About 4300 words, recommended reading time 5 minutes. This article classifies the field into two major categories and four subcategories based on the fusion stage, and also analyzes the existing problems in the current field, providing references for future research directions.
1 Introduction
Multi-modal sensor fusion means complementary, stable, and safe information, and has long been an important part of autonomous driving perception. However, insufficient information utilization, noise in raw data, and misalignment between sensors (such as timestamp desynchronization) have limited fusion performance. This article comprehensively surveys the existing multi-modal autonomous driving perception algorithms, including sensors like LiDAR and cameras, focusing on object detection and semantic segmentation, analyzing over 50 pieces of literature. Unlike traditional classification methods for fusion algorithms, this article categorizes the field into two major categories and four subcategories based on the fusion stage. Additionally, this article analyzes the existing problems in the current field and provides references for future research directions.
2 Why Multi-Modal?
This is because single-modal perception algorithms have inherent flaws [4, 26]. For example, the typical installation position of LiDAR is higher than that of the camera [102], in complex real driving scenarios, objects may be occluded in the front-facing camera, and at this time, using LiDAR may capture the missing target. However, due to mechanical structural limitations, LiDAR has different resolutions at different distances and is easily affected by extreme weather conditions, such as heavy rain. Although both sensors can perform excellently when used alone, from the future perspective, the complementary information between LiDAR and cameras will make autonomous driving safer at the perception level.Recently, multi-modal perception algorithms for autonomous driving have made significant progress [15,77,81], from cross-modal feature representation, more reliable modal sensors, to more complex and stable multi-modal fusion algorithms and techniques. However, only a few reviews [15, 81] focus on the methodology of multi-modal fusion itself, and most literature follows traditional classification rules, dividing into three categories: early fusion, deep (feature) fusion, and late fusion, focusing on the feature fusion stage in the algorithms, whether at the data level, feature level, or proposal level. This classification rule has two problems: first, there is no clear definition of the feature representation at each level; second, it treats the two branches of LiDAR and cameras from a symmetric perspective, thus obscuring the cases of level feature fusion in the LiDAR branch and data level feature fusion in the camera branch [106]. In summary, although the traditional classification method is intuitive, it is no longer suitable for the current development of multi-modal fusion algorithms, to some extent hindering researchers from conducting research and analysis from a systematic perspective.
3 Tasks and Public Competitions
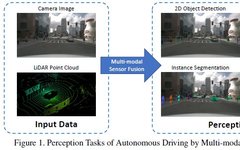
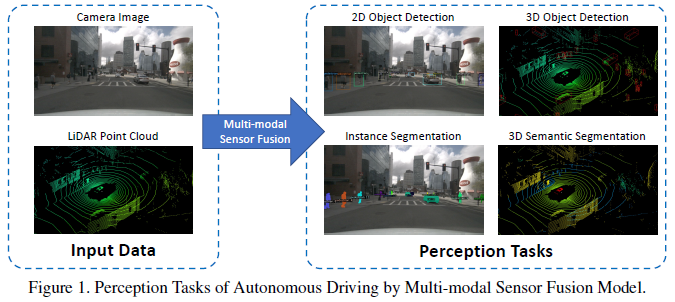
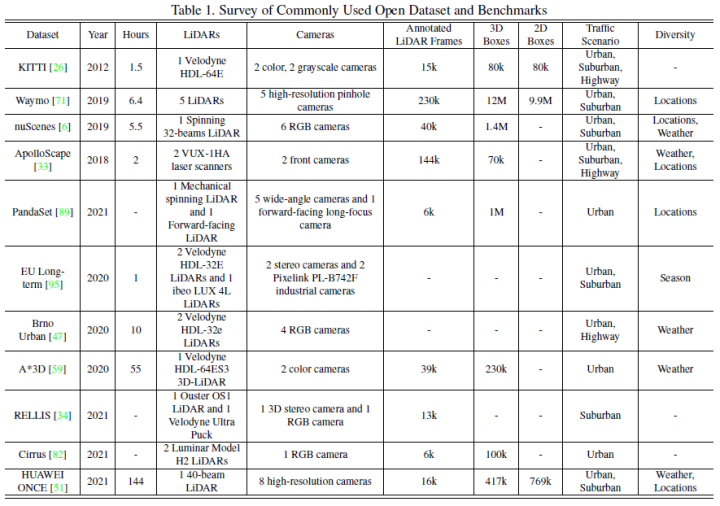
Common perception tasks include object detection, semantic segmentation, depth completion, and prediction, among others. This article focuses on detection and segmentation, such as the detection of obstacles, traffic lights, traffic signs, and the segmentation of lane lines and freespace. The autonomous driving perception tasks are shown in the figure below:The commonly used public datasets mainly include KITTI, Waymo, and nuScenes. The figure below summarizes the datasets related to autonomous driving perception and their characteristics.
4 Fusion Methods
Multi-modal fusion relies on data representation forms. The data representation in the image branch is relatively simple, generally referring to RGB format or grayscale images, but the LiDAR branch has a high dependence on data formats, and different data formats lead to completely different downstream model designs. In summary, it includes three major directions: point-based, voxel-based, and 2D mapped point cloud representation.Traditional classification methods divide multi-modal fusion into the following three types:
Early fusion (data-level fusion) refers to directly fusing different modal raw sensor data through spatial alignment.
Deep fusion (feature-level fusion) refers to fusing cross-modal data in the feature space through concatenation or element-wise multiplication.
Late fusion (object-level fusion) refers to fusing the prediction results of each modal model to make the final decision.
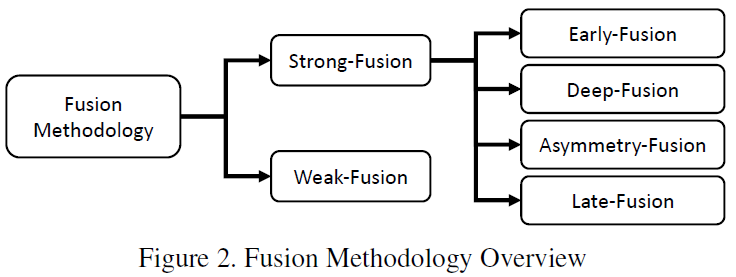
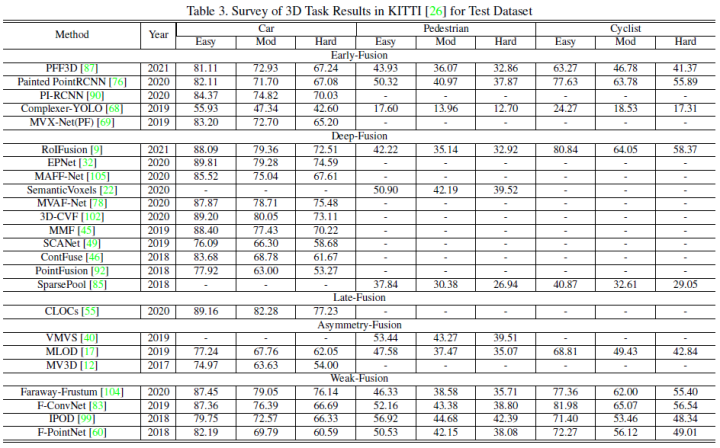
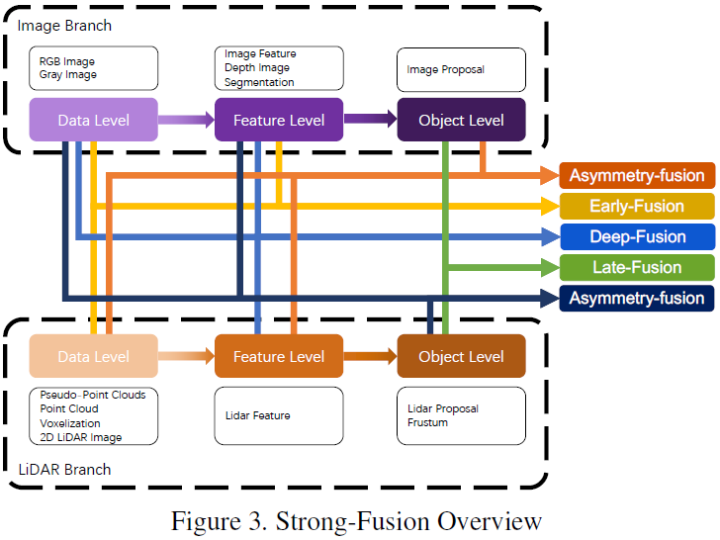
This article adopts the classification method shown in the figure below, overall divided into strong fusion and weak fusion, with strong fusion further subdivided into: early fusion, deep fusion, asymmetric fusion, and late fusion.This article uses the 3D detection task and BEV detection task of KITTI to compare the performance of various multi-modal fusion algorithms. The figure below shows the results of the BEV detection test set:The figure below shows the results of the 3D detection test set:
5 Strong Fusion
Based on the different combination stages of LiDAR and camera data representations, this article subdivides strong fusion into: early fusion, deep fusion, asymmetric fusion, and late fusion. As shown in the figure above, each submodule of strong fusion is highly dependent on LiDAR point clouds rather than camera data.
Early Fusion
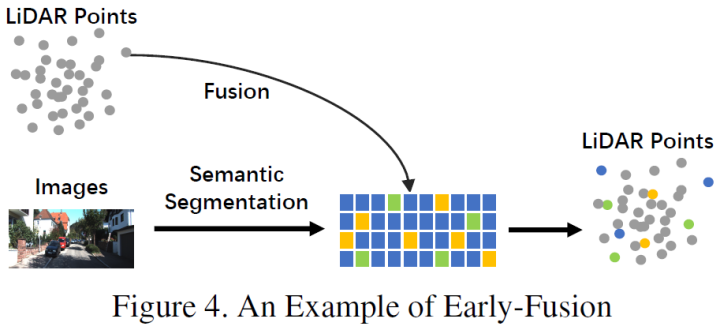
Unlike the traditional definition of data-level fusion, which is a method of directly fusing each modal data at the raw data level through spatial alignment and projection, early fusion at the data level fuses LiDAR data and data-level camera data or feature-level data. An example of early fusion can be seen in the model in Figure 4.Unlike the early fusion defined by traditional classification methods, the early fusion defined in this article refers to a method of directly fusing each modal data at the raw data level through spatial alignment and projection. Early fusion at the data level refers to the fusion of LiDAR data, and at the data level or feature level, it fuses image data, as illustrated below:In the LiDAR branch, point clouds have various expression forms, such as reflection maps, voxelized tensors, front views/distance views/BEV views, and pseudo point clouds, etc. Although these data combined with different backbone networks have different intrinsic features, most data, except for pseudo point clouds [79], are processed and generated according to certain rules. Additionally, compared to feature space embedding, these data from LiDAR have strong interpretability and can be directly visualized.In the image branch, the strict definition of data-level should be RGB or grayscale images, but this definition lacks universality and rationality. Therefore, this article extends the data-level definition of image data in the early fusion stage to include both data-level and feature-level data. It is worth mentioning that this article also considers the semantic segmentation prediction results as a form of early fusion (image feature level), firstly because it is beneficial for 3D object detection, and secondly because the “object-level” features of semantic segmentation differ from the final object-level proposals of the entire task.
Deep Fusion
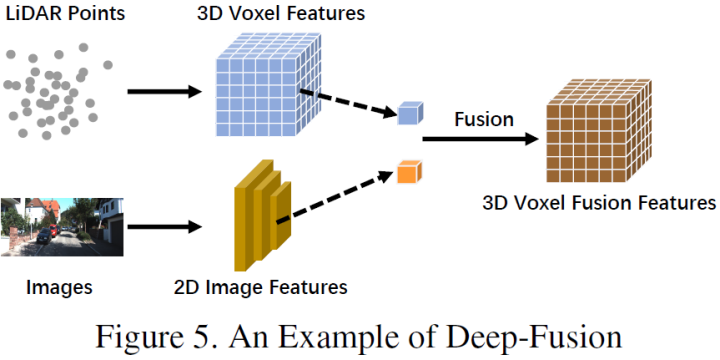
Deep fusion, also known as feature-level fusion, refers to the feature-level fusion of multi-modal data in the LiDAR branch, while in the image branch, it performs fusion at the data set and feature level. For example, some methods use feature lifting to separately obtain embedding representations of LiDAR point clouds and images, and fuse the features of the two modalities through a series of downstream modules [32, 102]. However, unlike other strong fusions, deep fusion sometimes merges features in a cascading manner [4, 32, 46], both of which utilize raw and high-level semantic information. The schematic diagram is as follows:
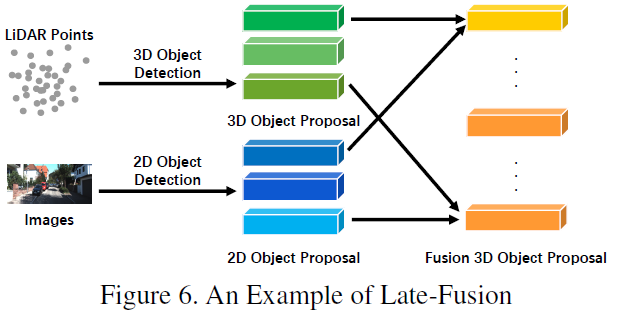
Late Fusion
Late fusion, also known as object-level fusion, refers to the fusion of the prediction results (or proposals) of multiple modalities. For example, some late fusion methods utilize the outputs of LiDAR point clouds and images for fusion [55]. The data formats of the proposals from the two branches should be consistent with the final results, but there are certain differences in quality, quantity, and accuracy. Late fusion can be seen as an integration method that optimizes the final proposals with multi-modal information, as illustrated in the schematic diagram below:
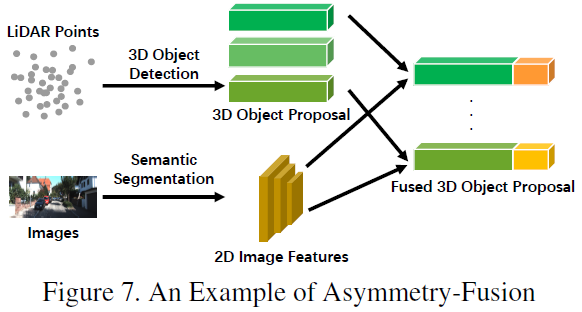
Asymmetric Fusion
The last type of strong fusion is asymmetric fusion, which refers to fusing the object-level information of one branch with the data-level or feature-level information of other branches. The above three fusion methods treat each branch of multi-modal equally, while asymmetric fusion emphasizes that at least one branch dominates, and other branches provide auxiliary information to predict the final result. The diagram below illustrates asymmetric fusion, where in the proposal stage, asymmetric fusion only has one branch’s proposal, while late fusion has proposals from all branches.
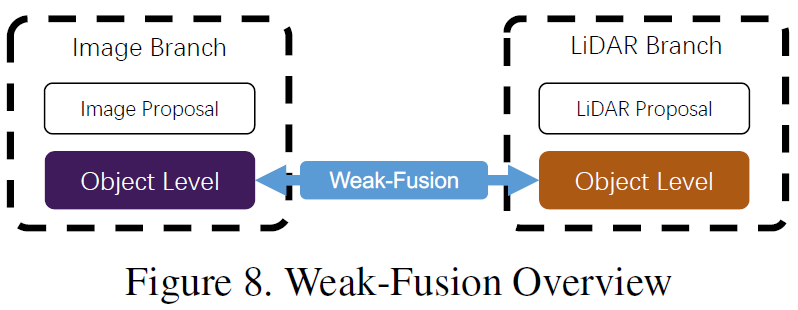
6 Weak Fusion
Unlike strong fusion, weak fusion methods do not directly fuse data, features, or objects from multi-modal branches, but process data in other forms. The figure below shows the basic framework of weak fusion algorithms. Weak fusion methods typically use rule-based methods to utilize the data from one modality as a supervisory signal to guide the interaction of another modality. For instance, a 2D proposal from CNN in the image branch may lead to truncation in the original LiDAR point cloud, and weak fusion directly inputs the original LiDAR point cloud into the LiDAR backbone to output the final proposal [60].
7 Other Fusion Methods
There are also some works that do not belong to any of the aforementioned paradigms, as they use various fusion methods within the framework of model design. For example, [39] combines deep fusion and late fusion, while [77] combines early fusion. These methods are not mainstream in fusion algorithm design, and this article uniformly categorizes them as other fusion methods.
8 Opportunities for Multi-Modal Fusion
In recent years, multi-modal fusion methods for autonomous driving perception tasks have made rapid progress, from more advanced feature representations to more complex deep learning models [15, 81]. However, there are still some unresolved issues that need to be addressed, and this article summarizes several potential improvement directions for the future.
More Advanced Fusion Methods
The current fusion models suffer from misalignment and information loss [13,67,98]. Additionally, flat fusion operations [20, 76] also hinder further improvements in perception task performance. The summary is as follows:
Misalignment and Information Loss: The intrinsic and extrinsic differences between cameras and LiDAR are significant, and the data from the two modalities need coordinate alignment. Traditional early fusion and deep fusion methods utilize calibration information to directly project all LiDAR points into the camera coordinate system, and vice versa [54,69,76]. However, due to installation positions and sensor noise, this pixel-wise alignment is not accurate enough. Therefore, some works [90] utilize surrounding information to supplement and achieve better performance. Furthermore, there are also other information losses during the input and feature space conversion process. Typically, dimensionality reduction operations inevitably lead to significant information loss, such as mapping 3D LiDAR point clouds into 2D BEV images, which loses height information. Therefore, it is worth considering mapping multi-modal data into another high-dimensional space designed specifically for fusion, thereby effectively utilizing raw data and reducing information loss.
More Reasonable Fusion Operations: Currently, many methods use concatenation or element-wise multiplication for fusion [69, 77]. These simple operations may not fuse data with significantly different distributions, making it difficult to fit the semantic gaps between two modalities. Some works attempt to use more complex cascading structures to fuse data and improve performance [12,46]. In future research, mechanisms like bilinear mapping [3,25,38] can be considered to fuse features with different characteristics.
Utilization of Multi-Source Information
The front-view single-frame image is a typical scenario for autonomous driving perception tasks [26]. However, most frameworks can only utilize limited information and have not designed auxiliary tasks in detail to facilitate the understanding of driving scenes. The summary is as follows:
Adopting More Potential Information: Existing methods [81] lack effective utilization of information from various dimensions and sources. Most focus on the single-frame multi-modal data in the front view. This leads to other meaningful data not being fully utilized, such as semantic, spatial, and scene context information. Some works [20, 76, 90] attempt to use semantic segmentation results as auxiliary tasks, while other models may leverage intermediate layer features from CNN backbones. In autonomous driving scenarios, many downstream tasks with explicit semantic information may greatly enhance object detection performance, such as detecting lane lines, traffic lights, and traffic signs. Future research can combine downstream tasks to construct a complete semantic understanding framework of urban scenes to enhance perception performance. Additionally, [63] combines inter-frame information to improve performance. Time series information contains serialized monitoring signals, providing more stable results compared to single-frame methods. Therefore, future work can consider more deeply utilizing temporal, contextual, and spatial information to achieve performance breakthroughs.
Self-Supervised Representation Learning: Mutual supervisory signals naturally exist in cross-modal data sampled from the same real-world scene but from different angles. However, due to the lack of deep understanding of the data, current methods cannot mine the interrelationships among various modalities. Future research can focus on how to utilize multi-modal data for self-supervised learning, including pre-training, fine-tuning, or contrastive learning. Through these advanced mechanisms, fusion algorithms will deepen the model’s understanding of data at a deeper level while achieving better performance.
Intrinsic Sensor Issues
Domain bias and resolution are highly related to real-world scenes and sensors [26]. These defects hinder the large-scale training and real-time performance of autonomous driving deep learning models.
Domain Bias: In autonomous driving perception scenarios, the raw data extracted from different sensors is accompanied by severe domain-related features. Different cameras have different optical characteristics, while LiDAR may vary from mechanical to solid-state structures. More importantly, the data itself may have domain bias, such as weather, season, or geographical location [6,71], even if captured by the same sensor. This affects the generalization of detection models, making it difficult to adapt effectively to new scenarios. Such defects hinder the collection of large-scale datasets and the reusability of original training data. Therefore, future work can focus on finding methods to eliminate domain bias and adaptively integrate different data sources.
Resolution Conflicts: Different sensors often have different resolutions [42, 100]. For example, the spatial density of LiDAR is significantly lower than that of images. Regardless of the projection method used, information loss will occur due to the lack of corresponding relationships. This may lead to the model being dominated by data from a specific modality, whether due to different resolutions of feature vectors or imbalances in raw information. Therefore, future work can explore a new data representation system compatible with sensors of different spatial resolutions.
9 References
[1] https://zhuanlan.zhihu.com/p/470588787[2] Multi-modal Sensor Fusion for Auto Driving Perception: A Survey