

This article is a note from Andrew Ng’s DeepLearning.ai course, covering the content of neural networks. The previous part can be found in[Simple Explanation of Neural Networks Part One]
4Activation Function
When building a neural network, one important question to consider is which activation function to use for each independent layer. In logistic regression, the sigmoid function is consistently used as the activation function, but there are some better options.
The expression for the tanh function (Hyperbolic Tangent Function) is:
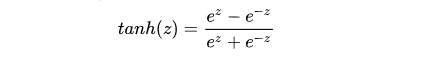
The graph of the function is:
<img src="https://pic4.zhimg.com/v2-abc3e1f08ae9d64d43e17d50703922b5_b.jpg" data-caption="" data-size="normal" data-rawwidth="320" data-rawheight="202" class="content_image" width="320" />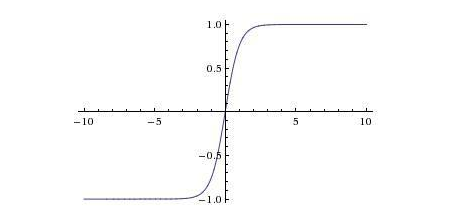
The tanh function is actually a shifted version of the sigmoid function. When using the tanh function as the activation function for hidden units, the performance is generally better than that of the sigmoid function, because the values of the tanh function range from -1 to 1, which makes the output’s average value closer to 0, rather than the average value of the sigmoid function being 0.5. This actually makes the learning for the next layer easier. For binary classification problems, to ensure the output is between 0 and 1, the sigmoid function will still be used as the output’s activation function.
However, one drawback of both the sigmoid and tanh functions is that when the inputs approach infinity or negative infinity, the derivatives (gradients) of these functions become very small, which slows down the gradient descent process.
The Rectified Linear Unit (ReLU) function, which was used in the example to explain what a neural network is, is also one of the commonly used activation functions in machine learning. Its expression is:
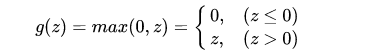
The graph of the function is:
<img src="https://pic1.zhimg.com/v2-6f25d5487b487b050bf655437f14fde5_b.jpg" data-caption="" data-size="normal" data-rawwidth="493" data-rawheight="265" class="content_image" width="493" />When z is greater than 0, the derivative of the ReLU function is always 1, so using the ReLU function as the activation function results in much faster convergence in stochastic gradient descent compared to sigmoid and tanh, but data on the negative axis is lost.
The modified version of the ReLU function, known as Leaky-ReLU, has the expression:
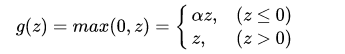
The graph of the function is:
<img src="https://pic1.zhimg.com/v2-c740562926854a4abaa220bf723cba99_b.jpg" data-caption="" data-size="normal" data-rawwidth="482" data-rawheight="274" class="content_image" width="482" />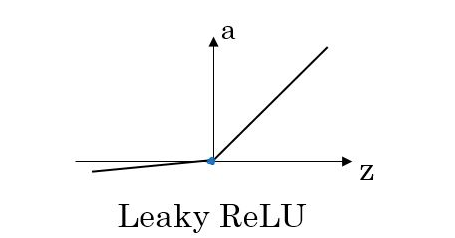
Here, alpha is a small constant used to retain some values on the non-negative axis.
It can be observed that the activation functions mentioned above are all non-linear. This is because if a linear activation function is used, the output will be a linear combination of the inputs, making the neural network no different from simply using a linear model, thus losing its advantages and value.
At this point, the neural network is similar to a simple logistic regression model.
5Forward Propagation and Back Propagation
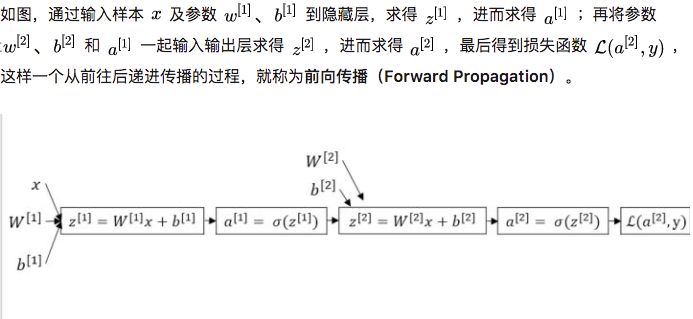
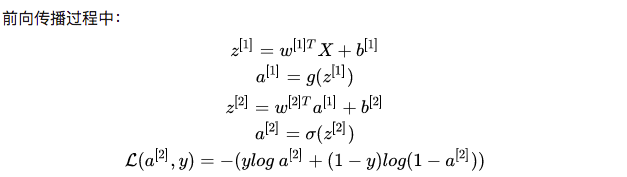
During the training process, there is always a certain error between the final results obtained after forward propagation and the true values of the training samples. This error is known as the loss function.
To reduce this error, one of the most widely used algorithms is gradient descent. Thus, using the loss function, we compute the partial derivatives of each parameter from back to front, which is known as Back Propagation (BP).
<img src="https://pic1.zhimg.com/v2-0c256d0044ad4d4994eb00284d0e57bf_b.jpg" data-caption="" data-size="normal" data-rawwidth="972" data-rawheight="386" class="content_image" width="972" />In the implementation of the specific algorithm, it is still necessary to use the gradient descent method used in logistic regression, vectorizing and averaging each parameter, and continuously updating.
6Deep Neural Networks
Deep neural networks contain multiple hidden layers, constructed as previously described. During training, choose activation functions based on the actual situation, perform forward propagation to obtain the cost function, and then use the BP algorithm for back propagation, applying gradient descent to reduce the loss value.
Deep neural networks with multiple hidden layers can better solve certain problems. For instance, when creating a facial recognition system using a neural network, the first layer can be a feature detector responsible for finding the edge directions in the photo. Convolutional Neural Networks (CNN) are specifically designed for this type of recognition.
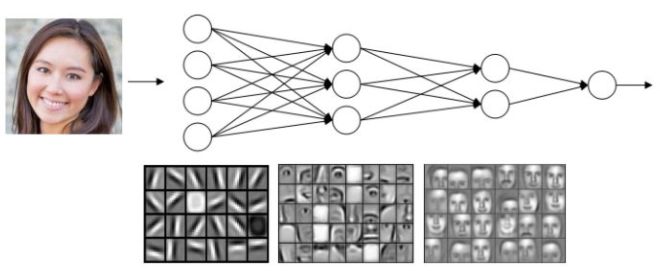
<img src="https://pic1.zhimg.com/v2-724da3f8b361217281c9002648104d2a_b.jpg" data-caption="" data-size="normal" data-rawwidth="739" data-rawheight="345" class="content_image" width="739" />The second layer of the deep neural network can detect various feature parts that make up the face in the photo, and the next layer can recognize different face shapes based on the previously obtained features, etc.
In this way, the first few layers of this deep neural network can be treated as several simple detection functions, and then these layers can be combined to form a more complex learning function. By starting with small details, gradually building larger and more complex models, deep neural networks are constructed to achieve this.
Recommended Reading:
[Deep Learning Practice] How to Handle Variable-Length Sequence Padding in RNN with Pytorch
30,000 at a Bargain Price! Overview of High Salaries in AI Positions Across Companies
[Blockchain] The Most Accessible Introduction to Blockchain
Welcome to follow our public account for learning and communication~
