency (in fact, as the dimensionality d increases, the additive model will be significantly better than the dot-product model).
-
Why is the multi-head mechanism effective?
-
Similar to the multi-channel feature selection in CNN;
-
In Transformer, first split and then perform Scaled Dot-Product Attention separately, allowing the dimensionality d for dot-product computation to be small (preventing gradient disappearance) while reducing the attention mask matrix.
2. Position-wise Feed-Forward Networks:
-
FFN maps the results of Multi-Head Attention at each position to a larger dimensional feature space, then uses ReLU to introduce non-linearity for selection, and finally recovers back to the original dimension.
-
After abandoning the LSTM structure, ReLU in FFN becomes a major unit providing non-linear transformations.
3. Positional Encoding:
Positional Embedding is changed to Positional Encoding, the main difference is that Positional Encoding is expressed by formulas and is non-learnable, while Positional Embedding is learnable (like BERT), the training speed and model accuracy differences between the two schemes are not significant; however, the positional encoding range of Positional Embedding is fixed, while the encoding range of Positional Encoding is unlimited.
-
Why introduce
 and
and  to model Positional Encoding?
to model Positional Encoding?

-
Introducing
 and
and  is to enable the model to learn about relative positions, the positional encodings of two positions pos and pos+k are linearly varied with a fixed interval k:
is to enable the model to learn about relative positions, the positional encodings of two positions pos and pos+k are linearly varied with a fixed interval k: 
-
It can be proven: The Euclidean spatial distance of any two positional encodings with an interval of k is constant and only related to k.

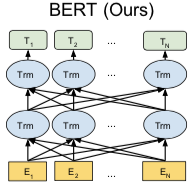
Q6:Why is BERT[13] so effective?
-
Introduces the Masked Language Model (MLM) pre-training objective, which can obtain contextually relevant bidirectional feature representations;
-
Introduces the Next Sentence Prediction (NSP) pre-training objective, excelling at sentence or paragraph matching tasks;
-
Incorporates a powerful feature extraction mechanism, Transformer (multiple mechanisms coexist):
-
Multi-Head self-attention: The multi-head mechanism is similar to “multi-channel” feature extraction, self-attention dynamically encodes variable-length sequences through attention masks, solving long-distance dependencies (no positional bias), allowing parallel computation;
-
Feed-forward: Computes non-linear hierarchical features in the positional dimension;
-
Layer Norm & Residuals: Accelerates training and makes the “deep” network more robust;
-
Introduces large-scale, high-quality text data;
Note:
-
BERT applies different transfer learning methods to downstream tasks, especially excels at NLU tasks;
-
BERT solves the “label leakage” problem in constructing bidirectional language models with deep biLSTM through MLM, which is to “see itself”;
Q7:What are the advantages and disadvantages of BERT?
-
Advantages: Able to obtain contextually relevant bidirectional feature representations (the biggest highlight of BERT);
-
Disadvantages:
-
Poor performance in generation tasks: Inconsistencies between the pre-training and generation processes lead to poor performance in generation tasks;
-
Independence assumptions: Not considering the correlation between predicted [MASK], leading to a biased estimate of the joint probability of the language model (not density estimation);
-
Input noise [MASK], causing differences between the pre-training and fine-tuning phases;
-
Not suitable for document-level NLP tasks, only suitable for sentence and paragraph-level tasks;
Q8:What downstream NLP tasks is BERT good at handling[14]?
-
Suitable for sentence and paragraph-level tasks, not suitable for document-level tasks (such as long text classification);
-
Suitable for tasks that text language itself can handle well (such as QA/machine reading comprehension), not relying on additional features (such as recommendation search scenarios);
-
Suitable for tasks that extract high-level semantic information, not significantly improving tasks that extract shallow semantic information (such as text classification/NER, text classification focusing on “keywords” as shallow semantic extraction);
-
Suitable for sentence/paragraph matching tasks, because BERT introduces NSP in the pre-training task; therefore, in some tasks, auxiliary sentences can be constructed (similar to matching tasks) to achieve performance improvement (such as relation abstraction/sentiment mining tasks);
-
Not suitable for NLG tasks, as BERT performs poorly in generation tasks;
Q9:Is BERT based on “character input” or “word input” better? (For Chinese tasks)
-
If based on “word input”, it will lead to OOV problems, increasing the label space, requiring more corpus to learn label distribution to fit the model.
-
With the feature extraction capability of Transformer, tokenization is no longer necessary, and word-level feature learning can be incorporated into internal feature representation.
Q10:Why is BERT not suitable for natural language generation tasks (NLG)?
-
Due to the inconsistencies between the pre-training process and generation process of BERT, there is no corresponding mechanism for generation tasks, leading to poor performance in generation tasks, cannot be directly applied to generation tasks.
-
If BERT or GPT is used for Seq2Seq natural language generation tasks, pre-training can be done for the encoder and decoder separately, but the encoder-attention-decoder structure is not jointly trained, BERT and GPT only perform sub-optimally in conditional generation tasks.
5. Introduction to the Progress of BERT Series Models
This section introduces some models, all of which are improvements on the original BERT model in some directions.
Q11:How do the subsequent BERT series models improve【generation tasks】?
1. MASS (Microsoft)[15]
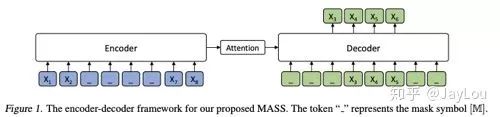
-
Unified pre-training framework: through a similar Seq2Seq framework, unifying BERT and LM models in the pre-training phase;
-
Understanding unmasked tokens in the encoder; In the decoder, it is necessary to predict consecutive [mask] tokens, obtaining more language information; The decoder extracts more information from the encoder;
-
When k=1 or n, the probability forms of MASS are consistent with MLM in BERT and standard LM in GPT (k is the length of the consecutive masked segment).
2. UNILM (Microsoft)[16]:
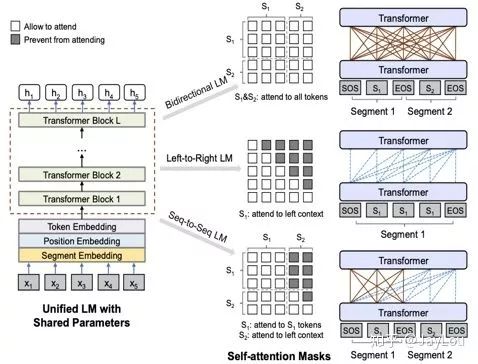
-
Unified pre-training framework: and unify BERT and LM from the perspective of the mask matrix;
-
3 attention mask matrices: LM, MLM, Seq2Seq LM;
-
Note: In UNILM, LM is not a traditional LM model, but still achieved through introducing [MASK];
Q12:How do the subsequent BERT series models introduce【knowledge】?
1. ERNIE 1.0 (Baidu)[17]:
-
Introduces knowledge (actual pre-identified entities) during the pre-training phase, introducing three types of [MASK] strategies for prediction:
-
Basic-Level Masking: Like BERT, masking subwords, unable to obtain high-level semantics;
-
Phrase-Level Masking: Masking consecutive phrases;
-
Entity-Level Masking: Masking entities;
2. ERNIE (THU)[18]:
-
Based on the original BERT pre-training model, aligning entities in the text with external knowledge graphs, and obtaining entity vectors as inputs for ERNIE through knowledge embedding;
-
Due to the significant differences in the pre-training process of language representation and knowledge representation, two independent vector spaces will be generated. To solve this problem, at positions with entity inputs, the entity vectors and text representations are fused through non-linear transformation to integrate lexical, syntactic, and knowledge information;
-
Introduces an improved pre-training objective Denoising entity auto-encoder (DEA): Requires the model to predict the corresponding entity based on the given entity sequence and text sequence;
Q13:How do the subsequent BERT series models introduce【multi-task learning mechanisms】?
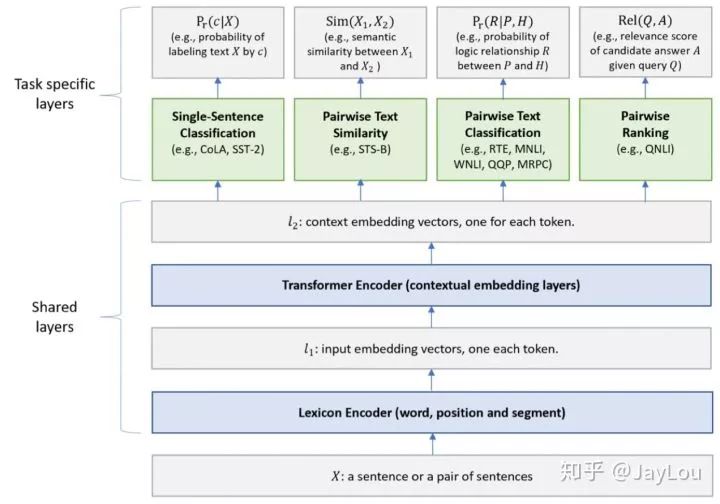
Multi-task learning (Multi-task Learning)[19] refers to simultaneously learning multiple related tasks, allowing these tasks to share knowledge during the learning process and using the correlations between multiple tasks to improve model performance and generalization ability. Multi-task learning can be seen as a form of inductive transfer learning, using information contained in related tasks as inductive bias to enhance generalization ability. The training mechanism of multi-task learning can be divided into simultaneous training and alternating training.
1. MTDNN (Microsoft)[20]: Introduces multi-task learning mechanisms in downstream tasks
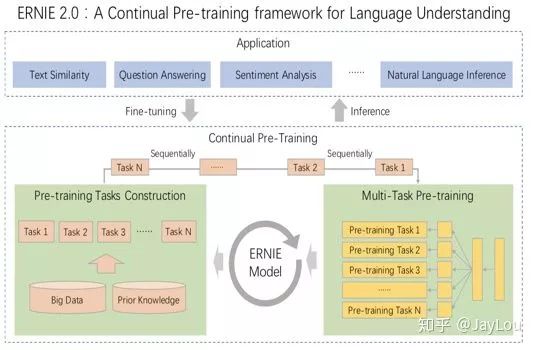
2. ERNIE 2.0 (Baidu)[21]:
-
MTDNN introduces multi-task mechanisms in downstream tasks, while ERNIE 2.0 introduces multi-task learning during pre-training (interacting with prior knowledge bases), allowing the model to learn more linguistic knowledge from different tasks.
-
It mainly includes three aspects of tasks:
-
word-aware tasks: Capturing vocabulary-level information;
-
structure-aware tasks: Capturing syntactic-level information;
-
semantic-aware tasks: Capturing semantic-level information;
-
The main approach is to build incremental learning models (which can continuously introduce more tasks), and the multi-task learning continuously updates the pre-trained model, this continuous alternating learning paradigm will not cause the model to forget previously learned linguistic knowledge.
-
Training several sub-tasks together from the three categories, when introducing new tasks, will continue to include previous tasks to prevent forgetting previously learned knowledge, specifically a process of gradually increasing the number of tasks[22]:(task1)->(task1,task2)->(task1,task2,task3)->…->(task1,task2,…,taskN),
Q14:How do the subsequent BERT series models improve【masking strategies】?
-
Original BERT model: Masks according to subword dimensions, then predicts;
-
BERT WWM (Google): Masks according to whole word dimensions, then predicts;
-
ERNIE and other series: Introduces external knowledge, masks according to entity dimensions, then predicts;
-
SpanBert: Does not need to mask according to prior word/entity/phrase boundaries, but instead adopts random masking:
-
Uses Span Masking: Randomly selects a segment of spatial length based on geometric distribution, then randomly selects a starting position based on uniform distribution, and finally masks according to length; The average masked length through sampling is 3.8 words;
-
Introduces Span Boundary Objective: The new pre-training objective aims to enable the masked span boundary’s word vectors to learn the masked parts within the span; The new pre-training objective is used together with MLM;
-
Note: BERT WWM, ERNIE and other series, SpanBERT aim to implicitly learn the relationships between predicted words (the strong correlation of the masked parts themselves), while in XLNet, the relationship between predicted words is explicitly learned through PLM plus autoregressive methods;
Q15:How do the subsequent BERT series models perform【fine-tuning】?
RoBERTa (Facebook):[24]
-
Discards NSP, performs better;
-
Dynamic changes in masking strategies, copying data 10 times, then uniformly performing random masking;
-
Adjustments to peak learning rates and warm-up update steps;
-
Trains on longer sequences: Does not truncate sequences, uses full-length sequences;
6. Exploration of XLNet’s Core Mechanism
Following the BERT series models, Google’s XLNet significantly surpasses BERT in tasks such as question answering, text classification, and natural language understanding; The introduction of XLNet is a revival of standard language models (autoregressive), proposing a framework to connect language modeling methods and pre-training methods.
Q16:What is the background of XLNet[26]?
-
Pre-trained models like ELMO, GPT are based on traditional language models (autoregressive language models AR), autoregressive language models are naturally suitable for handling generation tasks, but cannot represent bidirectional contexts, thus people have turned to research on self-encoding ideas (like BERT series models);
-
Self-encoding language models (AE) can represent bidirectional contexts, but:
-
BERT series models introduce independence assumptions, not considering the correlation between predicted [MASK];
-
The MLM pre-training objective’s setup causes inconsistencies between the pre-training and generation processes;
-
The [MASK] noise during pre-training will not appear during the fine-tuning phase, leading to mismatches between the two phases;
-
Is there a way to construct a model that has the advantages of both AR and AE without their disadvantages?
Q17:Why is XLNet so effective: Core mechanism analysis

1. Permutation Language Model (PLM):
If measuring the number of dependencies modeled in the sequence, standard LM can reach the upper limit, unlike MLM, LM does not rely on any independence assumptions. Drawing from the idea of NADE[27], XLNet extends the standard LM to PLM.
-
Why can PLM achieve bidirectional context modeling?
-
PLM essentially reflects multiple decomposition mechanisms of joint probabilities of LM;
-
It generalizes the sequential decomposition of LM to random decomposition while retaining the original positional information of each word (PLM is merely a factorization/permutation of language model modeling methods, not a rearrangement of word positional information!);
-
If traversing T! decomposition methods and model parameters are shared, PLM can definitely learn various bidirectional contexts; In other words, when considering all possible T! permutations, all contexts for predicting words can be learned!
-
Due to the massive computational load of traversing T! paths (for a 10-word sentence, 10!=3628800), it can only randomly sample parts of T! and compute expectations;
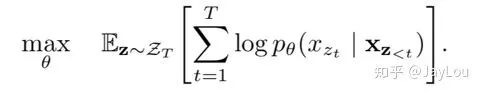
2. Two-Stream Self-Attention
If using standard Transformer to model PLM, there will be issues with lacking target position information. The key issue is that the model does not know which position’s word to predict, causing the probabilities of PLM under partial permutations to be the same when predicting different target words.

-
How to solve the problem of lacking target position information?
-
To address the lack of target position information, XLNet introduces Two-Stream Self-Attention:

-
The Query stream is solely for predicting the current word, containing positional information but not content information of the words;
-
The Content stream provides the Query stream with content vectors of other words, containing positional and content information;
3. Incorporating the advantages of Transformer-XL (see Q18)
Q18:How does Transformer-XL model long texts?[28]
-
BERT (Transformer) has a maximum input length of 512, so how to model document-level texts?
-
Vanilla model performs segmentation but will have the problem of contextual fragmentation (unable to model the semantic information of continuous documents), and requires repeated computations during inference, making inference slow;
-
Improvements of Transformer-XL
-
Introduces a recurrence mechanism (not using BPTT for backpropagation):
-
The representation calculated from the previous segment is fixed and cached, so it can be resumed as extended context when the model processes the next new segment;
-
The maximum possible dependency length increases by N times, where N represents the network depth;
-
Solves the contextual fragmentation problem, providing necessary context for tokens before the new segment;
-
As it does not require repeated calculations, Transformer-XL is over 1800 times faster than vanilla Transformer during evaluation on language modeling tasks;
-
Introduces a relative position encoding scheme:
-
Each segment should have different positional encodings, thus Transformer-XL adopts relative position encoding;

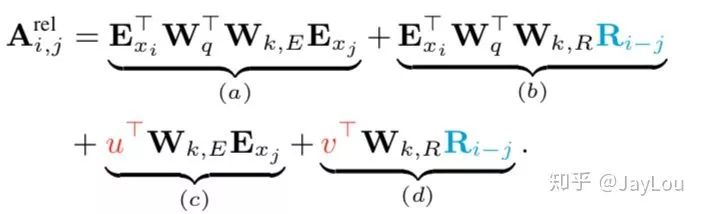
7. The Future of Pre-trained Language Models
The aforementioned【pre-trained language models】 are mainly introduced from two aspects: First is the overall comparison; Second is the introduction of unidirectional language models, BERT series models, and XLNet models.
It can be seen that the future of【pre-trained language models】 will focus on more exploration directions mainly include[25]:
-
Reviving language models: Further improving language model objectives, continuously breaking through the upper limits of models;
-
Big data, big computing power: Pushing big data and big computing power to the extreme;
-
Faster inference: Is it possible for lightweight models to achieve SOTA performance?
-
Introducing richer knowledge information, more refined tuning, and more valuable MASK strategies;
-
Unified conditional generation task framework, such as unifying encoding and decoding tasks based on XLNet, while considering faster decoding methods;
(End)
1. This article will continue to focus on【pre-trained language models】 and update new models; 2. If there are any errors or shortcomings, please point them out; Without permission, reproduction is not allowed.)
References
-
^NLP will usher in a golden decade https://www.msra.cn/zh-cn/news/executivebylines/tech-bylines-nlp
-
^a review of the recent history of nlp
-
^AIS:ACL2019 progress report
-
^Chair of ACL Zhou Ming: Embrace the bright future of ACL and NLP together
-
^Pre-training methods for language models in natural language processing https://www.jiqizhixin.com/articles/2018-10-22-3
-
^ELMO:Deep contextualized word representations
-
^ULMFiT:Universal Language Model Fine-tuning)
-
^SiATL:An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models
-
^The era of BERT and post-era NLP https://zhuanlan.zhihu.com/p/66676144
-
^GPT:Improving Language Understanding by Generative Pre-Training
-
^GPT2.0:Language Models are Unsupervised Multitask Learners
-
^Transformer:Attention is all you need
-
^BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
-
^Innovations in the era of Bert (application): Progress of Bert in various fields of NLP https://zhuanlan.zhihu.com/p/68446772
-
^MASS: Masked Sequence to Sequence Pre-training for Language Generation
-
^UNILM:Unified Language Model Pre-training for Natural Language Understanding and Generation
-
^ERNIE: Enhanced Representation through Knowledge Integration
-
^ERNIE: Enhanced Language Representation with Information Entities
-
^nndl:Neural Networks and Deep Learning
-
^MT-DNN:Multi-Task Deep Neural Net for NLU
-
^ERNIE 2.0: A CONTINUAL PRE-TRAINING FRAMEWORK FOR LANGUAGE UNDERSTANDING
-
^Chen Kai:https://www.zhihu.com/question/337827682/answer/768908184
-
^SpanBert:A Deep Exploration of Bert Pre-training
-
^RoBERTa: A Robustly Optimized BERT Pretraining Approach
-
^They created XLNet that sweeps NLP: Interview with CMU PhD Yang Zhilin
-
^XLnet: Generalized Autoregressive Pretraining for Language Understanding
-
^Neural autoregressive distribution estimation
-
^Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Recommended Reading:
Practical | Pytorch BiLSTM + CRF for NER
How to evaluate the fastText algorithm proposed by the author of Word2Vec? Does deep learning have no advantages in simple tasks like text classification?
From Word2Vec to Bert, discussing the past and present of word vectors (Part 1)
