
Many practitioners have found that although RAG can quickly build a demo in a short time, it faces numerous challenges in actual production environments. This article analyzes the core issue of RAG’s industrial implementation from the perspective of entrepreneurs in the AI large model field—problem grading—and discusses the challenges and solutions of four types of problems for your reference.
———— / BEGIN / ————
Many product managers and engineers familiar with RAG complain, “It only takes a week to produce a demo, but it takes at least six months to reach a production-level standard!”.
This is the reality of RAG’s industrial implementation at this stage. The RAG framework is very simple and understandable, and there are many ways to optimize the entire RAG process, but whether for internal use within companies or for end-users, the most direct feeling is that RAG can only retrieve and answer relatively superficial and intuitive questions.
The unicorn in the enterprise knowledge base field, Hebbia, has also conducted experiments showing that RAG can only address 16% of internal enterprise problems. What is the reason for this?
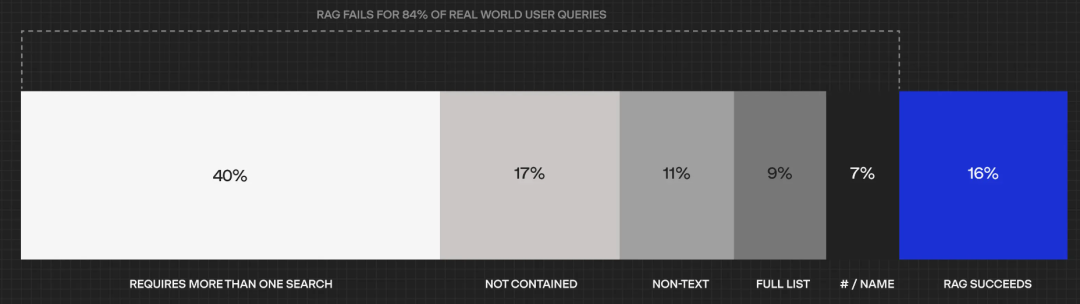
The answer lies in problem grading.
Any user query can be divided into four categories: explicit fact queries, implicit fact queries, explainable reasoning queries, and implicit reasoning queries. The complexity and difficulty of solving these four types of problems increase sequentially.
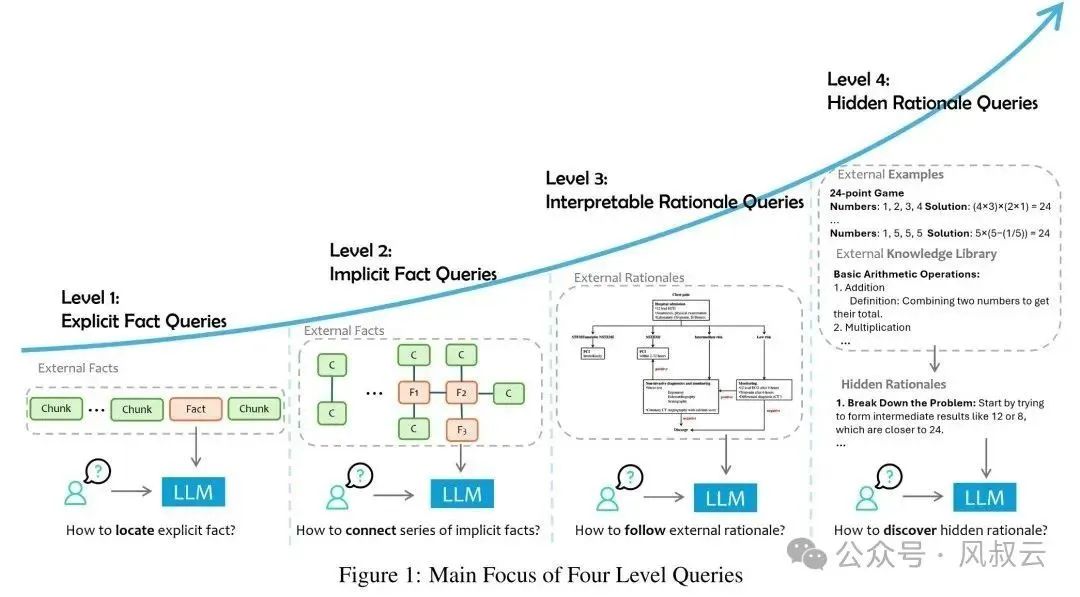
The following image lists the challenges and solutions faced by each type of problem. It can be seen that only explicit fact queries and some implicit fact queries can be solved through RAG, Iterative Rag, or GraphRag. However, for explainable reasoning queries and implicit reasoning queries, RAG is ineffective and requires other more complex and targeted solutions.
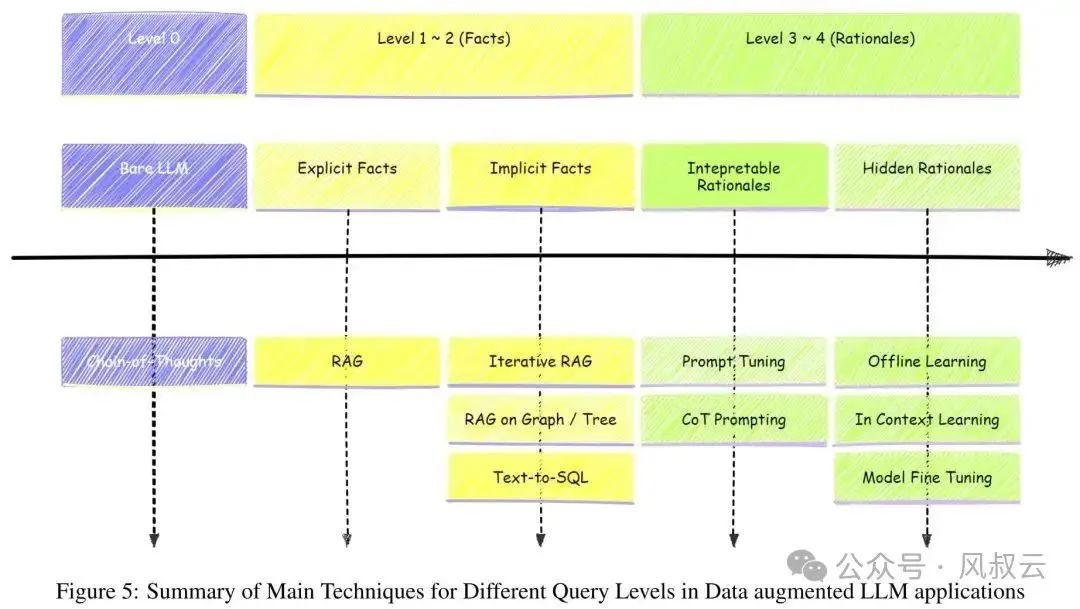
In actual corporate application scenarios, the vast majority of valuable questions for business departments fall into Level 3 and Level 4, which leads to the predicament of “RAG can produce a demo in a week, but it takes six months to launch”.
Next, Feng Shu will elaborate on the characteristics and solutions for these four types of problems. By the end, you will definitely gain something!
Explicit Fact Queries
Explicit facts refer to factual information or data that directly exists in external data and do not require additional reasoning. For example, “Where was the 2016 Olympics held?”, “What is the brand and operating temperature of a certain sensor?”, “What was the revenue of Store A last month?”.
Explicit fact queries are the simplest form of queries, directly retrieving clear factual information from the provided data without complex reasoning and thinking, making them very suitable for RAG.
Of course, to accurately and efficiently retrieve and generate relevant content, the RAG system also needs optimization. This can be achieved through methods previously introduced by Feng Shu, which we will briefly review here.
Index Construction
-
Block Optimization: By using sliding windows, adding metadata, and scaling from small to large, the size, structure, and relevance of content blocks can be more reasonably divided.
-
Multi-level Indexing: This refers to creating two indexes, one consisting of document summaries and the other consisting of document blocks, and conducting a two-step search, first filtering relevant documents through summaries and then searching only within this relevant group.
-
Knowledge Graph: Extracting entities and the relationships between them to build a global information advantage, thereby improving the accuracy of RAG.
Pre-retrieval
-
Multiple Queries: Utilizing prompt engineering to expand queries through large language models, transforming the original query into multiple similar queries, and executing them in parallel.
-
Sub-queries: Decomposing and planning complex issues by breaking the original query into multiple sub-questions and then summarizing and merging them.
-
Query Transformation: Transforming the user’s original query into a new query content before retrieval and generation.
-
Query Construction: Converting natural language queries into a language that specific machines or software can understand, such as text2SQL, text2Cypher.
Retrieval
-
Sparse Retrievers: Using statistical methods to convert queries and documents into sparse vectors. Their advantage lies in high efficiency when processing large datasets, focusing only on non-zero elements.
-
Dense Retrievers: Using pre-trained language models (PLMs) to provide dense representations for queries and documents, although the computational and storage costs are high, they can offer more complex semantic representations.
-
Retriever Fine-tuning: Fine-tuning retrieval models based on labeled domain data, usually achieved through contrastive learning.
Post-retrieval
-
Re-ranking: For the retrieved content blocks, using a specialized ranking model to recalculate the relevance scores of the context.
-
Compression: For the retrieved content blocks, do not directly input them into a large model but first remove irrelevant content and highlight important context, thereby reducing the overall prompt length and minimizing the interference of redundant information on the large model.
Implicit Fact Queries
Implicit facts do not directly appear in the original data and require some reasoning and logical judgment. Moreover, the information that infers implicit facts may be scattered across multiple paragraphs or data tables, thus requiring cross-document retrieval or cross-table queries.
For example, “Query the store with the highest revenue growth rate in the past month” is a typical implicit fact query. It requires first obtaining the revenue of all stores for this month and last month, then calculating the revenue growth rate for each store, and finally sorting to obtain the result.
The main challenge of implicit fact queries is that the data sources and reasoning logic depend on different problems, so ensuring the generalization of large models during the reasoning process is crucial.
The main problem-solving ideas for implicit fact queries include the following methods:
Multi-hop Retrieval and Reasoning
Iterative Rag: Generating a retrieval plan before retrieval and continuously optimizing based on retrieval results during the process. For example, using the ReAct framework, following the Thought – Action – Observation analytical approach to gradually approach the correct answer.
Self-Rag: Constructing four key scorers, namely retrieval demand scorer, retrieval relevance scorer, generation relevance scorer, and answer quality scorer, allowing the large model to autonomously decide when to start retrieval, when to use external search tools, and when to output the final answer.
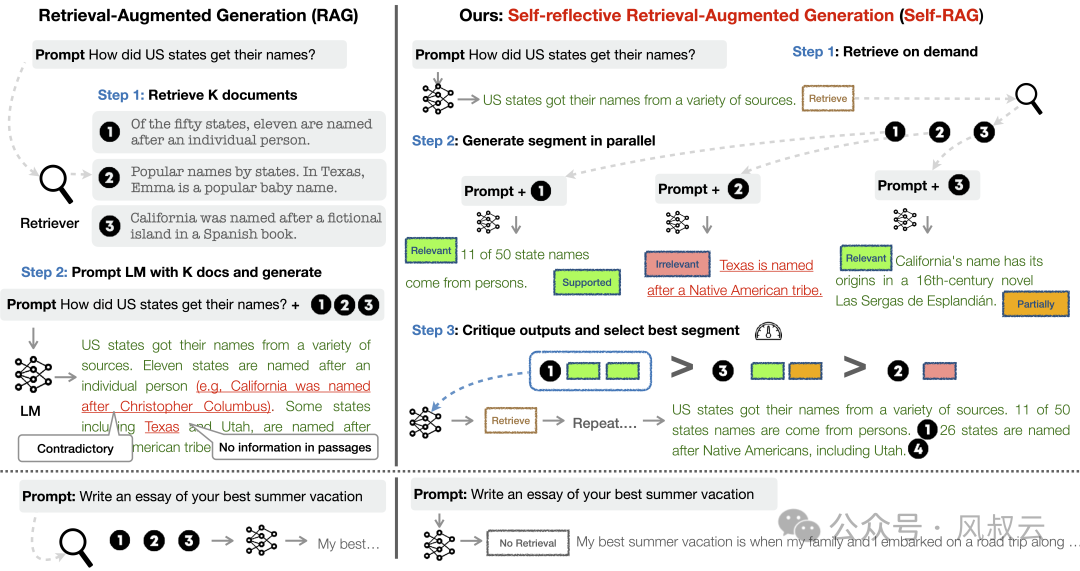
Utilizing Graph and Tree Structures
Raptor: RAPTOR recursively clusters text blocks based on vectors and generates text summaries of these clusters, thereby constructing a tree from the bottom up. Nodes that cluster together are sibling nodes; the parent node contains the text summary of the cluster. This structure allows RAPTOR to load context blocks representing different levels of text into the LLM’s context, enabling effective and efficient responses to questions at different levels.
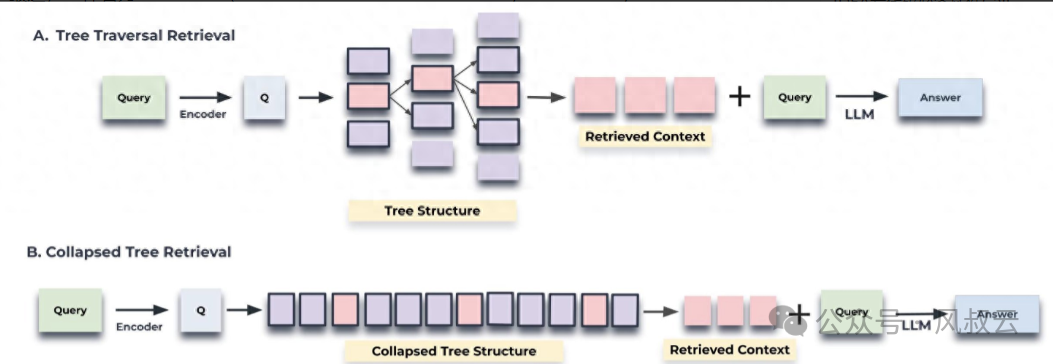
GraphRag: A technical paradigm that combines knowledge graphs with Rag. Traditional Rag retrieves from vector databases, while GraphRag retrieves from knowledge graphs stored in graph databases, obtaining associated knowledge and achieving enhanced generation.
Converting Natural Language into SQL Queries
text2SQL: Mainly used for database queries, especially in multi-table query scenarios.
Explainable Reasoning
Explainable reasoning refers to problems that cannot be derived from explicit or implicit facts and require comprehensive data for relatively complex reasoning, induction, and summarization, with a reasoning process that possesses business explainability.
Attribution analysis in ChatBI is a typical example of explainable reasoning, such as “What caused the revenue drop of 5% in the South China region last month?” This question cannot be directly obtained but can be inferred through certain means as follows:
Total Revenue = New Customers * Conversion Rate * Average Transaction Value + Existing Customers * Repurchase Rate * Average Transaction Value
After analysis, the number of new customers, conversion rate, and average transaction value did not change significantly, while the repurchase rate of existing customers dropped by about 10%. Therefore, it can be inferred that the reasons may be “service quality, competition from peers”, leading to the decline in the repurchase rate of existing customers, and consequently, a decrease in total revenue.
Explainable reasoning problems mainly face two challenges: diverse prompts and limited explainability.
-
Diverse Prompts: Different query problems require specific business knowledge and decision-making basis. For example, reasoning the cause of revenue decline can use the above business rules, but if it is reasoning the cause of gross margin decline, a different business rule is needed. This diversification of rules requires industry experts to organize and sediment them and convert them into appropriate prompts for the large model to understand the underlying logic.
-
Limited Explainability: The impact of prompts on the large model is opaque, making it difficult to assess their influence, which hinders the construction of consistent explainability.
In the face of such challenges, Feng Shu mainly has the following suggestions:
Prompt Engineering Optimization
Optimize prompts: It is necessary to effectively integrate business reasoning logic into large language models, which tests the industry know-how of prompt designers.
Prompt Fine-tuning: Manually designing prompts can be time-consuming; this problem can be solved through prompt fine-tuning techniques. For example, using reinforcement learning to treat the probability of the large model generating correct answers as a reward, guiding the model to discover the best prompt configurations across different datasets.
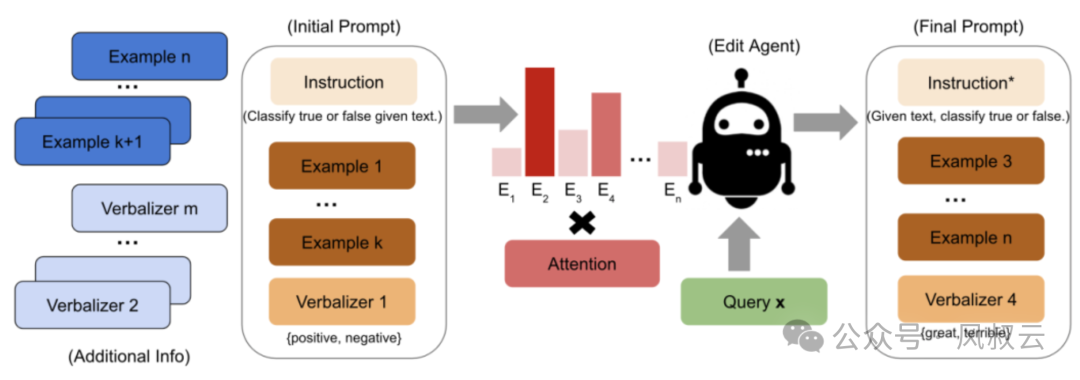
Building Decision Trees
Decision Trees: Converting decision processes into state machines, decision trees, or pseudocode for the large model to execute. For example, in the field of equipment operation and maintenance, constructing a fault tree is a very effective fault detection solution.

Utilizing Agentic Workflows
Agentic Workflow: Constructing specific steps for large model thinking and action through workflows, thereby constraining the thinking direction of the large model. The advantage of this method is that it can provide relatively stable outputs, but the downside is that it lacks flexibility and also requires designing workflows for each type of problem.
Implicit Reasoning Queries
Implicit reasoning queries refer to those that are difficult to judge through pre-agreed business rules or decision logic, and must be observed and analyzed from external data to ultimately infer conclusions.
For example, in IT intelligent operations and maintenance, there is no a priori complete documentation detailing the handling methods and rules for every problem; only the various fault events and solutions handled by the operations and maintenance team in the past are available. The large model needs to mine the best handling solutions for different faults from this data, which is an implicit reasoning query.
Similarly, scenarios such as intelligent operations and maintenance on production lines and intelligent quantitative trading also involve numerous implicit reasoning query problems.
The main challenges of implicit reasoning problems are the difficulty of logical extraction, data dispersion, and insufficiency, making them the most complex and challenging problems.
-
Difficulty of Logical Extraction: Mining implicit logic from vast amounts of data requires developing complex and effective algorithms that can parse and identify the hidden logic behind the data. Therefore, relying solely on surface semantic similarity is far from sufficient; specialized small models need to be constructed to address this.
-
Data Dispersion and Insufficiency: Implicit logic is often hidden in very dispersed knowledge, requiring the model to possess strong data mining and comprehensive reasoning abilities. At the same time, when external data is limited or the data quality does not meet requirements, it is also challenging to extract valuable information from it.
For the challenges faced by implicit reasoning problems, the following problem-solving ideas are proposed:
-
Machine Learning: Summarizing potential rules from historical data and cases using traditional machine learning methods.
-
Context Learning: Including relevant examples in the prompts to provide reference for the model. However, the drawback of this method is how to enable the large model to master reasoning abilities beyond its training domain.
-
Model Fine-tuning: Fine-tuning the model with a large amount of business and case data to internalize domain knowledge. However, this method is resource-intensive and should be used cautiously by small and medium-sized enterprises.
-
Reinforcement Learning: Encouraging the model to generate reasoning logic and answers that best fit business realities through a reward mechanism.
Conclusion
In this article, regarding the issue that RAG is easy to implement but difficult to launch, Feng Shu introduced the four types of user queries and the corresponding problem-solving ideas for each type.
For explicit fact queries and implicit fact queries, various RAG optimization solutions can be employed. However, when facing explainable reasoning and implicit reasoning problems, relying solely on RAG will be insufficient, requiring the introduction of multiple methods such as prompt engineering, decision trees, Agentic Workflow, machine learning, model fine-tuning, and reinforcement learning.
Each method deserves to be elaborated on in detail, and could be the subject of a separate series. Therefore, this article only presents these problem-solving directions without further elaboration. Feng Shu will provide detailed introductions combined with practical cases later when time permits.
———— / E N D / ————
Author: Feng Shu Source WeChat Official Account: Feng Shu Cloud



