

Happy New Year, everyone!
Today, I will interpret Baichuan’s RAG approach. Baichuan Intelligent has a profound background in search; let’s see how they navigated the pitfalls of RAG!
In general, Baichuan combines a long context model (192k) with search enhancement methods to address knowledge updates and reduce model hallucinations, achieving 95% accuracy on a dataset of 50 million tokens. They have optimized in the following areas:
1) Query Expansion: This is a term I coined, which may not be entirely accurate. It mainly references Meta’s CoVe[1] and Baichuan’s self-developed Think Step-Further method to break down and expand complex user queries, uncovering deeper sub-questions. By leveraging the higher retrieval effectiveness of sub-questions, it addresses the quality bias in retrieving complex queries.
2) Optimizing Retrieval Pipeline: This method combines sparse retrieval, vector retrieval, and reranking to enhance recall and accuracy. Moreover, their self-developed Baichuan-Text-Embedding vector model has topped the C-MTEB semantic vector evaluation standard.
3) Self-Critique Mechanism: Baichuan Intelligent employs a self-critique mechanism in their large model to filter for higher quality, knowledge-dense content.
1. Overview
Title: Baichuan Intelligent Large Model + Search Enhancement Technology Stack Provides Solutions for Customized Large Models
Source:https://mp.weixin.qq.com/s/Hy78rtJuJTehAJIC-HK2Rg
1 Motivation
1.1 Current Pain Points of Retrieval-Augmented Generation (RAG) Methods
-
High Costs, Low Recall: Expanding the context window and introducing vector databases can significantly enhance the model’s access to new knowledge at a very low cost. However, the capacity for expanding the context window is limited (128k can accommodate a maximum of 230,000 Chinese characters, equivalent to a 658kb document), leading to high costs and noticeable performance degradation. Vector databases also suffer from low recall rates and high development thresholds.
-
Complex User Inputs: Unlike traditional keyword or phrase search logic, user queries are no longer limited to words or short phrases but have transformed into natural dialogue and multi-turn conversational data, with more diverse question forms that are closely related to context and more conversational in style.
1.2 RAG is One of the Effective Methods for Implementing Large Models to Reduce Hallucinations and Update Data
-
Industry large model solutions include post-training and supervised fine-tuning, but they still cannot resolve hallucination and effectiveness issues in large model implementations.
-
Post-training and supervised fine-tuning require data updates and retraining each time, which may introduce other issues and incur significant costs.
2 Methods
Streamlined Summary:
-
Baichuan combines long windows with search/RAG (Retrieval-Augmented Generation) to form a complete technology stack of long window models + search.
-
Summary of Baichuan’s RAG Approach: Query Expansion (referencing Meta CoVe + self-developed Think Step-Further) + self-developed Baichuan-Text-Embedding vector model + sparse retrieval (BM25, ES) + rerank model + self-developed Self-Critique technology (filtering retrieval results).
2.1 Query Expansion
Background: Unlike traditional keyword or phrase search logic, user queries have transformed into natural dialogue and multi-turn conversational data, with more diverse question forms that are closely related to context and more conversational in style.
Purpose: To break down complex prompts, retrieve related sub-questions, and deeply explore the underlying meanings in conversational expressions, leveraging the higher retrieval effectiveness of sub-questions to resolve quality bias in retrieving complex queries.
Method: Referencing Meta CoVe[1] and the Think Step-Further method, multiple related questions are generated from the user’s original query, and relevant content is retrieved through these related questions to improve recall.
Baichuan’s Query Expansion Plan:
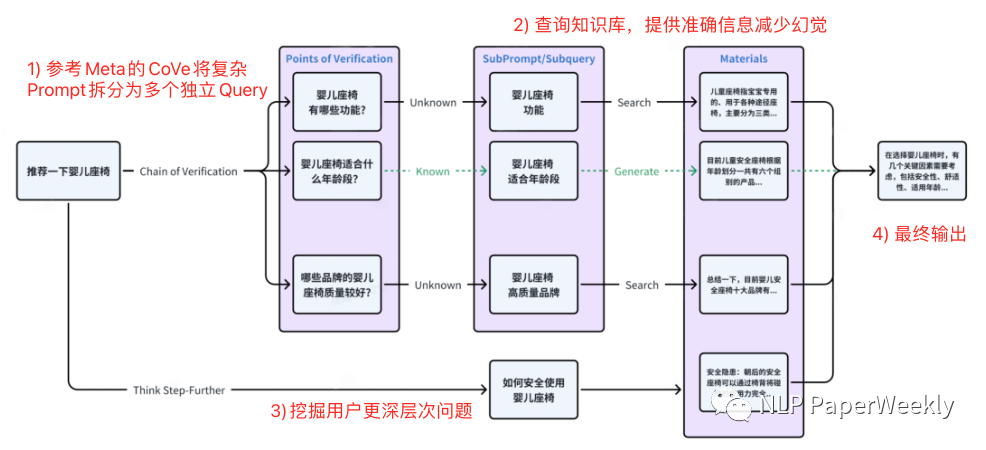
Meta CoVe Plan:

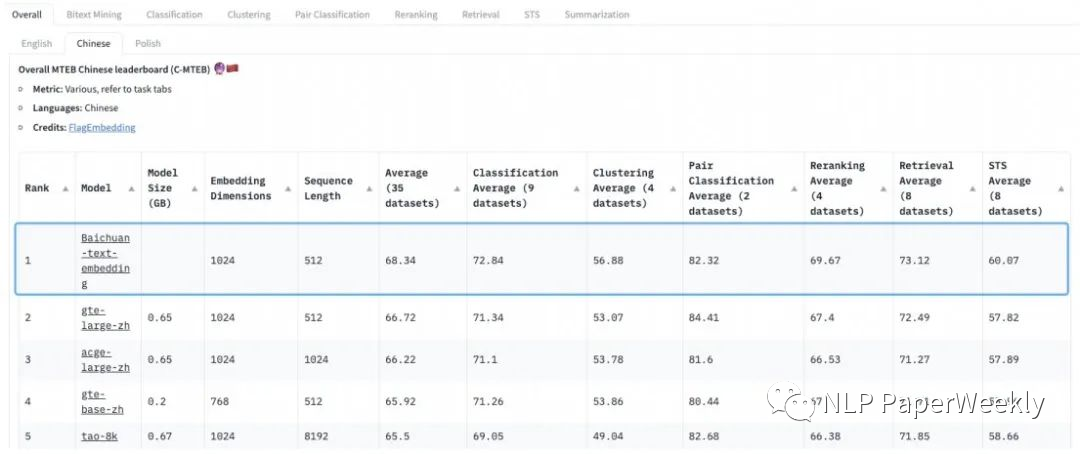
2.2 Self-Developed Embedding Model
Data: Over 1.5T tokens (is the training data for the Baichuan model also used to train the embedding model?).
Method: An unsupervised approach (estimated to be similar to the SimCSE[2] series) is used, with a self-developed loss function to address the batch size dependency in contrastive learning methods.
Effect: Topped the C-MTEB, achieving leading scores in classification, clustering, ranking, retrieval, and text similarity across five tasks.
2.3 Multi-Round Recall + Rerank
Method: Sparse retrieval + vector retrieval + rerank model. Sparse retrieval likely refers to traditional retrieval methods such as BM25 and ES, while the specifics of the rerank model are unclear; it is uncertain whether a large model is used for reranking or if a related rerank model is directly trained to sort the retrieval results.
Effect: Recall rate of 95%, which is lower than 80% for other open-source vector models.
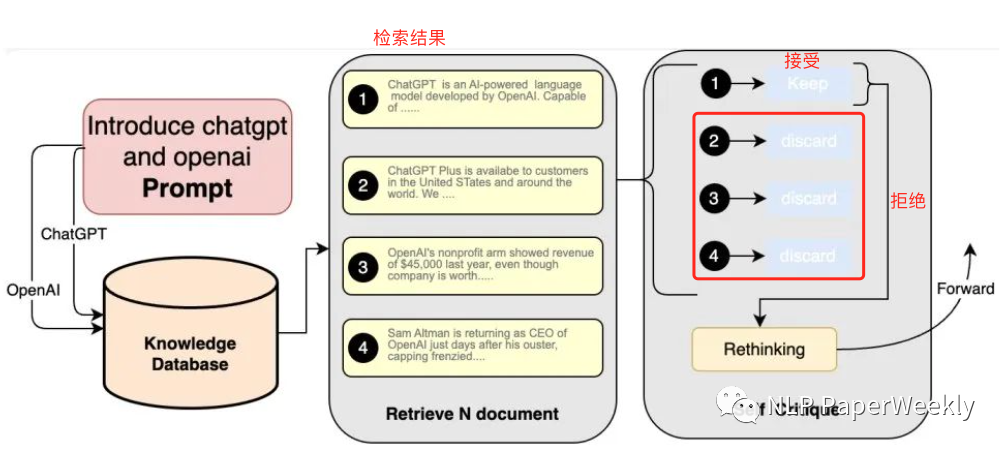
2.4 Self-Critique
Method: The large model reviews the retrieved content based on prompts, evaluating relevance and usability, and conducts a secondary review to filter out the most relevant and highest quality candidate content.
Purpose: To enhance the knowledge density and breadth of retrieval results while reducing knowledge noise in the results.
3 Conclusion
-
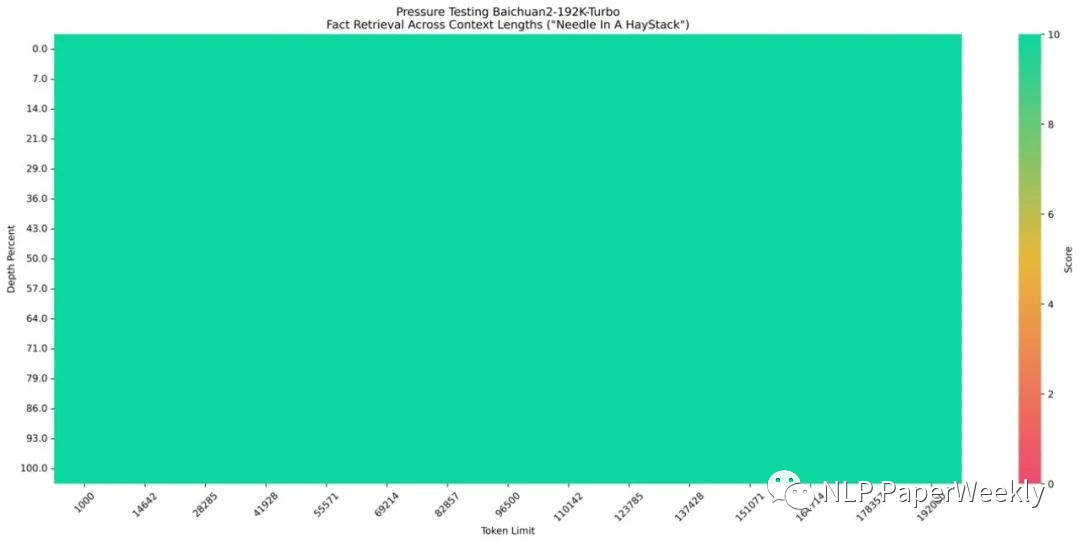
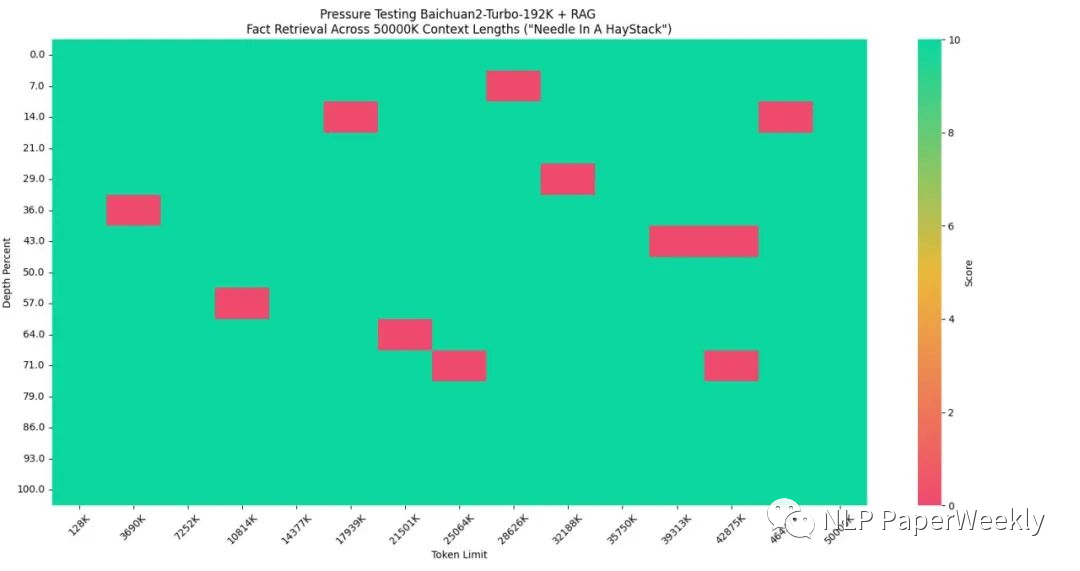
Baichuan’s 192K context model performs well, achieving 100% answer accuracy.
-
The long context window model + search enhancement technology achieves 95% answer accuracy on a dataset of 50 million tokens.
4. Summary
-
The recall distribution of multi-turn Q&A scenarios differs from that of traditional search engines. Baichuan leverages the higher retrieval effectiveness of sub-questions to break down and expand original complex queries, addressing the quality bias in retrieving complex queries.
-
Using vector retrieval results for previously unseen corpora may not yield ideal outcomes. Baichuan optimizes performance by training an embedding model using unsupervised methods on a large corpus. Industry large models tend to prefer proprietary data; to improve training effectiveness on proprietary data, further training on proprietary data will yield even better results.
-
Query expansion + multi-round recall + rerank + self-critique may currently represent a good RAG approach, but it may also incur higher costs. The overall approach resembles an advanced version of the ReAct[3] series, which has done more work on both the search and answer correction sides to optimize actual effectiveness. However, its downside is the need for multiple calls to the large model, which incurs additional costs; whether this strategy is adopted in real-world applications remains to be validated.
5. References
[1] Chain-of-Verification Reduces Hallucination in Large Language Models https://arxiv.org/abs/2309.11495
[2] Gao T, Yao X, Chen D. Simcse: Simple contrastive learning of sentence embeddings[J]. arXiv preprint arXiv:2104.08821, 2021.
[3] Yao S, Zhao J, Yu D, et al. React: Synergizing reasoning and acting in language models[J]. arXiv preprint arXiv:2210.03629, 2022.
To join the technical exchange group, please add the AINLP assistant WeChat (id: ainlp2)
Please specify your specific direction and the related technologies used.
About AINLP
AINLP is an interesting AI natural language processing community focusing on sharing related technologies in AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include LLM, pre-trained models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, and job experience sharing, etc. Welcome to follow! To join the technical exchange group, please add the AINLP assistant WeChat (id: ainlp2), specifying your work/research direction and the purpose of joining the group.