MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering audiences including NLP master’s and PhD students, university professors, and corporate researchers.
The Vision of the Community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for beginners.
Reprinted from | Machine Heart
Embodied intelligence is a necessary path to achieving general artificial intelligence, with its core being the completion of complex tasks through the interaction of agents with digital spaces and the physical world. In recent years, multimodal large models and robotic technologies have made significant progress, making embodied intelligence a new focus of global technological and industrial competition. However, there is currently a lack of a comprehensive review that analyzes the development status of embodied intelligence. Therefore, researchers from the Pengcheng Laboratory’s Multi-Agent and Embodied Intelligence Research Institute, in collaboration with the HCP Laboratory of Sun Yat-sen University, have conducted a comprehensive analysis of the latest developments in embodied intelligence, launching the world’s first review of embodied intelligence in the era of multimodal large models.
This review surveyed nearly 400 pieces of literature and comprehensively analyzed the research on embodied intelligence from multiple dimensions. It first introduces some representative embodied robots and embodied simulation platforms, deeply analyzing their research focuses and limitations. Next, it thoroughly analyzes four main research areas: 1) embodied perception, 2) embodied interaction, 3) embodied agents, and 4) transfer from virtual to reality, covering the most advanced methods, fundamental paradigms, and comprehensive datasets. Additionally, the review discusses the challenges faced by embodied agents in digital spaces and the physical world, emphasizing the importance of proactive interaction in dynamic digital and physical environments. Finally, the review summarizes the challenges and limitations of embodied intelligence and discusses potential future directions. This review aims to provide foundational references for embodied intelligence research and promote related technological innovations. Furthermore, the review has published an embodied intelligence paper list on GitHub, and related papers and code repositories will be continuously updated, welcome to follow.

-
Paper link: https://arxiv.org/pdf/2407.06886
-
Embodied Intelligence Paper List: https://github.com/HCPLab-SYSU/Embodied_AI_Paper_List
1. The Past and Present of Embodied Intelligence
The concept of embodied intelligence was first proposed by Alan Turing in the embodied Turing test established in 1950, aiming to determine whether an agent can demonstrate intelligence not limited to solving abstract problems in virtual environments (digital spaces) but also cope with the complexity and unpredictability of the physical world. Therefore, the development of embodied intelligence is seen as a fundamental pathway to achieving general artificial intelligence. It is particularly important to explore the complexity of embodied intelligence, assess its current development status, and contemplate its future trajectory. Today, embodied intelligence encompasses several key technologies, including computer vision, natural language processing, and robotics, with the most representative being embodied perception, embodied interaction, embodied agents, and transfer from virtual to reality. In embodied tasks, embodied agents must fully understand human intentions in language instructions, proactively explore their surrounding environment, comprehensively perceive multimodal elements from virtual and physical environments, and perform appropriate actions to complete complex tasks. The rapid advancement of multimodal models demonstrates greater diversity, flexibility, and generalization capabilities in complex environments compared to traditional deep reinforcement learning methods. The state-of-the-art visual encoder pre-trained visual representations provide precise estimates of object categories, poses, and geometries, enabling embodied models to comprehensively perceive complex and dynamic environments. Powerful large language models allow robots to better understand human language instructions and provide feasible methods for aligning visual and language representations in embodied robots. World models demonstrate significant simulation capabilities and a good understanding of physical laws, enabling embodied models to comprehensively understand physical and real environments. These advancements enable embodied agents to comprehensively perceive complex environments, interact naturally with humans, and reliably perform tasks. The following figure illustrates a typical architecture of an embodied agent.
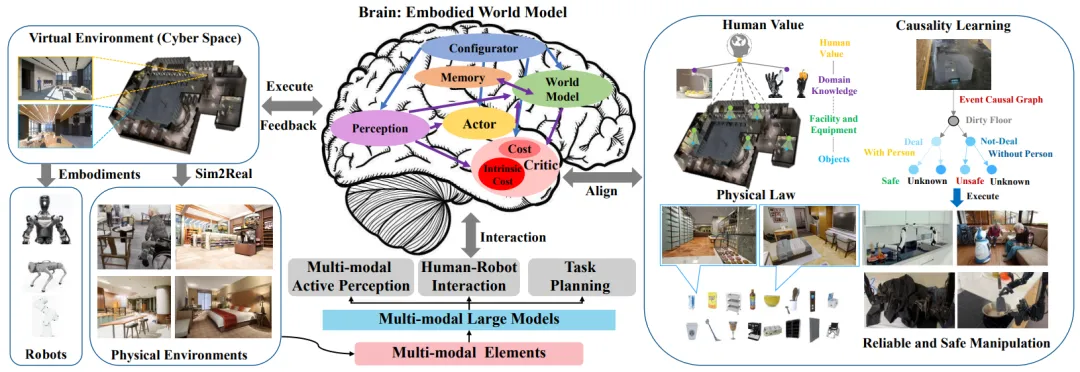 Framework of Embodied Agents
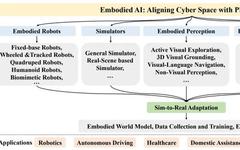
In this review, we provide a comprehensive overview of the current progress of embodied intelligence, including: (1) Embodied Robots — Hardware solutions for embodied intelligence in the physical world; (2) Embodied Simulation Platforms — Digital spaces for efficiently and safely training embodied agents; (3) Embodied Perception — Actively perceiving 3D spaces and integrating multiple sensory modalities; (4) Embodied Interaction — Effectively interacting with the environment and even altering it to complete specified tasks; (5) Embodied Agents — Utilizing multimodal large models to understand abstract instructions and break them down into a series of sub-tasks to complete gradually; (6) Transfer from Virtual to Reality — Generalizing skills learned in digital spaces to the physical world. The following figure illustrates the framework covered by embodied intelligence from digital spaces to the physical world. This review aims to provide comprehensive background knowledge, research trends, and technical insights on embodied intelligence.
Framework of Embodied Agents
In this review, we provide a comprehensive overview of the current progress of embodied intelligence, including: (1) Embodied Robots — Hardware solutions for embodied intelligence in the physical world; (2) Embodied Simulation Platforms — Digital spaces for efficiently and safely training embodied agents; (3) Embodied Perception — Actively perceiving 3D spaces and integrating multiple sensory modalities; (4) Embodied Interaction — Effectively interacting with the environment and even altering it to complete specified tasks; (5) Embodied Agents — Utilizing multimodal large models to understand abstract instructions and break them down into a series of sub-tasks to complete gradually; (6) Transfer from Virtual to Reality — Generalizing skills learned in digital spaces to the physical world. The following figure illustrates the framework covered by embodied intelligence from digital spaces to the physical world. This review aims to provide comprehensive background knowledge, research trends, and technical insights on embodied intelligence.
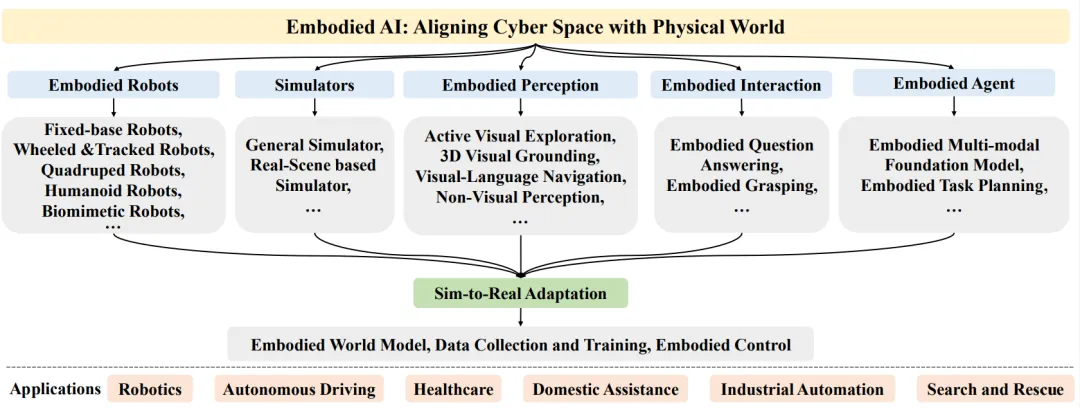 Overall Structure of This Review
Overall Structure of This Review
2. Embodied Robots
Embodied agents actively interact with the physical environment, covering a wide range of embodied forms, including robots, smart appliances, smart glasses, and autonomous vehicles. Among them, robots are one of the most prominent embodied forms and receive significant attention. Depending on different application scenarios, robots are designed in various forms to fully leverage their hardware characteristics to complete specific tasks. As shown in the following figure, embodied robots can generally be divided into: (1) Fixed-base robots, such as robotic arms, commonly used in laboratory automation synthesis, education, and industry; (2) Wheeled robots, known for their efficient mobility, widely used in logistics, warehousing, and security inspections; (3) Tracked robots, with strong off-road capabilities and mobility, showing potential in agriculture, construction, and disaster scenarios; (4) Quadruped robots, known for their stability and adaptability, very suitable for exploration in complex terrains, rescue tasks, and military applications; (5) Humanoid robots, known for their dexterous hands, widely used in service industries, healthcare, and collaborative environments; (6) Biomimetic robots, executing tasks in complex and dynamic environments by simulating the effective movements and functions of natural organisms.
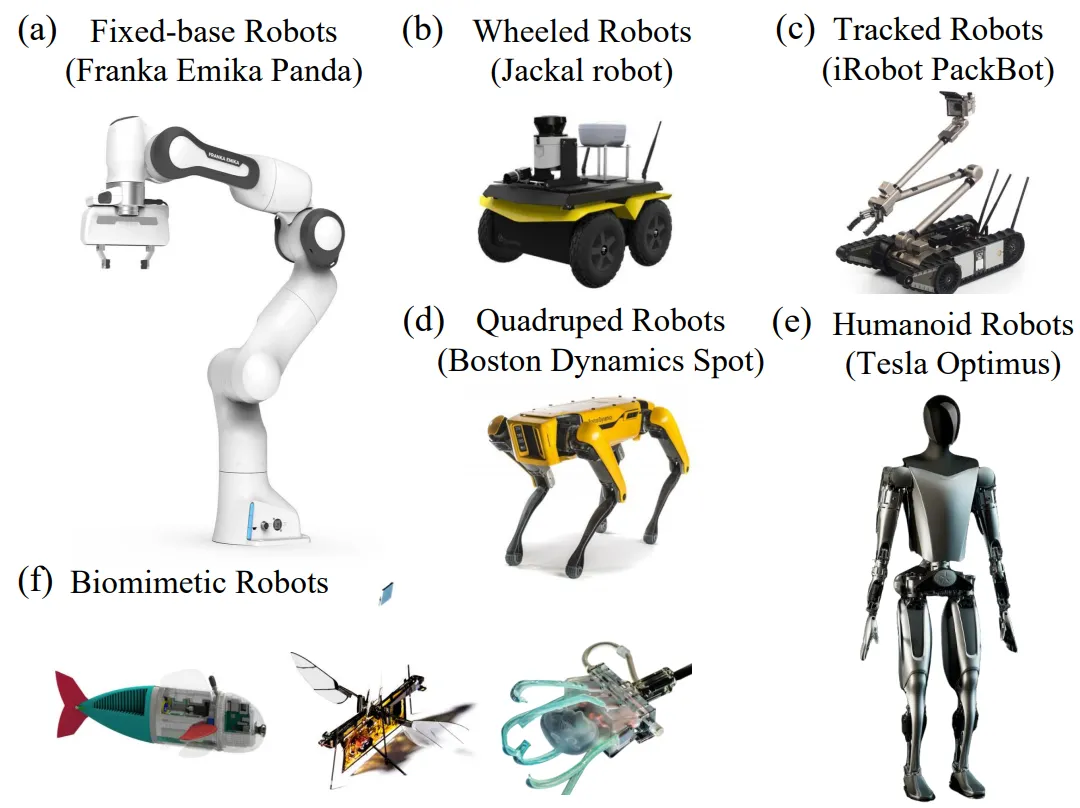 Different Forms of Embodied Robots
Different Forms of Embodied Robots
3. Embodied Simulation Platforms
Embodied simulation platforms are crucial for embodied intelligence as they provide cost-effective experimental means, ensuring safety by simulating potential hazardous scenarios, scalable testing in diverse environments, rapid prototyping capabilities, and controlled environments for precise research, generating data for training and evaluation, and providing standardized benchmarks for algorithm comparisons. To enable agents to interact with the environment, a realistic simulation environment must be constructed. This requires consideration of the physical properties of the environment, the attributes of objects, and their interactions. As shown in the following figure, this review will analyze two types of simulation platforms: general platforms based on low-level simulation and simulation platforms based on real scenarios.
General Simulation Platform
Simulation Platform Based on Real Scenarios
4. Embodied Perception
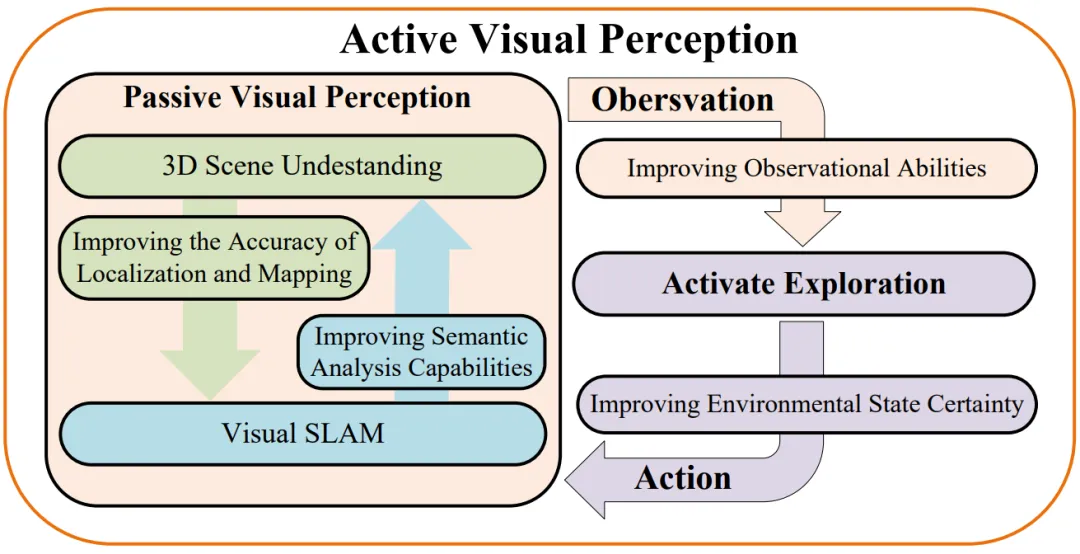
The “North Star” of future visual perception is embodied-centered visual reasoning and social intelligence. As shown in the following figure, unlike merely recognizing objects in images, agents with embodied perception capabilities must move in the physical world and interact with the environment, requiring a deeper understanding of three-dimensional spaces and dynamic environments. Embodied perception requires visual perception and reasoning capabilities, understanding three-dimensional relationships in scenes, and predicting and executing complex tasks based on visual information. This review introduces aspects such as active visual perception, 3D visual localization, visual language navigation, and non-visual perception (tactile sensors).
Active Visual Perception Framework
5. Embodied Interaction
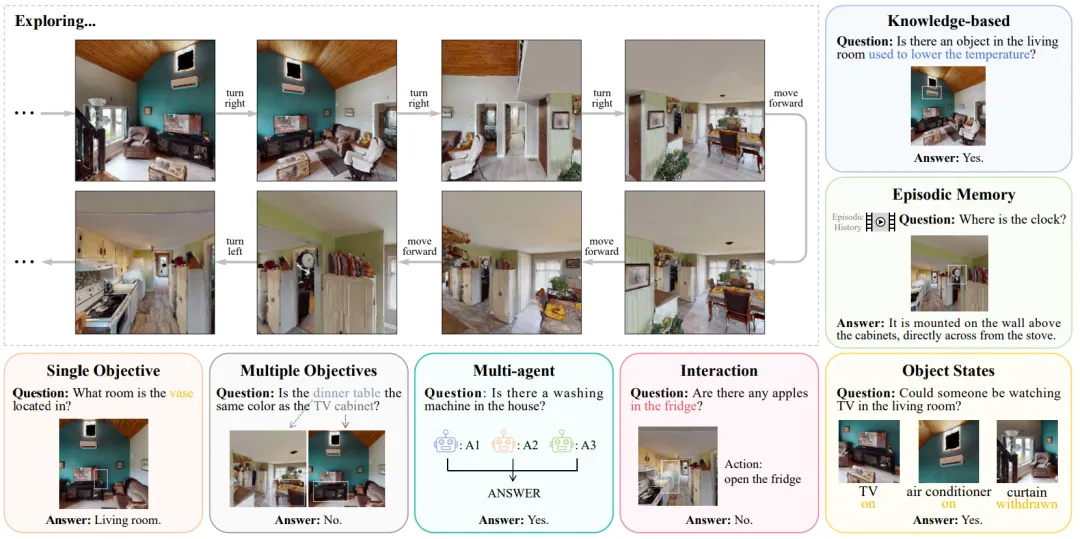
Embodied interaction refers to the scenarios where agents interact with humans and the environment in physical or simulated spaces. Typical embodied interaction tasks include embodied question answering and embodied grasping. As shown in the following figure, in the embodied question answering task, the agent needs to explore the environment from a first-person perspective to gather the information needed to answer questions. Agents with autonomous exploration and decision-making capabilities must consider what actions to take to explore the environment and decide when to stop exploring to answer questions, as shown in the following figure.
Embodied Question Answering Framework
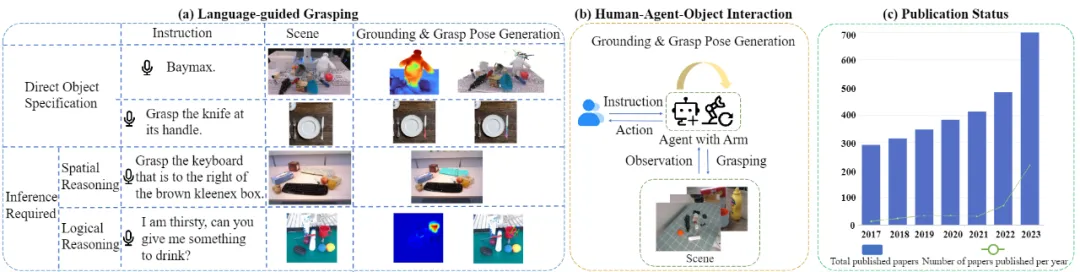
In addition to interacting with humans through question answering, embodied interaction also involves executing operations based on human instructions, such as grasping and placing objects, thus completing interactions among agents, humans, and objects. As shown in the figure, embodied grasping requires comprehensive semantic understanding, scene perception, decision-making, and robust control planning. Embodied grasping methods combine traditional robotic kinematic grasping with large models (such as large language models and vision-language foundational models), enabling agents to perform grasping tasks under multimodal perception, including visual active perception, language understanding, and reasoning.
Language-Guided Interactive Grasping Framework
6. Embodied Agents
Agents are defined as autonomous entities that can perceive the environment and take actions to achieve specific goals. Recent advancements in multimodal large models further expand the applications of agents in real-world scenarios. When these multimodal large model-based agents are embodied as physical entities, they can effectively transfer their capabilities from virtual spaces to the physical world, thus becoming embodied agents. To operate in the information-rich and complex real world, embodied agents have been developed with powerful multimodal perception, interaction, and planning capabilities. As shown in the figure, to complete tasks, embodied agents typically involve the following processes:
(1) Decomposing abstract and complex tasks into concrete sub-tasks, i.e., high-level embodied task planning.
(2) Gradually implementing these sub-tasks by effectively utilizing embodied perception and embodied interaction models, or leveraging the policy functions of foundational models, which is known as low-level embodied action planning.
It is noteworthy that task planning involves thinking before actions, thus typically considering in digital spaces. In contrast, action planning must consider effective interaction with the environment and feed this information back to the task planner to adjust task planning. Therefore, aligning and promoting their capabilities from digital spaces to the physical world is crucial for embodied agents.
Framework of Embodied Agents Based on Multimodal Large Models
7. Transfer from Virtual to Reality
The transfer from virtual to reality (Sim-to-Real adaptation) in embodied intelligence refers to the process of transferring capabilities or behaviors learned in simulated environments (digital spaces) to the real world (physical world). This process includes validating and improving the effectiveness of algorithms, models, and control strategies developed in simulation to ensure they perform stably and reliably in physical environments. To achieve simulation-to-reality adaptation, embodied world models, data collection and training methods, and embodied control algorithms are three key elements. The following figure illustrates five different Sim-to-Real paradigms.
Five Sim-to-Real Transfer Schemes
8. Challenges and Future Directions
Despite the rapid development of embodied intelligence, it faces several challenges and presents exciting future directions:
(1) High-Quality Robot Datasets.Obtaining sufficient real-world robot data remains a significant challenge. Collecting this data is both time-consuming and resource-intensive. Relying solely on simulated data exacerbates the gap between simulation and reality. Creating diverse real-world robot datasets requires close and extensive collaboration between various institutions. Additionally, developing more realistic and efficient simulators is crucial for improving the quality of simulated data. To construct general embodied models capable of achieving cross-scenario and cross-task applications in the field of robotics, large-scale datasets must be built, utilizing high-quality simulated environment data to assist real-world data.
(2) Effective Utilization of Human Demonstration Data.Efficient utilization of human demonstration data includes using actions and behaviors demonstrated by humans to train and improve robotic systems. This process involves collecting, processing, and learning from large-scale, high-quality datasets where humans perform tasks that robots need to learn. Therefore, it is important to effectively utilize a large amount of unstructured, multi-label, and multimodal human demonstration data combined with action label data to train embodied models, enabling them to learn various tasks in a relatively short time. By efficiently utilizing human demonstration data, robotic systems can achieve higher levels of performance and adaptability, making them more capable of executing complex tasks in dynamic environments.
(3) Cognition of Complex Environments.Cognition of complex environments refers to the ability of embodied agents to perceive, understand, and navigate complex real-world environments in physical or virtual settings. For unstructured open environments, current work often relies on the task decomposition mechanism of pre-trained LLMs, utilizing extensive common knowledge for simple task planning, but lacks specific scene understanding. Enhancing knowledge transfer and generalization capabilities in complex environments is crucial. A truly multifunctional robotic system should be able to understand and execute natural language instructions across various different and unseen scenarios. This requires the development of adaptable and scalable embodied agent architectures.
(4) Long-Term Task Execution.Executing a single instruction often involves robots completing long-term tasks, such as commands like “clean the kitchen,” which include rearranging items, sweeping, wiping tables, and other activities. Successfully completing these tasks requires robots to plan and execute a series of low-level actions over an extended period. Although current high-level task planners have shown initial success, they often prove insufficient in diverse scenarios due to a lack of adjustment for embodied tasks. Addressing this challenge requires developing efficient planners with strong perceptual capabilities and extensive common knowledge.
(5) Causal Discovery.Existing data-driven embodied agents make decisions based on correlations within the data. However, this modeling approach fails to enable models to truly understand the causal relationships between knowledge, behaviors, and environments, leading to biased strategies. This makes it difficult for them to operate in real-world environments in an interpretable, robust, and reliable manner. Therefore, embodied agents need to be driven by world knowledge and possess autonomous causal reasoning capabilities.
(6) Continuous Learning.In robotic applications, continuous learning is crucial for deploying robotic learning strategies in diverse environments, yet this area remains underexplored. Although some recent studies have explored subtopics of continuous learning, such as incremental learning, rapid motion adaptation, and human-robot interaction learning, these solutions are often designed for single tasks or platforms and have not considered foundational models. Open research questions and viable approaches include: 1) Mixing different proportions of previous data distributions when fine-tuning on the latest data to alleviate catastrophic forgetting, 2) Developing effective prototypes for reasoning learning on new tasks from previous distributions or curricula, 3) Improving the training stability and sample efficiency of online learning algorithms, 4) Identifying principled methods for seamlessly integrating large-capacity models into control frameworks, potentially through hierarchical learning or slow-fast control for real-time reasoning.
(7) Unified Evaluation Benchmarks.Despite many benchmarks available for evaluating low-level control strategies, they often exhibit significant differences in skill assessment. Moreover, the objects and scenes included in these benchmarks are often limited by simulators. To comprehensively evaluate embodied models, realistic simulators must be used to cover benchmarks with various skills. In high-level task planning, many benchmarks assess planning capabilities through question-answering tasks. However, a more ideal approach is to comprehensively assess the execution capabilities of high-level task planners and low-level control strategies, especially in executing long-term tasks and measuring success rates, rather than relying solely on the separate evaluation of planners. This comprehensive approach can provide a more thorough assessment of the capabilities of embodied intelligent systems.
In summary, embodied intelligence enables agents to perceive, cognize, and interact with various objects in digital spaces and the physical world, demonstrating its significant importance in achieving general artificial intelligence. This review comprehensively reviews embodied robots, embodied simulation platforms, embodied perception, embodied interaction, embodied agents, robot control from virtual to reality, and future research directions, which are significant for promoting the development of embodied intelligence.
Technical Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction
(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)
to apply to join the technical group for Natural Language Processing/Pytorch and others
About Us
MLNLP Community is a grassroots academic community jointly established by domestic and foreign scholars in machine learning and natural language processing. It has now developed into a well-known community in machine learning and natural language processing, aiming to promote progress between the academic and industrial circles of machine learning and natural language processing and the vast number of enthusiasts.
The community can provide an open communication platform for related practitioners’ further studies, employment, and research. Everyone is welcome to pay attention to and join us.