

MLNLP(Machine Learning Algorithms and Natural Language Processing) community is one of the largest natural language processing communities in China and abroad, gathering over 500,000 subscribers, with audiences including NLP master’s and doctoral students, university teachers, and corporate researchers.The vision of the community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, as well as among enthusiasts.
Author | Yu Xuansu
Source | Zhihu
Address | https://zhuanlan.zhihu.com/p/434672623
This article is for academic sharing only. If there is any infringement, please contact us to delete the article.
01
Why Mask
Padding: When inputting data into the model, the lengths vary. To maintain consistent input, padding is added to convert the input into a fixed tensor. For example: [1, 2, 3, 4, 5] input size: 1 * 8. After padding: [1, 2, 3, 4, 5, 0, 0, 0]. The problem introduced by padding: inconsistent padding counts lead to the mean calculation deviating from the original mean: (1 + 2 + 3 + 4 + 5) / 5 = 3. The mean after padding: (1 + 2 + 3 + 4 + 5) / 8 = 1.875. Introducing masks solves the defects of padding: assume m = [1, 1, 1, 1, 1, 0, 0, 0].
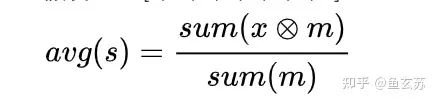
⊗: Element-wise multiplication results in the masked avg = 3 (consistent with the original result). In addition to the padding scenario mentioned above, masks can also be used to obscure information so that the model learns to focus on certain words or areas.
02
Masking Methods in Papers Over the Years
2.1 Padding Mask
Principle as seen in the example: transformer mask encoder self-attention mask.
2.2 Sequence Mask: Transformer Decoder Part
During training, in the Masked Multi-head Attention layer, to prevent future information from being seen at the current moment, future information needs to be masked out.
| Current Position | Predicted Position | |||||||
| At t-1 | [begin] | Today | is | a | good | day | weather | [end] |
| Current Position | Predicted Position | |||||||
| At t | [begin] | Today | is | a | good | day | weather | [end] |
| Current Position | Predicted Position | |||||||
| At t+1 | [begin] | Today | is | a | good | day | weather | [end] |
The mask is a lower triangular matrix.

Using the mask matrix, all positions after the current one are obscured. This prevents seeing information after time t. The t-1, t, and t+1 moments are computed in parallel in the masked Multi-head Attention layer. Extension issue: The transformer decoder also uses masks during prediction to ensure that the amount of information remains consistent between prediction and training, ensuring the consistency of output results.
2.3 BERT: Masked LM
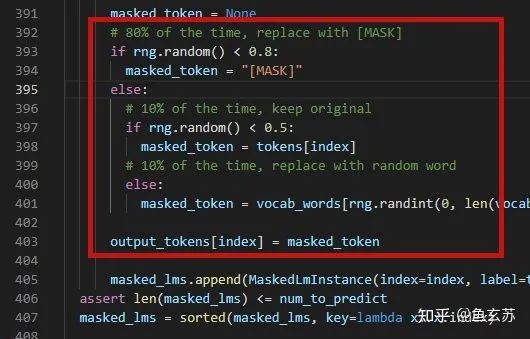
The training data generator randomly chooses 15% of the token positions for prediction. If the i-th token is chosen, it is replaced with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time. Then, Ti will be used to predict the original token with cross-entropy loss. — BERT original text: In the training data, the probability of being masked is 15%, and the probability of being replaced with [MASK] is 80%, the unchanged probability is 10%, and the random replacement probability is 10%. Explanation: The training distribution differs from the actual language distribution, and the three replacement methods are to inform the model that the input word may be incorrect and not to trust it too much. Corresponding code: bert/create_pretraining_data.py.
2.4 RoBERTa: Dynamic Masked LM
The original BERT implementation performed masking once during data preprocessing, resulting in a single static mask. To avoid using the same mask for each training instance in every epoch, training data was duplicated 10 times so that each sequence is masked in 10 different ways over the 40 epochs of training. Thus, each training sequence was seen with the same mask four times during training. RoBERTa’s original text compared BERT’s static mask and explained that RoBERTa avoided static masks by duplicating data 10 times, allowing each corpus to be masked in 40 rounds of training, and the model can learn four times.
No code implementation found: logically, just copy the input 10 times.
2.5 ERNIE: Knowledge Masking Strategies
ERNIE is designed to learn language representation enhanced by knowledge masking strategies, which includes entity-level masking and phrase-level masking. It adds knowledge graphs to BERT to enhance local learning. BERT’s original approach only filled gaps based on the probability of the mask. Using knowledge-level filling ensures that the model learns key knowledge.

Basic-Level Masking: This uses the same masking mechanism as BERT, and for Chinese corpus, character-level masking is used. No higher-level semantic knowledge is added at this stage. Phrase-Level Masking: At this stage, a syntactic analysis tool is used to obtain phrases in a sentence, such as the phrase “a series of” in the image, then a portion is randomly masked, and the remaining is used to predict these phrases. At this stage, phrase information is added to the word embeddings. Entity-Level Masking: At this stage, certain entities in the sentence are masked, allowing the model to learn higher-level semantic information.
2.6 BERT-WWM
After Baidu released ERNIE 1.0 in April 2019, iFlytek and Harbin Institute of Technology released BERT-WWM in July of the same year.
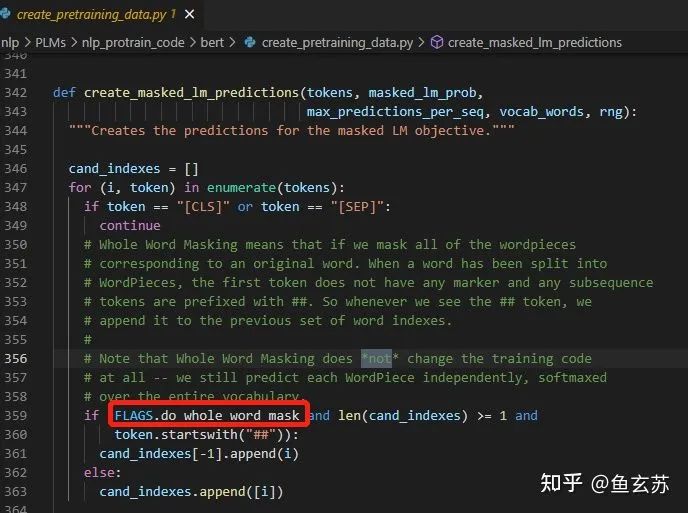
The whole word masking mainly mitigates the drawbacks in original BERT that, if the masked WordPiece token (Wu et al., 2016) belongs to a whole word, then all the WordPiece tokens (which forms a complete word) will be masked altogether. Continuous masking of all WordPiece tokens that can form a word means that WWM’s RoBERTa does not require dynamic masking because all words have already been masked. The explanation for the WWM code can be found in [4].
Example sentence: there is an apple tree nearby. tok_list = [“there”, “is”, “an”, “ap”, “##p”, “##le”, “tr”, “##ee”, “nearby”, “.”] BERT without WWM results in:
there [MASK] an ap [MASK] ##le tr [RANDOM] nearby .[MASK] [MASK] an ap ##p [MASK] tr ##ee nearby .there is [MASK] ap [MASK] ##le tr ##ee nearby [MASK] .
The result with BERT-WWM is:
there is an [MASK] [MASK] [RANDOM] tr ##ee nearby .there is [MASK] ap ##p ##le [MASK] [MASK] nearby .there is! [MASK] ap ##p ##le tr ##ee nearby [MASK] .
It can be seen that the word “apple” in the absence of WWM is masked in different parts; with WWM, it is masked all at once or not masked at all. WWM does not require changes to the BERT code:
03
References
[1] BERT: arxiv.org/pdf/1810.0480 [2] ERNIE: Enhanced Representation through Knowledge Integration code: github.com/PaddlePaddle [3] Pre-Training with WholeWord Masking for Chinese BERT: arxiv.org/pdf/1906.0810 model: github.com/ymcui/Chines [4] BERT-WWM explanation of the WWM code: github.com/ymcui/Chines [5] RoBERTa: A Robustly Optimized BERT Pretraining Approach: arxiv.org/pdf/1907.1169
[6] Many other insightful explanations have been seen, but will not be quoted one by one here.
Technical Group Invitation

△Long press to add assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction(e.g.: Xiao Zhang-Harbin Institute of Technology-Dialogue System) to apply to join the Natural Language Processing/PyTorch technical group.
About Us
MLNLP(Machine Learning Algorithms and Natural Language Processing) community is a civil academic community jointly built by domestic and foreign scholars in natural language processing, and has now developed into one of the largest natural language processing communities in China and abroad, gathering over 500,000 subscribers. It includes well-known brands such as 10,000-person top conference group, AI selection meeting, AI talent meeting, and AI academic meeting, aimed at promoting progress between the academic and industrial sectors of machine learning and natural language processing, as well as among enthusiasts.The community can provide an open communication platform for related practitioners’ further studies, employment, and research. Everyone is welcome to follow and join us.