In the era of big data and artificial intelligence, the position of literature as a core knowledge carrier has not changed. However, the current methods of literature resource management, such as information retrieval, databases, subject headings, and classification systems, cannot meet the higher-level needs of researchers.
The knowledge graph is a novel mass knowledge management technology that has emerged in the context of big data. It centers on literature, organizing multi-source and scattered literature to better manage and provide knowledge services. The “knowledge graph” marks the practical application of half a century of academic research results in the fields of semantics and knowledge representation.
The study of spleen and stomach diseases in traditional Chinese medicine has a long history and a vast literature resource, containing considerable knowledge. It is essential to utilize modern information technology to excavate, analyze, and organize this knowledge to establish a more solid theoretical and knowledge system for widespread clinical guidance.
This project builds a knowledge graph for spleen and stomach diseases in traditional Chinese medicine based on the accumulated work and data resources in the field of spleen and stomach disease knowledge engineering and literature research, which is applicable to literature resource management, knowledge organization, and knowledge services, aligning with the development trends of traditional Chinese medicine informatics and library science.
To design a knowledge graph system that aligns with the original theory of spleen and stomach diseases and accurately reflects the differential diagnosis and treatment thinking of famous doctors, focusing on the core elements of “disease, syndrome, symptom, theory, method, prescription, and medicine”; to design and develop methods for automatic construction, automatic updating, and knowledge integration of the knowledge graph.
To establish a literature resource organization system and knowledge service system based on the spleen and stomach disease knowledge graph, achieving precise literature retrieval, knowledge visualization, and intelligent knowledge services (such as knowledge reasoning, knowledge recommendation, and knowledge Q&A).
Focusing on clinical content related to spleen and stomach diseases in traditional Chinese medicine, systematically sorting the knowledge system, automatically extracting high-quality knowledge content from literature, establishing connections between various knowledge points, and building the spleen and stomach disease knowledge graph:
First, design the model of the knowledge graph, defining semantic types, entity attributes, and semantic relationships.
Extract traditional Chinese medicine knowledge from various data sources, including terminology, databases, textbooks, journals, and medical cases, to construct the knowledge graph, involving technical aspects such as data preprocessing, knowledge extraction, knowledge integration, and validation.
Based on the knowledge graph, aggregate literature, data, knowledge, and other resources to build a knowledge service system, realizing traditional Chinese medicine knowledge service functions (such as data visualization, query, Q&A, etc.), serving users of traditional Chinese medicine knowledge.
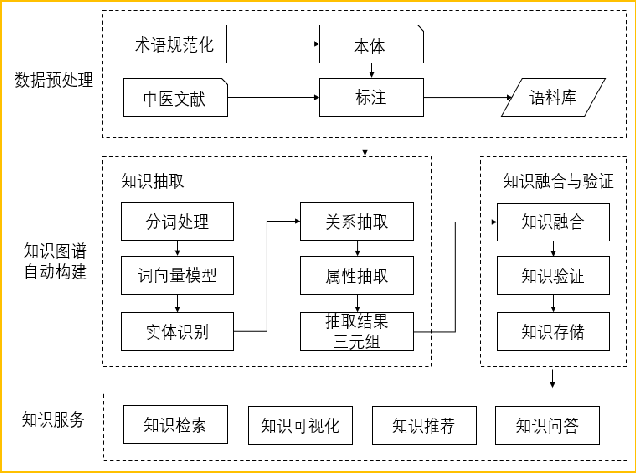
Expand and diverge from the core diseases, syndromes, and clinical symptoms within the category of spleen and stomach diseases in traditional Chinese medicine, extending to theory, methods, prescriptions, and medicines, including theoretical concepts, thoughts, principles, famous doctors, treatment principles, treatment methods, prescriptions, traditional Chinese medicines, various diagnostic and therapeutic techniques, efficacy, prognosis, and other core concepts, establishing semantic relationships between these concepts and clarifying the core attributes of the concepts.
1. Collect literature to form a specialized literature database for spleen and stomach diseases:
Further collect and organize ancient literature, medical cases, high-quality evidence, the latest research progress, and expert articles related to spleen and stomach diseases, filling in gaps and updating literature, establishing a complete specialized literature database for spleen and stomach diseases on the literature big data platform.
Search for modern literature on spleen and stomach diseases from the past ten years in the Chinese Academy of Traditional Chinese Medicine’s literature database (search terms include “stomach pain,” “epigastric pain,” “bloating,” “dysphagia,” “gastric atony,” “diarrhea,” “food accumulation,” “gastric dysfunction,” “gastrointestinal neurosis,” “functional constipation,” “gastritis,” “gastric ulcer,” “duodenal ulcer,” “functional dyspepsia,” “irritable bowel syndrome,” “gastrointestinal spasm,” “gastrointestinal bleeding”), totaling 7,451 articles, which serves as the foundation for establishing the spleen and stomach disease literature database.
The fields in the literature database include: ID, cn_title, author, author_affiliation, reference, cn_digest, key_word, source, year, data_type.
2. Collect terminology systems and standards such as “Clinical Terminology of Traditional Chinese Medicine” and “Classification and Codes of Traditional Chinese Medicine Diseases and Syndromes,” to supplement the existing spleen and stomach disease ontology established by previous research:
Addressing the inconsistencies and non-standard usage of terms related to spleen and stomach diseases, phenomena of different names for the same disease and different names for the same syndrome, and different names for the same treatment methods, using “Classification and Codes of Traditional Chinese Medicine Diseases and Syndromes” and “Clinical Terminology of Traditional Chinese Medicine” as standards, supplementing the ontology library, and establishing standardized names for traditional Chinese medicine diseases, syndromes, treatment methods, and their corresponding relationships with different names to achieve term standardization.
Based on the examination of the ontology in the disease field, the Traditional Chinese Medicine Language System (TCMLS), and the Traditional Chinese Medicine Clinical Terminology System (TCMCTS), a top-level framework for the ontology of functional gastrointestinal diseases in traditional Chinese medicine was first constructed using a top-down approach, and then a bottom-up approach was used to extract and classify concepts and relationships from authoritative materials. Through these two methods, we aim to improve and adjust the ontology system.
By referencing the research results of the above classification frameworks and combining the concepts (partially) extracted from authoritative materials, we constructed the top-level framework of the ontology for functional gastrointestinal diseases.
Currently, there are 125 classes, 14 object attributes (relationships), and 487 instances established.
3. Annotate these documents using the literature big data processing system to build a corpus for training machine learning algorithm models:
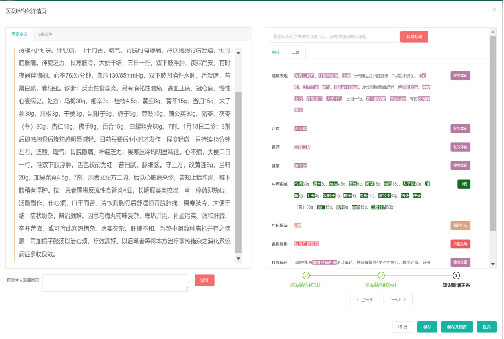
Based on the knowledge graph model, automatically construct the knowledge graph using various literature sources such as ancient texts, medical cases, journal literature, and guidelines through the combination of knowledge extraction and knowledge integration techniques, with core technologies including:
1) Entity extraction, also known as named entity recognition, which automatically and accurately identifies concepts such as diseases, syndromes, and clinical symptoms from literature;
2) Relation extraction, which discovers the relationships between entities from literature;
3) Attribute extraction, which extracts attribute information of entities from literature. The difference between attributes and relationships is that relationships reflect the external connections of entities, while attributes reflect the internal characteristics of entities.
2.1 Named Entity Recognition Based on ALBERT-BILSTM-CRF
Utilizing a deep learning algorithm model that combines Albert, bidirectional long short-term memory networks, and conditional random fields, the F1 score (a metric that considers both precision and recall) for entity recognition types such as traditional Chinese medicine treatments, traditional Chinese medicines, and Western medicine diagnoses is slightly above 80%. This model, combined with rule-based methods, has been put into production and significantly improved data processing efficiency. Further expansion of the corpus and improvement of deep learning algorithms are planned to enhance the precision of named entity recognition in traditional Chinese medicine.
2.2 Relation Extraction Based on BERT-Bidirectional GRU-Attention-FC Model
Combining BERT, bidirectional GRU, and Attention mechanism deep learning algorithm models, the extraction of six types of relations, including phenomenon expression, treatment, composition, treatment methods, application, and related diseases, has achieved ideal performance. The overall precision is 99.68%, recall is 99.73%, and F1 score is 99.66, making it ready for production use. Other relation extraction tasks in the field of traditional Chinese medicine are also expected to achieve similar accuracy after supplementing the corpus.
Convert existing ontologies and databases into knowledge graphs:Existing ontologies and structured databases in the field of traditional Chinese medicine spleen and stomach diseases provide high-quality resources for constructing knowledge graphs. Transforming these structured data into graphs is an efficient way to build graphs.
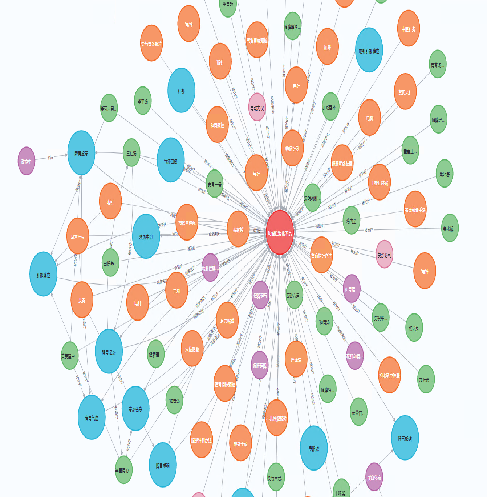
The knowledge in traditional Chinese medicine textbooks has formed a system that can accurately locate the chapters on spleen and stomach diseases. The naming of terms is standardized, and the authority and accuracy of the knowledge are high. Therefore, we selected traditional Chinese medicine textbooks such as Internal Medicine, Diagnosis, Pharmacology, and Prescriptions to extract knowledge of syndromes, diseases, prescriptions, traditional Chinese medicines, and symptoms, as well as their relationships, to include in the spleen and stomach disease knowledge graph.
A core literature source for constructing the knowledge graph is traditional Chinese medicine medical cases.
By applying semantic analysis and knowledge acquisition methods to medical case texts, preprocessing, word segmentation, semantic annotation, and structured knowledge extraction can be performed to extract structured clinical knowledge in traditional Chinese medicine from medical cases and fill it into the knowledge graph.
The resulting knowledge graph includes information on traditional Chinese medicine diagnosis, diseases that famous doctors specialize in, experience prescriptions, usage, dosage, clinical manifestations of diseases, treatment methods, and related symptoms, as well as health preservation methods.
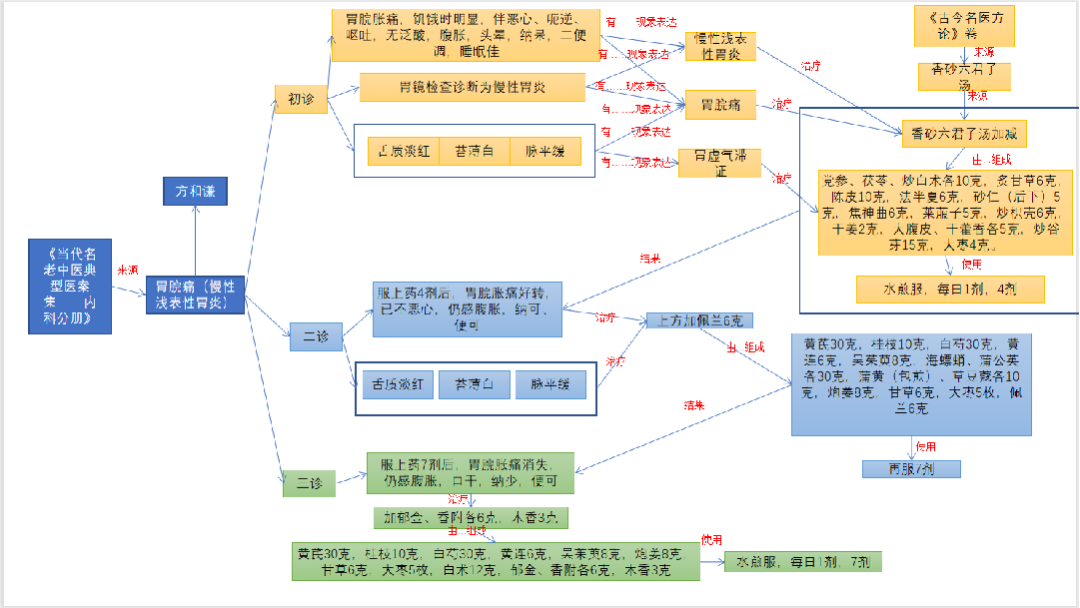
Text Annotation Format:
The accuracy and recall rates of entities such as diagnosis, syndrome, and treatment principles are high, and the predictive performance of this type of entity can be improved by increasing the sample size of these entities.
Text Annotation Format:
The annotation format for the training corpus is: “relation type label entity1$entity2$original text”. The original part replaces entity1 and entity2 with the same length of “#” symbols.
Examples of annotations are as follows:
1. 参苓白术散$白术$方用#####加减:太子参30g,黄柏15g,##15g,陈皮10g,炒山药15g,炒莲米15g,砂仁6g,薏苡仁30g,葛根15g,茯苓20g,炒白扁豆15g,制附片6g,桔梗6g,黄芩15g,黄连10g,厚朴花10g,炙甘草10g,生姜3片,红枣5枚
0. 急性甲型肝炎$口淡$入院诊断:######入院后连续三天给予肝炎灵,复方丹参注射液加能量静滴,口服清肝酶片等西药治疗,体温一直在38℃以上1月5日主管西医师邀笔者会诊查体温38℃,望其形体虚弱,全身及面目黄疸,自诉头痛,右肋隐痛,体倦,口苦##,尿黄,察舌质淡白,苔白厚,按脉弦细无力
The current relation extraction model has achieved ideal performance through prediction on test data. Its overall precision is 99.68%, recall is 99.73%, and F1 score is 99.66, far exceeding the initial estimated model performance standards, making it ready for production use.
Journal literature represents the latest research progress. To extract core knowledge from it, entities and relationships can be extracted from the titles and abstracts.
The main types of entities include traditional Chinese medicine diagnoses, Western medicine diagnoses, prescriptions, traditional Chinese medicines, therapies, clinical manifestations, etc.; relationships include treatment, phenomenon expression, etc.
Due to the vast amount of literature, we explore using automated methods for extraction, with manual checks on the extracted entities and relationships.
Experimental Setup:Select 7,346 pieces of literature on spleen and stomach diseases for extraction, using the model Albert-Bilstm-CRF, and manually check the extracted entities and relationships.
Since 2013, we have been constructing the traditional Chinese medicine knowledge graph system based on semantic standards in the field of traditional Chinese medicine, utilizing terminology systems, databases, literature, and other resources.
Currently, this system has become a large knowledge system composed of 15 sub-domain knowledge graphs (or knowledge graph modules) that are interrelated, including the knowledge graph for traditional Chinese medicine health preservation, clinical knowledge graph, traditional Chinese medicine knowledge graph, knowledge graph for famous doctors’ inheritance, and knowledge graph for traditional Chinese medicine characteristic therapies.
The spleen and stomach disease knowledge graph and related literature and knowledge resources have been published in the traditional Chinese medicine professional knowledge service system.
-
Providing authoritative clinical knowledge of spleen and stomach diseases in traditional Chinese medicine,
-
Realizing specialized knowledge retrieval, literature retrieval, and knowledge graph services.
-
The “Traditional Chinese Medicine Professional Knowledge Service System” is a project initiated by the Chinese Academy of Engineering in conjunction with the Chinese Academy of Traditional Chinese Medicine’s Institute of Traditional Chinese Medicine Information, focusing on the national guidance to “leverage the unique advantages of traditional Chinese medicine.”
-
The Institute of Traditional Chinese Medicine Information at the Chinese Academy of Traditional Chinese Medicine focuses on knowledge service.
-
Since 2019, it has taken three years to build and improve, officially launching in early 2022 and being incorporated into the resource system of the China Engineering Science and Technology Knowledge Center.
This system aggregates 25 categories of high-quality traditional Chinese medicine data resources, including prescriptions, famous doctors, health preservation, clinical practices, terminology, etc., and integrates unique knowledge applications such as ancient and modern medical cases, clinical assistance, knowledge graphs, etc. Additionally, a special research module for academicians has been developed to comprehensively and multidimensionally showcase traditional Chinese medicine knowledge, meeting the needs of academicians, engineering and technology personnel, traditional Chinese medicine workers, and the general public for traditional Chinese medicine knowledge, making it a rare practical research tool in traditional Chinese medicine.
[Free Registration for Use]After successful registration, users can bind their registered accounts with their WeChat or QQ accounts for quick login next time.

The Traditional Chinese Medicine Professional Knowledge Service System focuses on aggregating professional and authoritative characteristic data resources. Data sources include journal literature, newspapers, clinical medical cases, industry standards, and books. For some high-value internet resources, the construction team conducts expert quality control to ensure the authenticity and reliability of the data resources.
-
Policy regulations, standards, scientific literature, ancient texts, and other literature resources; -
Basic data resources for diseases, treatment methods, prescriptions, traditional Chinese medicines and their chemical components, health preservation, etc.; -
Knowledge bases for specialized diseases, famous case studies, characteristic treatment methods, knowledge graphs, intelligent Q&A knowledge bases, and other characteristic data resources.
By continuously increasing the types of industry data resources and expanding the scale of industry data resources, we aim to build an authoritative and high-end traditional Chinese medicine think tank.
Taking spleen and stomach diseases as an example, we have established clinical knowledge bases for functional gastrointestinal diseases, chronic gastritis, etc., through the collection and organization of traditional Chinese medicine literature and further knowledge processing, organizing and managing clinical knowledge contained in the vast literature of ancient and modern times, encoding and digitizing it, transforming it from a chaotic state into an orderly one, facilitating retrieval and accelerating the flow and exchange of clinical knowledge.
The entire knowledge base includes 14 sub-libraries such as ontology, journal literature, English literature, ancient literature, popular science literature, clinical research, systematic reviews, treatment guidelines, medical cases, prescriptions, traditional Chinese medicines, famous traditional Chinese medicine practitioners, and health preservation methods.
-
Perform precise knowledge queries and knowledge retrieval using Cypher language in Neo4j database. -
Visualize the knowledge system to help traditional Chinese medicine researchers sort out the knowledge system and development lineage of traditional Chinese medicine, assisting in the inheritance of traditional Chinese medicine. -
Support knowledge Q&A, knowledge retrieval, intelligent recommendation, and other specialized knowledge services for spleen and stomach diseases.
In summary, to address the issues of vast literature, dispersed knowledge, and inconvenient access in the field of traditional Chinese medicine spleen and stomach disease research, we constructed a spleen and stomach disease knowledge graph system based on previous literature research and data foundations, employing a combination of manual editing and automatic construction methods to extract, transform, and integrate knowledge, obtaining entities, attributes, and relationships.
This knowledge graph mainly includes six types of entity types: diseases, traditional Chinese medicines, prescriptions, symptoms, health preservation methods, and five types of relationships: treatment, inclusion, and related health preservation methods. The Neo4j graph database is used for knowledge graph data storage and querying.
The spleen and stomach disease knowledge graph has been published on the traditional Chinese medicine professional knowledge service system, achieving specialized knowledge services for spleen and stomach diseases, with over 1,000 clinical doctor users, establishing an industry-wide co-construction and sharing service model, promoting academic development and improving therapeutic efficacy.